RL – DQN Deep Q-network

Les ordinateurs peuvent-ils jouer aux jeux vidéo comme un humain ? En 2015, DQN a battu des experts humains dans de nombreux jeux Atari. Mais dès qu’il s’agit de jeux de stratégie de guerre complexes, l’IA ne s’en sort pas bien. En 2017, une équipe professionnelle a battu facilement un programme d’IA DeepMind dans Starcraft 2.
Cités dans le document de DeepMind :
Il s’agit d’un problème multi-agents avec plusieurs joueurs qui interagissent ; il y a des informations imparfaites en raison d’une carte partiellement observée ; il a un grand espace d’action impliquant la sélection et le contrôle de centaines d’unités ; il a un grand espace d’état qui doit être observé uniquement à partir de plans de caractéristiques d’entrée brutes ; et il a une attribution de crédit retardée nécessitant des stratégies à long terme sur des milliers d’étapes.
Reprenons notre voyage vers le réseau Q profond DQN. Dans le jeu Seaquest ci-dessous, DQN apprend à lire les scores, à tirer sur l’ennemi et à sauver les plongeurs à partir des images brutes, tout seul. Il découvre également des connaissances que l’on peut qualifier de stratégie, comme par exemple, quand faire remonter le sous-marin à la surface pour avoir de l’oxygène.

L’apprentissage Q apprend la fonction action-valeur Q(s, a) : à quel point il est bon d’entreprendre une action à un état particulier. Par exemple, pour la position de l’échiquier ci-dessous, il s’agit de savoir s’il est bon de déplacer le pion de deux pas en avant. Littéralement, nous attribuons une valeur scalaire sur l’avantage de faire un tel mouvement.
Q est appelée la fonction action-valeur (ou fonction Q-valeur dans cet article).

Dans le Q-learning, nous construisons une table de mémoire Q pour stocker les valeurs Q pour toutes les combinaisons possibles de s et a. Si vous êtes un joueur d’échecs, c’est l’antisèche pour le meilleur coup. Dans l’exemple ci-dessus, nous pouvons nous rendre compte que déplacer le pion 2 pas en avant a les valeurs Q les plus élevées parmi toutes les autres. (La consommation de mémoire sera trop élevée pour le jeu d’échecs. Mais restons avec cette approche un peu plus longtemps.)
Techniquement parlant, nous échantillonnons une action à partir de l’état actuel. Nous découvrons la récompense R (si elle existe) et le nouvel état s’ (la nouvelle position sur l’échiquier). A partir de la table de mémoire, on détermine l’action suivante a’ à prendre qui a le maximum de Q(s’, a’).
Dans un jeu vidéo, on marque des points (récompenses) en abattant l’ennemi. Dans une partie d’échecs, la récompense est de +1 quand on gagne ou de -1 si on perd. Il n’y a donc qu’une seule récompense donnée et il faut un certain temps pour l’obtenir.
Le Q-learning consiste à créer l’antisèche Q.

Nous pouvons prendre un seul coup a et voir quelle récompense R nous pouvons obtenir. Cela crée une anticipation d’une étape. R + Q(s’, a’) devient la cible que nous voulons que Q(s, a) soit. Par exemple, disons que toutes les valeurs de Q sont égales à un maintenant. Si nous déplaçons le joystick vers la droite et marquons 2 points, nous voulons rapprocher Q(s, a) de 3 (c’est-à-dire 2 + 1).

A mesure que nous continuons à jouer, nous maintenons une moyenne courante pour Q. Les valeurs s’amélioreront et avec quelques astuces, les valeurs de Q convergeront.
Algorithme d’apprentissage de Q
Voici l’algorithme pour ajuster Q avec les récompenses échantillonnées. Si γ (facteur d’escompte) est inférieur à un, il y a de bonnes chances que Q converge.

Cependant, si les combinaisons d’états et d’actions sont trop grandes, la mémoire et le besoin de calcul pour Q seront trop élevés. Pour remédier à cela, nous passons à un réseau profond Q (DQN) pour approximer Q(s, a). L’algorithme d’apprentissage est appelé Deep Q-learning. Avec la nouvelle approche, nous généralisons l’approximation de la fonction de valeur Q plutôt que de nous souvenir des solutions.
Quels sont les défis auxquels RL fait face par rapport à DL ?
Dans l’apprentissage supervisé, nous voulons que l’entrée soit i.i.d. (indépendante et identiquement distribuée), c’est-à-dire que
- Les échantillons sont randomisés parmi les lots et donc chaque lot a la même distribution de données (ou similaire).
- Les échantillons sont indépendants les uns des autres dans le même lot.
Sinon, le modèle peut être surajusté pour une certaine classe (ou groupes) d’échantillons à différents moments et la solution ne sera pas généralisée.
En outre, pour la même entrée, son étiquette ne change pas au fil du temps. Ce type de condition stable pour l’entrée et la sortie fournit la condition pour que l’apprentissage supervisé soit performant.
Dans l’apprentissage par renforcement, l’entrée et la cible changent constamment pendant le processus et rendent la formation instable.
Cible instable : Nous construisons un réseau profond pour apprendre les valeurs de Q mais ses valeurs cibles changent à mesure que nous connaissons mieux les choses. Comme indiqué ci-dessous, les valeurs cibles de Q dépendent de Q lui-même, nous poursuivons une cible non stationnaire.

i.i.d. : Il existe un autre problème lié aux corrélations au sein d’une trajectoire. Dans une itération d’apprentissage, nous mettons à jour les paramètres du modèle pour rapprocher Q(s, a) de la vérité terrain. Ces mises à jour auront un impact sur les autres estimations. Lorsque nous tirons vers le haut les valeurs de Q dans le réseau profond, les valeurs de Q dans les états environnants seront également tirées vers le haut comme un réseau.

Disons que nous venons de marquer une récompense et d’ajuster le réseau Q pour le refléter. Ensuite, nous effectuons un autre déplacement. Le nouvel état ressemblera au précédent, en particulier si nous utilisons des images brutes pour représenter les états. Le nouveau Q(s’, a’) récupéré sera plus élevé et notre nouvelle cible pour Q sera également plus élevée, indépendamment du mérite de la nouvelle action. Si nous mettons à jour le réseau avec une séquence d’actions dans la même trajectoire, cela amplifie l’effet au-delà de notre intention. Cela déstabilise le processus d’apprentissage et ressemble à des chiens qui courent après leur queue.
Quel est le défi fondamental dans la formation RL ? En RL, nous dépendons souvent de la politique ou des fonctions de valeur pour échantillonner les actions. Cependant, cela change fréquemment car nous savons mieux ce qu’il faut explorer. Au fur et à mesure que nous jouons le jeu, nous connaissons mieux les valeurs réelles des états et des actions. Nos sorties cibles changent donc également. Maintenant, nous essayons d’apprendre une cartographie f pour une entrée et une sortie qui changent constamment !
Par chance, l’entrée et la sortie peuvent converger. Donc, si on ralentit suffisamment les changements en entrée et en sortie, on peut avoir une chance de modéliser f tout en lui permettant d’évoluer.
Solutions
Reprise d’expérience : Par exemple, nous mettons le dernier million de transitions (ou d’images vidéo) dans un tampon et nous échantillonnons un mini-batch d’échantillons de taille 32 à partir de ce tampon pour entraîner le réseau profond. Cela forme un ensemble de données d’entrée qui est suffisamment stable pour l’entraînement. Comme nous échantillonnons aléatoirement à partir du tampon de relecture, les données sont plus indépendantes les unes des autres et plus proches de l’i.i.d.
Réseau cible : Nous créons deux réseaux profonds θ- et θ. Nous utilisons le premier pour récupérer les valeurs Q tandis que le second inclut toutes les mises à jour dans la formation. Après disons 100 000 mises à jour, nous synchronisons θ- avec θ. Le but est de fixer temporairement les cibles des valeurs Q afin de ne pas avoir une cible mobile à poursuivre. De plus, les changements de paramètres n’ont pas d’impact immédiat sur θ- et donc même si l’entrée n’est pas 100% i.i.d., cela n’amplifiera pas incorrectement son effet comme mentionné précédemment.

Avec le rejeu d’expérience et le réseau cible, nous avons une entrée et une sortie plus stables pour former le réseau et se comporte plus comme une formation supervisée.
Le rejeu d’expérience a la plus grande amélioration de performance dans le DQN. L’amélioration du réseau cible est significative mais pas aussi critique que le replay. Mais elle devient plus importante lorsque la capacité du réseau est faible.
Apprentissage Q profond avec relecture d’expérience
Voici l’algorithme :

où ϕ prétraite les 4 dernières trames d’image pour représenter l’état. Pour capturer le mouvement, nous utilisons quatre images pour représenter un état.
Détails d’implémentation
Fonction de perte
Passons en revue quelques détails d’implémentation supplémentaires pour améliorer les performances. DQN utilise la perte de Huber (courbe verte) où la perte est quadratique pour les petites valeurs de a, et linéaire pour les grandes valeurs.


L’introduction de la perte de Huber permet des changements moins dramatiques qui nuisent souvent à RL.
Optimisation
L’apprentissage du RL est sensible aux méthodes d’optimisation. Un simple programme de taux d’apprentissage n’est pas assez dynamique pour gérer les changements d’entrée pendant l’apprentissage. De nombreuses formations RL utilisent RMSProp ou l’optimiseur Adam. DQN est entraîné avec RMSProp. L’utilisation de la méthode d’optimisation avancée dans les méthodes de gradient de politique est également fortement étudiée.
ϵ-greedy
DQN utilise ϵ-greedy pour sélectionner la première action.
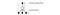
Pour améliorer l’apprentissage, ϵ commence à 1 et recuit à 0.1 ou 0,05 sur le premier million de trames en utilisant la politique suivante.

où m est le nombre d’actions possibles. Au début de l’apprentissage, nous sélectionnons uniformément les actions possibles, mais au fur et à mesure de l’apprentissage, nous sélectionnons l’action optimale a* plus fréquemment. Cela permet une exploration maximale au début qui finit par passer à l’exploitation.
Mais même pendant les tests, nous pouvons maintenir ϵ une petite valeur comme 0,05. Une politique déterministe peut rester bloquée dans un optimum local. Une politique non déterministe nous permet de sortir pour avoir une chance d’atteindre un meilleur optimal.

Architecture
Voici l’architecture DQN. Nous prenons les 4 dernières images vidéo précédentes et les introduisons dans des couches convolutionnelles suivies de couches entièrement connectées pour calculer les valeurs Q pour chaque action.

Dans l’exemple ci-dessous, si nous ne déplaçons pas la pagaie vers le haut à l’image 3, nous manquerons la balle. Comme prévu par le DQN, la valeur Q du déplacement de la pagaie vers le haut est beaucoup plus élevée par rapport aux autres actions.


Améliorations du DQN
De nombreuses améliorations sont apportées au DQN. Dans cette section, nous allons montrer quelques méthodes qui démontrent des améliorations significatives.
Double DQN
Dans l’apprentissage Q, nous utilisons la formule suivante pour la valeur cible de Q.

Cependant, l’opération max crée un biais positif sur les estimations de Q.

D’après l’exemple ci-dessus, nous voyons que max Q(s, a) est supérieur à la valeur convergée 1.0. C’est-à-dire que l’opération max surestime Q. Par la théorie et les expériences, les performances du DQN s’améliorent si nous utilisons le réseau en ligne θ pour sélectionner par gourmandise l’action et le réseau cible θ- pour estimer la valeur Q.

Reprise d’expérience priorisée
DQN échantillonne uniformément les transitions du tampon de reprise. Cependant, nous devrions accorder moins d’attention aux échantillons qui sont déjà proches de la cible. Nous devrions échantillonner les transitions qui ont un grand écart de cible :

Par conséquent, nous pouvons sélectionner les transitions du tampon
- en fonction de la valeur d’erreur ci-dessus (choisir les transitions avec une erreur plus élevée plus fréquemment), ou
- les classer selon la valeur d’erreur et les sélectionner par rang (choisir celle avec un rang plus élevé plus souvent).
Pour plus de détails sur les équations sur les données d’échantillonnage, veuillez vous référer à l’article sur le rejeu d’expérience priorisé.
Dueling DQN
Dans Dueling DQN, Q est calculé avec une formule différente ci-dessous avec la fonction de valeur V et une fonction d’avantage d’action A dépendante de l’état ci-dessous :

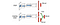
Au lieu d’apprendre Q, nous utilisons deux têtes séparées pour calculer V et A. Des expériences empiriques montrent que les performances s’améliorent. DQN met à jour la fonction de valeur Q d’un état pour une action spécifique seulement. Dueling DQN met à jour V dont les autres mises à jour de Q(s, a’) peuvent également tirer parti. Ainsi, chaque itération de formation de Dueling DQN est pensée pour avoir un impact plus important.
Nets bruyants pour l’exploration
DQN utilise ϵ-greedy pour sélectionner les actions. Alternativement, NoisyNet le remplace en ajoutant du bruit paramétrique à la couche linéaire pour aider l’exploration. Dans NoisyNet, la méthode ε-greedy n’est pas utilisée. Il utilise une méthode gourmande pour sélectionner les actions à partir de la fonction Q-valeur. Mais pour les couches entièrement connectées de l’approximateur Q, nous ajoutons du bruit paramétré entraînable en dessous pour explorer les actions. Ajouter du bruit à un réseau profond est souvent équivalent ou meilleur que d’ajouter du bruit à une action comme celle de la méthode ϵ-greedy.

Plus de pensées
DQN appartient à une classe importante de RL, à savoir l’apprentissage par la valeur. Dans la pratique, nous combinons souvent les gradients de politique avec des méthodes d’apprentissage par la valeur pour résoudre des problèmes de la vie réelle.
Leave a Reply