RL – DQN Deep Q-network

Kan computere spille videospil som mennesker? I 2015 slog DQN menneskelige eksperter i mange Atari-spil. Men når det kommer til komplekse krigsstrategispil, klarer AI sig ikke godt. I 2017 slog et professionelt hold et DeepMind AI-program i Starcraft 2 uden problemer.
Som citeret fra DeepMind-papiret:
Det er et multi-agentproblem med flere spillere, der interagerer; der er ufuldstændig information på grund af et delvist observeret kort; det har et stort handlingsrum, der involverer udvælgelse og kontrol af hundredvis af enheder; det har et stort tilstandsrum, der udelukkende skal observeres ud fra rå inputfunktionsplaner; og det har forsinket kredittildeling, der kræver langsigtede strategier over tusindvis af trin.
Lad os genstarte vores rejse tilbage til Deep Q-Network DQN. I Seaquest-spillet nedenfor lærer DQN helt af sig selv at læse scoringer, skyde fjenden og redde dykkere ud fra de rå billeder. Det opdager også viden, som vi kan betegne som en strategi, f.eks. hvornår ubåden skal bringes op til overfladen for at få ilt.

Q-learning lærer aktionsværdifunktionen Q(s, a): hvor godt det er at foretage en handling ved en bestemt tilstand. For eksempel, for nedenstående brætposition, hvor godt det er at flytte bonden to skridt fremad. Bogstaveligt talt tildeler vi en skalarværdi over for fordelen ved at foretage et sådant træk.
Q kaldes aktions-værdifunktionen (eller Q-værdifunktionen i denne artikel).

I Q-learning opbygger vi en hukommelsestabel Q til at gemme Q-værdier for alle mulige kombinationer af s og a. Hvis du er skakspiller, er det snydekladden for det bedste træk. I eksemplet ovenfor kan vi indse, at det at flytte bonden 2 skridt fremad har de højeste Q-værdier frem for alle andre. (Hukommelsesforbruget vil være for højt for skakspillet. Men lad os holde os til denne fremgangsmåde lidt længere.)
Teknisk set prøver vi en handling ud fra den aktuelle tilstand. Vi finder ud af belønningen R (hvis der er nogen) og den nye tilstand s’ (den nye brætposition). Fra hukommelsestabellen bestemmer vi den næste handling a’, som har den maksimale Q(s’, a’).
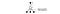
I et videospil scorer vi point (belønninger) ved at skyde fjenden ned. I et skakspil er belønningen +1, når vi vinder, eller -1, hvis vi taber. Der gives altså kun én belønning, og det tager et stykke tid at få den.
Q-læring handler om at skabe snydearket Q.

Vi kan tage et enkelt træk a og se, hvilken belønning R kan vi få. Dette skaber et kig fremad med ét skridt. R + Q(s’, a’) bliver det mål, som vi ønsker, at Q(s, a) skal være. Lad os f.eks. sige, at alle Q-værdier er lig med 1 nu. Hvis vi flytter joysticket til højre og scorer 2 point, ønsker vi at flytte Q(s, a) tættere på 3 (dvs. 2 + 1).

I takt med at vi fortsætter med at spille, opretholder vi et løbende gennemsnit for Q. Værdierne vil blive bedre, og med nogle tricks vil Q-værdierne konvergere.
Q-læringsalgoritme
Det følgende er algoritmen til at tilpasse Q med de udtagne belønninger. Hvis γ (diskonteringsfaktor) er mindre end én, er der en god chance for, at Q konvergerer.

Hvis kombinationer af tilstande og handlinger er for store, vil hukommelsen og beregningskravet til Q imidlertid være for højt. For at løse dette problem skifter vi til et dybt netværk Q (DQN) for at tilnærme Q(s, a) til hinanden. Læringsalgoritmen kaldes Deep Q-learning. Med den nye tilgang generaliserer vi tilnærmelsen af Q-værdifunktionen i stedet for at huske løsningerne.
Hvilke udfordringer står RL over for i forhold til DL?
I overvåget læring ønsker vi, at input skal være i.i.d. (uafhængigt og identisk fordelt), dvs.
- Stikprøverne randomiseres blandt batches, og derfor har hver batch den samme (eller lignende) datafordeling.
- Stikprøverne er uafhængige af hinanden i samme batch.
Hvis det ikke er tilfældet, kan modellen blive overfittet for nogle klasser (eller grupper) af stikprøver på forskellige tidspunkter, og løsningen vil ikke blive generaliseret.
Dertil kommer, at for det samme input ændrer dets label sig ikke over tid. Denne form for stabil tilstand for input og output giver betingelsen for, at den overvågede læring kan fungere godt.
I forstærkende læring ændres både input og mål konstant i løbet af processen og gør træningen ustabil.
Mål ustabilt: Vi opbygger et dybt netværk for at lære værdierne for Q, men dets målværdier ændrer sig, efterhånden som vi får mere viden om tingene. Som vist nedenfor afhænger målværdierne for Q af Q selv, vi jagter et ikke-stationært mål.

i.i.d.: Der er et andet problem i forbindelse med korrelationerne inden for en bane. Inden for en træningsiteration opdaterer vi modelparametre for at flytte Q(s, a) tættere på den grundlæggende sandhed. Disse opdateringer vil påvirke andre vurderinger. Når vi trækker Q-værdierne op i det dybe netværk, vil Q-værdierne i de omkringliggende tilstande også blive trukket op som et net.

Lad os sige, at vi lige har scoret en belønning og justerer Q-netværket for at afspejle det. Dernæst foretager vi endnu et træk. Den nye tilstand vil ligne den sidste, især hvis vi bruger rå billeder til at repræsentere tilstande. Den nyligt hentede Q(s’, a’) vil være højere, og vores nye mål for Q vil også bevæge sig højere uanset fortjenesten ved den nye handling. Hvis vi opdaterer netværket med en sekvens af handlinger i den samme bane, forstørrer det effekten ud over vores hensigt. Dette destabiliserer læringsprocessen og lyder som hunde, der jagter deres haler.
Hvad er den grundlæggende udfordring ved træning af RL? I RL er vi ofte afhængige af politik- eller værdifunktioner til at udtage handlinger. Dette ændrer sig imidlertid ofte, efterhånden som vi ved bedre, hvad vi skal udforske. Efterhånden som vi spiller spillet, ved vi bedre om de grundlæggende sandhedsværdier for tilstande og handlinger. Så vores måloutput ændrer sig også. Nu forsøger vi at lære en kortlægning f for et konstant skiftende input og output!
Gluksomt nok kan både input og output konvergere. Så hvis vi bremser ændringerne i både input og output tilstrækkeligt, har vi måske en chance for at modellere f, samtidig med at vi lader den udvikle sig.
Løsninger
Erfaringsgennemspilning: Vi lægger f.eks. den sidste million overgange (eller videobilleder) i en buffer og prøver en minibatch af prøver af størrelse 32 fra denne buffer for at træne det dybe netværk. Dette danner et inputdatasæt, som er stabilt nok til træning. Da vi udtager tilfældige prøver fra genafspilningsbufferen, er dataene mere uafhængige af hinanden og tættere på i.i.d.
Målnetværket: Vi opretter to dybe netværk θ- og θ. Vi bruger det første til at hente Q-værdier, mens det andet omfatter alle opdateringer i træningen. Efter f.eks. 100.000 opdateringer synkroniserer vi θ- med θ. Formålet er at fastsætte Q-værdimålene midlertidigt, så vi ikke har et bevægeligt mål at jagte. Desuden påvirker parameterændringer ikke θ- med det samme, og derfor er selv input måske ikke 100 % i.i.d., vil det ikke ukorrekt forstørre sin effekt som nævnt tidligere.

Med både experience replay og målnetværket har vi et mere stabilt input og output til at træne netværket og opfører os mere som superviseret træning.
Experience replay har den største ydelsesforbedring i DQN. Målnetværksforbedringen er betydelig, men ikke så kritisk som replay. Men det bliver vigtigere, når kapaciteten af netværket er lille.
Deep Q-learning with experience replay
Her er algoritmen:

hvor ϕ forbehandler de sidste 4 billedrammer for at repræsentere tilstanden. For at opfange bevægelse bruger vi fire frames til at repræsentere en tilstand.
Implementeringsdetaljer
Loss-funktion
Lad os gennemgå et par flere implementeringsdetaljer for at forbedre ydeevnen. DQN anvender Huber-tab (grøn kurve), hvor tabet er kvadratisk for små værdier af a og lineært for store værdier.


Indførelsen af Hubertab giver mulighed for mindre dramatiske ændringer, som ofte skader RL.
Optimering
RL-træning er følsom over for optimeringsmetoder. En simpel læringshastighedsskema er ikke dynamisk nok til at håndtere ændringer i input i løbet af træningen. Mange RL-træning anvender RMSProp eller Adam optimizer. DQN trænes med RMSProp. Brug af forudgående optimeringsmetode i Policy Gradient-metoder er også stærkt undersøgt.
ϵ-greedy
DQN bruger ϵ-greedy til at vælge den første handling.
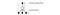
For at forbedre træningen starter ϵ ved 1 og gløder til 0.1 eller 0,05 over den første million frames ved hjælp af følgende politik:

hvor m er antallet af mulige handlinger. I begyndelsen af træningen vælger vi ensartede mulige handlinger, men efterhånden som træningen skrider frem, vælger vi oftere den optimale handling a*. Dette giver mulighed for maksimal udforskning i begyndelsen, som til sidst skifter til udnyttelse.
Men selv under afprøvningen kan vi opretholde ϵ til en lille værdi som f.eks. 0,05. En deterministisk politik kan sidde fast i et lokalt optimum. En ikke-deterministisk politik giver os mulighed for at bryde ud for at få en chance for at nå et bedre optimum.

Arkitektur
Her er DQN-arkitekturen. Vi tager de sidste 4 foregående videobilleder og sender dem ind i konvolutionelle lag efterfulgt af fuldt forbundne lag for at beregne Q-værdierne for hver handling.

I eksemplet nedenfor, hvis vi ikke flytter pagajen opad i billede 3, vil vi gå glip af bolden. Som forventet ud fra DQN er Q-værdien af at flytte pagajen opad meget højere sammenlignet med andre handlinger.


Forbedringer af DQN
Der er foretaget mange forbedringer af DQN. I dette afsnit vil vi vise nogle metoder, der viser væsentlige forbedringer.
Dobbelt DQN
I Q-learning bruger vi følgende formel for målværdien for Q.

Midlertid skaber max-operationen en positiv bias i forhold til Q-estimaterne.

Fra eksemplet ovenfor kan vi se, at max Q(s, a) er højere end den konvergerede værdi 1.0. Dvs. at max-operationen overvurderer Q. Ifølge teori og eksperimenter forbedres DQN-ydelsen, hvis vi bruger online-netværket θ til at udvælge handlingen på en grådig måde og målnetværket θ- til at estimere Q-værdien.

Prioriteret erfaringsgennemspilning
DQN prøver overgange fra genafspilningsbufferen ensartet. Vi bør dog være mindre opmærksomme på prøver, der allerede er tæt på målet. Vi bør prøveovergange, der har en stor afstand til målet:

Derfor kan vi vælge overgange fra bufferen
- på grundlag af ovenstående fejlværdi (vælg overgange med højere fejl hyppigere), eller
- rangordne dem i henhold til fejlværdien og vælge dem efter rang (vælg den med højere rang hyppigere).
For nærmere oplysninger om ligningerne om stikprøvedata henvises til dokumentet Prioritized Experience Replay (prioriteret erfaringsgennemgang).
Dueling DQN
I Dueling DQN beregnes Q med en anden formel nedenfor med værdifunktion V og en tilstandsafhængig handlingsfordelfunktion A nedenfor:

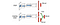
I stedet for at lære Q bruger vi to separate hoveder til at beregne V og A. Empiriske eksperimenter viser, at ydelsen forbedres. DQN opdaterer kun Q-værdifunktionen for en tilstand for en specifik handling. Dueling DQN opdaterer V, som andre Q(s, a’)-opdateringer også kan drage fordel af. Så hver Dueling DQN-træningsiteration menes at have en større virkning.
Noisy Nets for Exploration
DQN anvender ϵ-greedy til at vælge handlinger. Alternativt erstatter NoisyNet det ved at tilføje parametrisk støj til det lineære lag for at støtte udforskningen. I NoisyNet anvendes ε-greedy ikke. Der anvendes en greedy-metode til at vælge handlinger ud fra Q-værdifunktionen. Men for de fuldt forbundne lag af Q-approximatoren tilføjer vi træningsbar parametreret støj nedenfor for at udforske handlinger. Tilføjelse af støj til et dybt netværk svarer ofte til eller er bedre end at tilføje støj til en handling som i ϵ-greedy-metoden.

Mere tanker
DQN hører til en vigtig klasse af RL, nemlig værdiindlæring. I praksis kombinerer vi ofte politikgradienter med metoder til værdiindlæring ved løsning af virkelige problemer.
Leave a Reply