RL – DQN Deep Q-network

Kunnen computers videospellen spelen als een mens? In 2015 versloeg DQN menselijke experts in veel Atari-spellen. Maar als het aankomt op complexe oorlogsstrategiegames, doet AI het niet goed. In 2017 versloeg een professioneel team met gemak een AI-programma van DeepMind in Starcraft 2.
Zoals geciteerd uit de DeepMind-paper:
Het is een multi-agentprobleem met meerdere spelers die op elkaar inwerken; er is onvolmaakte informatie vanwege een gedeeltelijk waargenomen kaart; het heeft een grote actieruimte waarbij honderden eenheden moeten worden geselecteerd en bestuurd; het heeft een grote toestandsruimte die uitsluitend moet worden waargenomen op basis van ruwe invoerfunctievlakken; en het heeft vertraagde krediettoewijzing die langetermijnstrategieën over duizenden stappen vereist.
Laten we onze reis hervatten naar het Deep Q-Network DQN. In het onderstaande spel Seaquest leert DQN uit zichzelf hoe je scores kunt lezen, op de vijand kunt schieten en duikers kunt redden uit de ruwe beelden. Het ontdekt ook kennis die we als strategie kunnen aanduiden, zoals wanneer de onderzeeër naar de oppervlakte moet worden gebracht voor zuurstof.

Q-learning leert de actie-waarde functie Q(s, a): hoe goed is het om een actie te ondernemen bij een bepaalde toestand. Bijvoorbeeld, voor de onderstaande bordpositie, hoe goed het is om de pion twee stappen vooruit te zetten. Letterlijk gesproken kennen we een scalaire waarde toe aan het voordeel van zo’n zet.
Q wordt de actie-waarde functie (of Q-waarde functie in dit artikel) genoemd.

In Q-learning bouwen we een geheugentabel Q op om Q-waarden op te slaan voor alle mogelijke combinaties van s en a. Als u een schaker bent, is dit het schaakblad voor de beste zet. In het voorbeeld hierboven kunnen we ons realiseren dat de pion 2 stappen vooruit zetten de hoogste Q-waarden heeft boven alle andere. (Het geheugengebruik zal te hoog zijn voor het schaakspel. Maar laten we nog even bij deze aanpak blijven.)
Technisch gesproken, bemonsteren we een actie uit de huidige toestand. We achterhalen de beloning R (indien aanwezig) en de nieuwe toestand s’ (de nieuwe bordpositie). Uit de geheugentabel bepalen we de volgende actie a’ die de maximale Q(s’, a’) heeft.
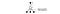
In een videospelletje scoren we punten (beloningen) door de vijand neer te schieten. In een schaakspel is de beloning +1 als we winnen of -1 als we verliezen. Er wordt dus maar één beloning gegeven en het duurt even voordat we die krijgen.
Q-learning gaat over het maken van het schaakblad Q.

We kunnen een enkele zet a nemen en kijken welke beloning R we kunnen krijgen. Dit creëert een één-staps vooruitblik. R + Q(s’, a’) wordt het doel dat we willen dat Q(s, a) is. Bijvoorbeeld, stel dat alle Q waarden nu gelijk zijn aan één. Als we de joystick naar rechts bewegen en 2 punten scoren, willen we Q(s, a) dichter bij 3 brengen (dus 2 + 1).

Naarmate we verder spelen, houden we een lopend gemiddelde voor Q aan. De waarden zullen beter worden en met wat trucjes zullen de Q-waarden convergeren.
Q-learning algoritme
Het volgende is het algoritme om Q aan te passen aan de bemonsterde beloningen. Als γ (kortingsfactor) kleiner is dan één, is de kans groot dat Q convergeert.

Als de combinaties van toestanden en acties echter te groot zijn, zullen het geheugen en de berekeningsvereisten voor Q te hoog zijn. Om dat te verhelpen, schakelen we over op een diep netwerk Q (DQN) om Q(s, a) te benaderen. Het leeralgoritme wordt Deep Q-learning genoemd. Met de nieuwe aanpak veralgemenen we de benadering van de Q-waardefunctie in plaats van de oplossingen te onthouden.
Welke uitdagingen ondervindt RL in vergelijking met DL?
In supervised learning willen we dat de input i.i.d. (onafhankelijk en identiek verdeeld) is, d.w.z.
- Samples worden gerandomiseerd over batches en daarom heeft elke batch dezelfde (of vergelijkbare) datadistributie.
- Stalen zijn onafhankelijk van elkaar in dezelfde batch.
In het andere geval kan het model voor sommige klassen (of groepen) van stalen op verschillende tijdstippen overgefitted zijn en zal de oplossing niet gegeneraliseerd zijn.
Voor dezelfde input verandert het label bovendien niet in de tijd. Dit soort stabiele voorwaarden voor de invoer en de uitvoer biedt de voorwaarde voor het supervisieleren om goed te presteren.
In versterkingsleren veranderen zowel de invoer als het doel voortdurend tijdens het proces en maken de training instabiel.
Target instabiel: We bouwen een diep netwerk om de waarden van Q te leren, maar de doelwaarden veranderen naarmate we dingen beter weten. Zoals hieronder te zien is, hangen de doelwaarden voor Q af van Q zelf, we jagen een niet-stationair doel na.

i.i.d.: Er is nog een probleem dat te maken heeft met de correlaties binnen een traject. Binnen een trainingsiteratie werken we modelparameters bij om Q(s, a) dichter bij de grondwaarheid te brengen. Deze updates zullen andere schattingen beïnvloeden. Wanneer we de Q-waarden in het diepe netwerk omhoog trekken, worden de Q-waarden in de omringende toestanden ook omhoog getrokken, als een net.

Laten we zeggen dat we zojuist een beloning hebben gescoord en het Q-netwerk hebben aangepast om dit weer te geven. Vervolgens doen we een andere zet. De nieuwe toestand zal er ongeveer hetzelfde uitzien als de vorige, vooral als we ruwe afbeeldingen gebruiken om toestanden weer te geven. De nieuw opgehaalde Q(s’, a’) zal hoger zijn en ons nieuwe doel voor Q zal ook hoger zijn, ongeacht de verdienste van de nieuwe actie. Als we het netwerk updaten met een opeenvolging van acties in hetzelfde traject, vergroot dit het effect voorbij onze bedoeling. Dit destabiliseert het leerproces en klinkt als honden die achter hun staart aanzitten.
Wat is de fundamentele uitdaging bij het trainen van RL? In RL zijn we vaak afhankelijk van het beleid of waardefuncties om acties te bemonsteren. Dit verandert echter regelmatig naarmate we beter weten wat we moeten onderzoeken. Naarmate we het spel uitspelen, weten we beter over de grondwaarheidswaarden van toestanden en acties. Dus onze doeloutputs veranderen ook. Nu proberen we een mapping f te leren voor een voortdurend veranderende input en output!
Luckily, both input and output can converge. Dus als we de veranderingen in zowel input als output voldoende vertragen, hebben we misschien een kans om f te modelleren terwijl we het laten evolueren.
Oplossingen
Ervaringsherhaling: We stoppen bijvoorbeeld de laatste miljoen overgangen (of videoframes) in een buffer en bemonsteren een minipartij van monsters van grootte 32 uit deze buffer om het diepe netwerk te trainen. Dit vormt een input dataset die stabiel genoeg is om te trainen. Omdat we willekeurig monsters nemen uit de replay buffer, zijn de gegevens onafhankelijker van elkaar en dichter bij i.i.d.
Doelnetwerk: We creëren twee diepe netwerken θ- en θ. We gebruiken de eerste om Q-waarden op te halen, terwijl de tweede alle updates in de training meeneemt. Na zeg 100.000 updates synchroniseren we θ- met θ. Het doel is om de Q-waardedoelen tijdelijk vast te zetten, zodat we geen bewegend doel hebben om na te jagen. Bovendien hebben parameterwijzigingen niet onmiddellijk effect op θ- en daarom zal zelfs de invoer misschien niet 100% i.i.d. zijn, zal het effect ervan niet ten onrechte worden vergroot, zoals eerder is vermeld.

Met zowel experience replay als het doelnetwerk hebben we een stabielere input en output om het netwerk te trainen en gedraagt het zich meer als supervised training.
Experience replay heeft de grootste prestatieverbetering in DQN. De verbetering van het doelnetwerk is aanzienlijk, maar niet zo kritisch als de herhaling. Het wordt echter belangrijker wanneer de capaciteit van het netwerk klein is.
Diep Q-learning met experience replay
Hier volgt het algoritme:
waarbij ϕ de laatste 4 beeldframes voorbewerkt om de toestand weer te geven. Om beweging vast te leggen, gebruiken we vier frames om een toestand weer te geven.
Implementatiedetails
Verliesfunctie
Laten we nog een paar implementatiedetails doornemen om de prestaties te verbeteren. DQN gebruikt Huber verlies (groene curve) waarbij het verlies kwadratisch is voor kleine waarden van a, en lineair voor grote waarden.


De invoering van het Huber-verlies maakt minder dramatische veranderingen mogelijk die de RL vaak schaden.
Optimalisatie
RL training is gevoelig voor optimalisatie methoden. Een eenvoudig leersnelheidsschema is niet dynamisch genoeg om veranderingen in de invoer tijdens de training op te vangen. Veel RL trainingen gebruiken RMSProp of Adam optimizer. DQN wordt getraind met RMSProp. Het gebruik van geavanceerde optimalisatie methode in Policy Gradient methoden is ook zwaar bestudeerd.
ϵ-greedy
DQN gebruikt ϵ-greedy om de eerste actie te selecteren.
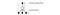
Om de training te verbeteren, begint ϵ bij 1 en gloeit af naar 0.1 of 0,05 over de eerste miljoen frames met behulp van het volgende beleid.

waar m het aantal mogelijke acties is. In het begin van de training selecteren we de mogelijke acties op uniforme wijze, maar naarmate de training vordert, selecteren we vaker de optimale actie a*. Dit maakt maximale exploratie in het begin mogelijk, die uiteindelijk overgaat in exploitatie.
Maar zelfs tijdens het testen kunnen we ϵ op een kleine waarde houden, zoals 0,05. Een deterministisch beleid kan in een lokaal optimum blijven steken. Een niet-deterministisch beleid stelt ons in staat om uit te breken voor een kans om een beter optimum te bereiken.

Architectuur
Hier volgt de DQN-architectuur. We nemen de laatste 4 video frames en voeren deze in convolutionele lagen, gevolgd door volledig verbonden lagen om de Q waarden voor elke actie te berekenen.

In het onderstaande voorbeeld, als we de peddel niet omhoog bewegen in frame 3, zullen we de bal missen. Zoals verwacht van de DQN, is de Q waarde van het omhoog bewegen van de peddel veel hoger in vergelijking met andere acties.


Verbetering van DQN
Vele verbeteringen zijn aangebracht in DQN. In dit gedeelte laten we enkele methoden zien die significante verbeteringen laten zien.
Double DQN
In Q-learning gebruiken we de volgende formule voor de streefwaarde voor Q.

De max-operatie veroorzaakt echter een positieve vertekening van de Q-schattingen.

Van het bovenstaande voorbeeld zien we dat max Q(s, a) hoger is dan de geconvergeerde waarde 1.0. D.w.z. de max operatie overschat Q. Door theorie en experimenten, verbetert de DQN prestatie als we het online netwerk θ gebruiken om greedy de actie te selecteren en het doelnetwerk θ- om de Q waarde te schatten.

Priorized Experience Replay
DQN bemonstert de overgangen uit de replay buffer op uniforme wijze. We moeten echter minder aandacht besteden aan monsters die al dicht bij het doel liggen. We moeten monsters nemen van overgangen die een groot doelgat hebben:

Daarom kunnen we overgangen uit de buffer
- selecteren op basis van de bovenstaande foutwaarde (kies vaker overgangen met een hogere foutwaarde), of
- ze rangschikken op basis van de foutwaarde en ze volgens rang selecteren (kies vaker degene met een hogere rangorde).
Voor details over de vergelijkingen op sampling data, zie de Prioritized Experience Replay paper.
Dueling DQN
In Dueling DQN, wordt Q berekend met een andere formule hieronder met waardefunctie V en een toestandsafhankelijke actievoordeelfunctie A hieronder:

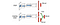
In plaats van Q te leren, gebruiken we twee afzonderlijke koppen om V en A te berekenen. Uit empirische experimenten blijkt dat de prestaties verbeteren. DQN werkt de Q-waardefunctie van een toestand alleen bij voor een specifieke actie. Dueling DQN werkt V bij, waar andere Q(s, a’) updates ook van kunnen profiteren. Dus elke Dueling DQN training iteratie wordt verondersteld een grotere impact te hebben.
Noisey Nets for Exploration
DQN gebruikt ϵ-greedy om acties te selecteren. NoisyNet vervangt het door parametrische ruis toe te voegen aan de lineaire laag om exploratie te helpen. In NoisyNet wordt ε-greedy niet gebruikt. Het gebruikt een greedy-methode om acties te selecteren uit de Q-waarde functie. Maar voor de volledig aangesloten lagen van de Q-benaderaar voegen we hieronder trainbare geparametriseerde ruis toe om acties te verkennen. Het toevoegen van ruis aan een diep netwerk is vaak gelijkwaardig of beter dan het toevoegen van ruis aan een actie zoals in de ϵ-greedy methode.

Meer gedachten
DQN behoort tot een belangrijke klasse van RL, namelijk value-learning. In de praktijk combineren we vaak policy gradients met value-learning methoden bij het oplossen van real-life problemen.
Leave a Reply