RL – DQN Deep Q-network

Kan datorer spela videospel som människor? År 2015 slog DQN mänskliga experter i många Atari-spel. Men när det gäller komplexa krigsstrategispel klarar sig AI inte så bra. År 2017 slog ett professionellt lag lätt ett AI-program från DeepMind i Starcraft 2.
Som citerat från DeepMinds dokument:
Det är ett multi-agentproblem med flera spelare som interagerar; det finns ofullständig information på grund av en delvis observerad karta; det har ett stort handlingsutrymme som inbegriper val och styrning av hundratals enheter; det har ett stort tillståndsutrymme som måste observeras enbart från råa inmatningsfunktioner; och det har fördröjd kredittilldelning som kräver långsiktiga strategier över tusentals steg.
Vi återupptar vår resa tillbaka till Deep Q-Network DQN. I Seaquest-spelet nedan lär sig DQN att läsa poäng, skjuta fienden och rädda dykare från råbilderna, helt på egen hand. Det upptäcker också kunskap som vi kan referera till som en strategi, till exempel när man ska ta ubåten till ytan för att hämta syre.

Q-lärande lär sig handlingsvärdesfunktionen Q(s, a): hur bra det är att vidta en åtgärd vid ett visst tillstånd. Till exempel, för brädställningen nedan, hur bra det är att flytta bonden två steg framåt. Bokstavligen tilldelar vi ett skalärt värde över fördelen med att göra ett sådant drag.
Q kallas handlingsvärdesfunktionen (eller Q-värdesfunktionen i den här artikeln).

I Q-lärande bygger vi en minnestabell Q för att lagra Q-värden för alla möjliga kombinationer av s och a. Om du är schackspelare är det fusklappen för det bästa draget. I exemplet ovan kan vi inse att flytta bonden 2 steg framåt har de högsta Q-värdena över alla andra. (Minnesförbrukningen kommer att bli för hög för schackspelet. Men låt oss hålla oss till detta tillvägagångssätt lite längre.)
Tekniskt sett samplar vi en åtgärd från det aktuella tillståndet. Vi tar reda på belöningen R (om någon) och det nya tillståndet s’ (den nya brädpositionen). Från minnestabellen bestämmer vi nästa handling a’ som ska utföras och som har maximal Q(s’, a’).
I ett videospel får vi poäng (belöningar) genom att skjuta ner fienden. I ett schackspel är belöningen +1 om vi vinner eller -1 om vi förlorar. Det finns alltså bara en belöning som ges och det tar ett tag att få den.
Q-lärande handlar om att skapa fusket Q.

Vi kan ta ett enda drag a och se vilken belöning R kan vi få. På så sätt skapas en titt framåt i ett steg. R + Q(s’, a’) blir det mål som vi vill att Q(s, a) ska vara. Säg till exempel att alla Q-värden är lika med ett nu. Om vi flyttar joysticken till höger och får 2 poäng vill vi flytta Q(s, a) närmare 3 (dvs. 2 + 1).

När vi fortsätter att spela upprätthåller vi ett löpande genomsnitt för Q. Värdena blir bättre och med några knep kommer Q-värdena att konvergera.
Q-lärningsalgoritm
Nedan följer algoritmen för att anpassa Q med de samplade belöningarna. Om γ (diskonteringsfaktor) är mindre än ett finns det en god chans att Q konvergerar.

Om kombinationerna av tillstånd och åtgärder är för stora blir dock minnes- och beräkningskravet för Q för högt. För att lösa detta byter vi till ett djupt nätverk Q (DQN) för att approximera Q(s, a). Inlärningsalgoritmen kallas Deep Q-learning. Med det nya tillvägagångssättet generaliserar vi approximationen av Q-värdesfunktionen i stället för att komma ihåg lösningarna.
Vilka utmaningar står RL inför jämfört med DL?
I övervakad inlärning vill vi att indata ska vara i.i.d. (oberoende och identiskt fördelade), dvs.
- Proverna slumpas mellan satser och därför har varje sats samma (eller liknande) datafördelning.
- Proverna är oberoende av varandra i samma batch.
Om så inte är fallet kan modellen vara överanpassad för vissa klasser (eller grupper) av prover vid olika tidpunkter och lösningen kommer inte att generaliseras.
För samma indata förändras dess etikett dessutom inte över tiden. Denna typ av stabila villkor för inmatningen och utmatningen ger förutsättningar för att den övervakade inlärningen ska fungera bra.
I förstärkningsinlärning förändras både inmatningen och målet ständigt under processen och gör träningen instabil.
Målet instabilt: Vi bygger ett djupt nätverk för att lära oss värdena för Q, men dess målvärden ändras i takt med att vi får bättre kunskaper. Som visas nedan beror målvärdena för Q på Q själv, vi jagar ett icke-stationärt mål.

i.i.d.: Det finns ett annat problem som har att göra med korrelationerna inom en bana. Inom en träningsiteration uppdaterar vi modellparametrarna för att föra Q(s, a) närmare grundsannolikheten. Dessa uppdateringar kommer att påverka andra uppskattningar. När vi drar upp Q-värdena i det djupa nätverket kommer Q-värdena i de omgivande tillstånden också att dras upp som ett nät.

Vad sägs om att vi bara får en belöning och justerar Q-nätverket för att återspegla den. Därefter gör vi ett nytt drag. Det nya tillståndet kommer att likna det senaste i synnerhet om vi använder råbilder för att representera tillstånd. Den nyligen hämtade Q(s’, a’) kommer att vara högre och vårt nya mål för Q kommer att röra sig högre också oberoende av den nya handlingens förtjänst. Om vi uppdaterar nätverket med en sekvens av åtgärder i samma bana förstoras effekten bortom vår avsikt. Detta destabiliserar inlärningsprocessen och låter som hundar som jagar sina svansar.
Vad är den grundläggande utmaningen vid träning av RL? I RL är vi ofta beroende av policy- eller värdefunktioner för att välja åtgärder. Detta ändras dock ofta i takt med att vi vet bättre vad vi ska utforska. När vi spelar spelet vet vi bättre om de grundläggande sanningsvärdena för tillstånd och åtgärder. Så våra målutgångar förändras också. Nu försöker vi lära oss en kartläggning f för en ständigt föränderlig input och output!
Glckligtvis kan både input och output konvergera. Så om vi saktar ner förändringarna i både input och output tillräckligt mycket kan vi ha en chans att modellera f samtidigt som vi låter den utvecklas.
Lösningar
Erfarenhetsåtergivning: Vi lägger till exempel den senaste miljonen övergångar (eller videoframar) i en buffert och tar ut en minibatch av prover av storlek 32 från denna buffert för att träna det djupa nätverket. Detta bildar ett indataunderlag som är tillräckligt stabilt för träning. Eftersom vi gör slumpmässiga urval från reprisbufferten är data mer oberoende av varandra och närmare i.i.d.
Målnätet: Vi skapar två djupa nätverk θ- och θ. Vi använder det första för att hämta Q-värden medan det andra inkluderar alla uppdateringar i träningen. Efter exempelvis 100 000 uppdateringar synkroniserar vi θ- med θ. Syftet är att fixera Q-värdesmålen tillfälligt så att vi inte har ett rörligt mål att jaga. Dessutom påverkar inte parameterändringar θ- omedelbart och därför kanske inte ens inmatningen är 100 % i.i.d., kommer det inte felaktigt att förstora effekten som tidigare nämnts.

Med både erfarenhetsåterspelning och målnätverket har vi en stabilare ingång och utgång för att träna nätverket och beter oss mer som övervakad träning.
Erfarenhetsåterspelning har den största prestandaförbättringen i DQN. Förbättringen av målnätverket är betydande men inte lika kritisk som uppspelningen. Men den blir viktigare när nätverkets kapacitet är liten.
Deep Q-learning with experience replay
Här är algoritmen:

där ϕ förbehandlar de fyra sista bildrutorna för att representera tillståndet. För att fånga rörelse använder vi fyra bildrutor för att representera ett tillstånd.
Implementeringsdetaljer
Förlustfunktion
Låt oss gå igenom ytterligare några implementeringsdetaljer för att förbättra prestandan. DQN använder Huber-förlust (grön kurva) där förlusten är kvadratisk för små värden på a och linjär för stora värden.


Införandet av Huberförlusten gör det möjligt att göra mindre dramatiska förändringar som ofta skadar RL.
Optimering
RL-utbildning är känslig för optimeringsmetoder. Ett enkelt schema för inlärningshastighet är inte tillräckligt dynamiskt för att hantera förändringar i indata under träningen. Många RL-utbildningar använder RMSProp eller Adam optimizer. DQN tränas med RMSProp. Användning av förhandsoptimeringsmetod i Policy Gradient-metoder är också mycket studerat.
ϵ-greedy
DQN använder ϵ-greedy för att välja den första åtgärden.
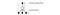
För att förbättra träningen startar ϵ på 1 och glöms till 0.1 eller 0,05 under den första miljonen bilder med hjälp av följande policy:

där m är antalet möjliga åtgärder. I början av utbildningen väljer vi enhetligt möjliga åtgärder, men allteftersom utbildningen fortskrider väljer vi oftare den optimala åtgärden a*. Detta möjliggör maximal utforskning i början som så småningom övergår till utnyttjande.
Men även under testningen kan vi bibehålla ϵ till ett litet värde, t.ex. 0,05. En deterministisk policy kan fastna i ett lokalt optimum. En icke-deterministisk policy gör det möjligt för oss att bryta ut för en chans att nå ett bättre optimum.

Arkitektur
Här är DQN-arkitekturen. Vi tar de fyra senaste föregående videoframarna och matar dem till konvolutionella lager följt av fullt anslutna lager för att beräkna Q-värdena för varje åtgärd.

I exemplet nedan kommer vi att missa bollen om vi inte flyttar paddeln uppåt i bild 3. Som förväntat från DQN är Q-värdet för att flytta paddeln uppåt mycket högre jämfört med andra åtgärder.


Förbättringar av DQN
Många förbättringar har gjorts av DQN. I det här avsnittet kommer vi att visa några metoder som visar på betydande förbättringar.
Double DQN
I Q-learning använder vi följande formel för målvärdet för Q.

Mellertid skapar max-operationen en positiv bias mot Q-skattningarna.

Från exemplet ovan ser vi att max Q(s, a) är högre än det konvergerade värdet 1.0. D.v.s. max-operationen överskattar Q. Enligt teori och experiment förbättras DQN-prestanda om vi använder onlinenätverket θ för att välja åtgärd och målnätverket θ- för att uppskatta Q-värdet.

Prioriterad återspelning av erfarenheter
DQN samplar övergångar från återspelningsbufferten på ett enhetligt sätt. Vi bör dock ägna mindre uppmärksamhet åt prov som redan är nära målet. Vi bör ta prov på övergångar som har ett stort målavstånd:

Därför kan vi välja övergångar från bufferten
- på grundval av felvärdet ovan (välj övergångar med högre fel oftare), eller
- ranka dem enligt felvärdet och välj dem efter rang (välj den med högre rang oftare).
För detaljer om ekvationerna för sampling av data hänvisas till dokumentet Prioritized Experience Replay.
Dueling DQN
I Dueling DQN beräknas Q med en annan formel nedan med värdefunktion V och en tillståndsberoende handlingsfördelningsfunktion A nedan:

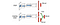
Istället för att lära oss Q använder vi två separata huvud för att beräkna V och A. Empiriska experiment visar att prestandan förbättras. DQN uppdaterar Q-värdesfunktionen för ett tillstånd endast för en specifik åtgärd. Duellerande DQN uppdaterar V som andra Q(s, a’)-uppdateringar också kan dra nytta av. Så varje träningsiteration av Dueling DQN anses ha en större inverkan.
Noisy Nets for Exploration
DQN använder ϵ-greedy för att välja åtgärder. Alternativt ersätter NoisyNet det genom att lägga till parametriskt brus i det linjära lagret för att underlätta utforskningen. I NoisyNet används inte ε-greedy. Den använder en greedy-metod för att välja åtgärder från Q-värdesfunktionen. Men för de fullt anslutna lagren i Q-approximatorn lägger vi till tränbart parametriskt brus nedan för att utforska åtgärder. Att lägga till brus till ett djupt nätverk är ofta likvärdigt eller bättre än att lägga till brus till en åtgärd som i ϵ-greedy-metoden.

Fler tankar
DQN hör till en viktig klass av RL, nämligen värdelärning. I praktiken kombinerar vi ofta policygradienter med metoder för värdeinlärning när vi löser verkliga problem.
Leave a Reply