RL – DQN Deep Q-network

Kykenevätkö tietokoneet pelaamaan videopelejä kuten ihminen? Vuonna 2015 DQN päihitti ihmisasiantuntijat monissa Atari-peleissä. Mutta kun tulee monimutkaisia sotastrategiapelejä, tekoäly ei pärjää hyvin. Vuonna 2017 ammattilaisjoukkue voitti DeepMindin tekoälyohjelman Starcraft 2:ssa helposti.
Kuten DeepMindin paperista lainataan:
Se on moniagenttiongelma, jossa useat pelaajat ovat vuorovaikutuksessa keskenään; informaatio on epätäydellistä osittain havainnoidun kartan vuoksi; siinä on suuri toiminta-avaruus, johon liittyy satojen yksiköiden valinta ja hallinta; siinä on suuri tila-avaruus, jota on havainnoitava pelkästään raa’an syötteen ominaisuustasoista; ja siinä on viivästynyt luotonanto, joka vaatii pitkäaikaisia strategioita tuhansien askeleiden ajan.
Aloitetaanpa matkamme takaisin Deep Q-Network DQN:ään. Alla olevassa Seaquest-pelissä DQN oppii itsestään lukemaan pisteet, ampumaan vihollisen ja pelastamaan sukeltajat raakakuvista. Se löytää myös tietoa, jota voimme kutsua strategiaksi, kuten milloin sukellusvene kannattaa tuoda pintaan hakemaan happea.

Q-oppimisella opitaan toiminta-arvofunktio Q(s, a): kuinka hyvä on tehdä jokin toiminta tietyssä tilassa. Esimerkiksi alla olevassa laudan asennossa, kuinka hyvä on siirtää sotilasta kaksi askelta eteenpäin. Kirjaimellisesti annamme skalaarisen arvon tällaisen siirron tekemisen hyödylle.
Q:ta kutsutaan toiminta-arvofunktioksi (tai tässä artikkelissa Q-arvofunktioksi).

Q-oppimisessa rakennamme muistitaulukon Q, johon tallennamme Q-arvot kaikille mahdollisille s:n ja a:n kombinaatioille. Jos olet shakinpelaaja, se on parhaan siirron huijauslista. Yllä olevassa esimerkissä saatamme huomata, että siirtämällä sotilasta 2 askelta eteenpäin on korkeimmat Q-arvot kaikkiin muihin nähden. (Muistin kulutus on liian suuri shakkipelin kannalta. Mutta pitäydytään tässä lähestymistavassa vielä vähän aikaa.)
Teknisesti ottaen otamme näytteen toiminnosta nykyisestä tilasta. Selvitämme palkkion R (jos sellainen on) ja uuden tilan s’ (uusi laudan sijainti). Muistitaulukosta määrittelemme seuraavan suoritettavan toiminnon a’, jolla on suurin Q(s’, a’).
Videopelissä saamme pisteitä (palkkioita) ampumalla vihollisen alas. Shakkipelissä palkkio on +1, kun voitamme tai -1, jos häviämme. Tämä luo yhden askeleen katseen eteenpäin. R + Q(s’, a’) tulee kohteeksi, jonka haluamme Q(s, a):n olevan. Sanotaan esimerkiksi, että kaikki Q:n arvot ovat nyt yhtä suuret kuin yksi. Jos liikutamme joystickiä oikealle ja saamme 2 pistettä, haluamme siirtää Q(s, a) lähemmäs 3 (eli 2 + 1).

Jatkamalla pelaamista ylläpidämme juoksevaa keskiarvoa Q:lle. Arvot paranevat ja joidenkin temppujen avulla Q:n arvot konvergoituvat.
Q-oppimisalgoritmi
Seuraavassa on algoritmi Q:n sovittamiseksi näytteistettyihin palkintoihin. Jos γ (diskonttauskerroin) on pienempi kuin yksi, on hyvä mahdollisuus, että Q konvergoi.

Jos kuitenkin tilojen ja toimintojen kombinaatiot ovat liian suuria, Q:n muistin ja laskennan vaatimus nousee liikaa. Tämän ratkaisemiseksi siirrymme syväverkkoon Q (DQN) approksimoimaan Q(s, a). Oppimisalgoritmia kutsutaan Deep Q-learningiksi. Uudella lähestymistavalla yleistämme Q-arvofunktion approksimointia sen sijaan, että muistaisimme ratkaisut.
Mitä haasteita RL:llä on DL:ään verrattuna?
Valvotussa oppimisessa haluamme syötteen olevan i.i.d. (independent and identically distributed), eli
- Näytteet satunnaistetaan erien kesken, joten jokaisella erällä on sama (tai samankaltainen) datan jakautuminen.
- Näytteet ovat riippumattomia toisistaan samassa erässä.
Jos näin ei ole, malli voi olla ylisovitettu jollekin näyteluokalle (tai -ryhmille) eri aikaan ja ratkaisu ei ole yleistettävissä.
Samalle syötteelle sen etiketti ei lisäksi muutu ajan kuluessa. Tällainen vakaa tila syötteelle ja tuotokselle tarjoaa edellytykset sille, että valvottu oppiminen toimii hyvin.
Vahvistusoppimisessa sekä syöte että kohde muuttuvat jatkuvasti prosessin aikana ja tekevät harjoittelusta epävakaata.
Kohde epävakaa: Rakennamme syvän verkon oppimaan Q:n arvoja, mutta sen tavoitearvot muuttuvat, kun tiedämme asioita paremmin. Koulutusiteraation sisällä päivitämme malliparametreja siirtääksemme Q(s, a) lähemmäs perustotuutta. Nämä päivitykset vaikuttavat muihin estimointeihin. Kun vedämme Q-arvoja ylöspäin syväverkossa, myös ympäröivien tilojen Q-arvot vedetään ylöspäin verkon tavoin.

Esitettäköön, että saimme juuri palkinnon ja muokkaamme Q-verkkoa sen mukaisesti. Seuraavaksi teemme toisen siirron. Uusi tila näyttää samankaltaiselta kuin edellinen erityisesti, jos käytämme raakakuvia tilojen esittämiseen. Äskettäin haettu Q(s’, a’) on korkeampi ja uusi tavoitteemme Q:lle siirtyy myös korkeammalle riippumatta uuden toiminnan ansiosta. Jos päivitämme verkkoa samassa liikeradassa olevalla toimintasarjalla, se suurentaa vaikutusta yli tarkoituksemme. Tämä horjuttaa oppimisprosessia ja kuulostaa siltä, että koirat jahtaavat häntäänsä.
Mikä on RL:n harjoittelun perushaaste? RL:ssä olemme usein riippuvaisia toimintaperiaatteista tai arvofunktioista, kun otamme näytteitä toimista. Tämä kuitenkin muuttuu usein, kun tiedämme paremmin, mitä tutkia. Kun pelaamme peliä, tiedämme paremmin tilojen ja toimintojen perustotuusarvot. Niinpä myös tavoitetuotoksemme muuttuvat. Nyt yritämme oppia kartoituksen f jatkuvasti muuttuville syötteille ja tuotoksille!
Onneksi sekä syötteet että tuotokset voivat konvergoitua. Jos siis hidastamme sekä syötteen että tuotoksen muutoksia tarpeeksi, meillä voi olla mahdollisuus mallintaa f samalla kun annamme sen kehittyä.
Ratkaisut
Kokemuksen toistaminen: Laitamme esimerkiksi viimeiset miljoona siirtymää (tai videokehystä) puskuriin ja otamme tästä puskurista minierän näytteitä, joiden koko on 32, syväverkon kouluttamista varten. Näin muodostuu syötetietoaineisto, joka on riittävän vakaa harjoittelua varten. Koska otamme satunnaisnäytteen toistopuskurista, data on riippumattomampaa toisistaan ja lähempänä i.i.d.
Kohdeverkko: Luomme kaksi syvää verkkoa θ- ja θ. Käytämme ensimmäistä Q-arvojen hakemiseen, kun taas toinen sisältää kaikki päivitykset koulutuksessa. Sanotaan, että 100 000 päivityksen jälkeen synkronoimme θ-:n ja θ:n. Tarkoituksena on kiinnittää Q-arvokohteet väliaikaisesti, jotta meillä ei ole liikkuvaa kohdetta jahdattavana. Lisäksi parametrimuutokset eivät vaikuta θ-:een välittömästi, ja siksi edes syötteet eivät välttämättä ole 100-prosenttisesti i.i.d., se ei virheellisesti suurenna vaikutustaan kuten aiemmin mainittiin.

Kokemusten toistolla ja tavoiteverkolla meillä on vakaampi tulo ja lähtö verkon harjoitteluun, ja se käyttäytyy enemmän valvotun harjoittelun tapaan.
Kokemusten toistolla saavutetaan suurin suorituskykyparannus DQN:ssä. Kohdeverkon parannus on merkittävä, mutta ei yhtä kriittinen kuin toisto. Mutta se muuttuu tärkeämmäksi, kun verkon kapasiteetti on pieni.
Deep Q-learning with experience replay
Tässä on algoritmi:

jossa ϕ esiprosessoidaan viimeiset 4 kuvakehystä, jotka edustavat tilaa. Liikkeen tallentamiseen käytämme neljää kuvaruutua edustamaan tilaa.
Toteutuksen yksityiskohdat
Häviöfunktio
Käsitellään vielä muutamia toteutuksen yksityiskohtia suorituskyvyn parantamiseksi. DQN käyttää Huberin häviötä (vihreä käyrä), jossa häviö on kvadraattinen pienille a:n arvoille ja lineaarinen suurille arvoille.


Huber-häviön käyttöönotto mahdollistaa vähemmän dramaattiset muutokset, jotka usein satuttavat RL:ää.
Optimointi
RL-koulutus on herkkä optimointimenetelmille. Yksinkertainen oppimisnopeuden aikataulu ei ole tarpeeksi dynaaminen käsittelemään syötteen muutoksia koulutuksen aikana. Monet RL-koulutukset käyttävät RMSProp- tai Adam-optimoijaa. DQN koulutetaan RMSProp:lla. Ennakkooptimointimenetelmän käyttämistä Policy Gradient -menetelmissä tutkitaan myös paljon.
ϵ-greedy
DQN käyttää ϵ-greedyä ensimmäisen toiminnan valitsemiseen.
Koulutuksen parantamiseksi ϵ aloitetaan 1:stä ja hehkutetaan 0:aan.1 tai 0,05 ensimmäisen miljoonan ruudun aikana käyttäen seuraavaa käytäntöä.

jossa m on mahdollisten toimintojen lukumäärä. Harjoittelun alussa valitsemme mahdolliset toiminnot tasaisesti, mutta harjoittelun edetessä valitsemme yhä useammin optimaalisen toiminnon a*. Tämä mahdollistaa alussa maksimaalisen eksploraation, joka lopulta siirtyy hyödyntämiseen.
Mutta myös testauksen aikana voimme pitää ϵ:n pienenä arvona, kuten 0,05. Deterministinen politiikka voi juuttua paikalliseen optimiin. Epädeterministinen politiikka antaa meille mahdollisuuden murtautua ulos, jotta voimme päästä parempaan optimiin.

Arkkitehtuuri
Tässä on DQN:n rakenne. Otamme 4 viimeistä edellistä videokuvaa ja syötämme ne konvoluutiokerroksiin, joita seuraavat täysin kytketyt kerrokset laskevat Q-arvot kullekin toiminnolle.

>
Oheisen kuvan mukaisessa esimerkeissä, jos emme liikuta melaa ylöspäin kehyksessä numero 3, emme saa palloa. Kuten DQN:n perusteella on odotettavissa, melan ylöspäin siirtämisen Q-arvo on paljon suurempi verrattuna muihin toimintoihin.


Parannukset DQN:iin
Monia parannuksia DQN:iin on tehty. Tässä luvussa esitellään joitakin menetelmiä, jotka osoittavat merkittäviä parannuksia.
Double DQN
Q-oppimisessa käytetään seuraavaa kaavaa Q:n tavoitearvolle.

Yllä olevasta esimerkistä nähdään, että max Q(s, a) on suurempi kuin konvergoitu arvo 1.0. Toisin sanoen max-operaatio yliarvioi Q:n. Teorian ja kokeiden perusteella DQN:n suorituskyky paranee, jos käytämme online-verkkoa θ ahneeseen toiminnan valintaan ja kohdeverkkoa θ- Q:n arvon estimointiin.

Priorisoitu kokemusten uusinta
DQN poimii siirtymät uusintapuskurista tasaisesti. Meidän tulisi kuitenkin kiinnittää vähemmän huomiota näytteisiin, jotka ovat jo lähellä kohdetta. Meidän pitäisi ottaa näytteitä siirtymistä, joilla on suuri tavoite-ero:

Voidaan siis valita puskurista siirtymiä
- yllä olevan virhearvon perusteella (poimitaan siirtymiä, joiden virhe on suurempi, useammin) tai
- järjestetään siirtymiä niiden arvojärjestykseen virhearvon mukaan ja poimitaan siirtymiä järjestyksen mukaan (poimitaan siirtymiä, joilla on korkeampi virhejärjestys useammin).
Tietoa otosdataa koskevista yhtälöistä on Prioritized Experience Replay -asiakirjassa.
Dueling DQN
Dueling DQN:ssä Q lasketaan alla olevalla eri kaavalla, jossa on arvofunktio V ja tilasta riippuvainen toimintaetufunktio A alla:

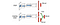
Q:n oppimisen sijaan käytämme kahta erillistä päätä V:n ja A:n laskemiseen. Empiiriset kokeet osoittavat, että suorituskyky paranee. DQN päivittää tilan Q-arvofunktion vain tietyn toiminnan osalta. Dueling DQN päivittää V:n, jota muut Q(s, a’) -päivitykset voivat myös hyödyntää. Niinpä jokaisella Dueling DQN -koulutusiteraatiolla ajatellaan olevan suurempi vaikutus.
Noisy Nets for Exploration
DQN käyttää ϵ-greedyä toimintojen valintaan. Vaihtoehtoisesti NoisyNet korvaa sen lisäämällä lineaariseen kerrokseen parametrista kohinaa tutkimisen helpottamiseksi. NoisyNetissä ε-greedyä ei käytetä. Se käyttää ahnetta menetelmää toimintojen valitsemiseen Q-arvofunktiosta. Mutta Q-approksimaattorin täysin kytkettyihin kerroksiin lisätään koulutettavissa olevaa parametrisoitua kohinaa alapuolelle toimintojen tutkimista varten. Kohinan lisääminen syväverkkoon on usein vastaavaa tai parempaa kuin ϵ-greedy-menetelmän kaltaisen kohinan lisääminen toimintaan.

Lisäpohdintoja
DQN:llä kuuluu erääseen tärkeään luokkaan RL:ssä, nimittäin arvo-opiskeluun. Käytännössä yhdistämme usein politiikkagradientteja ja arvo-oppimismenetelmiä ratkaistessamme tosielämän ongelmia.
Leave a Reply