Restricted Boltzmann Machines – förenklat
Vad är Restricted Boltzmann Machines?
RBMs är ett artificiellt neuralt nätverk i två lager med generativ förmåga. De har förmågan att lära sig en sannolikhetsfördelning över sin uppsättning indata. RBM uppfanns av Geoffrey Hinton och kan användas för dimensionalitetsreduktion, klassificering, regression, kollaborativ filtrering, inlärning av funktioner och ämnesmodellering.
RBM är en speciell klass av Boltzmannmaskiner och de är begränsade när det gäller förbindelserna mellan de synliga och dolda enheterna. Detta gör det enkelt att implementera dem jämfört med Boltzmannmaskiner. Som tidigare nämnts är de ett neuralt nätverk med två lager (ett är det synliga lagret och det andra är det dolda lagret) och dessa två lager är sammankopplade genom en helt bipartitisk graf. Detta innebär att varje nod i det synliga lagret är ansluten till varje nod i det dolda lagret, men att inga två noder i samma grupp är anslutna till varandra. Denna begränsning möjliggör effektivare utbildningsalgoritmer än vad som finns tillgängligt för den allmänna klassen av Boltzmann-maskiner, särskilt den gradientbaserade kontrastdivergensalgoritmen.
En Restricted Boltzmann Machine ser ut så här:
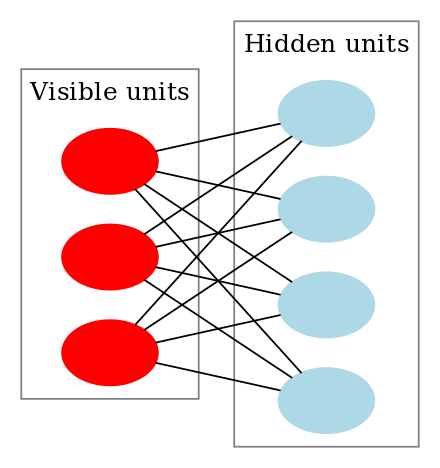
Hur fungerar Restricted Boltzmann Machines?
I en RBM har vi ett symmetriskt tvådelat diagram där inga två enheter inom samma grupp är anslutna. Flera RBM:er kan också stacked och kan finjusteras genom gradientnedgång och back-propagation. Ett sådant nätverk kallas Deep Belief Network. Även om RBMs används ibland har de flesta inom djupinlärningsvärlden börjat ersätta användningen av dem med General Adversarial Networks eller Variational Autoencoders.
RBM är ett stokastiskt neuralt nätverk, vilket innebär att varje neuron kommer att ha ett visst slumpmässigt beteende när den aktiveras. Det finns två andra lager av bias-enheter (dolda bias och synliga bias) i ett RBM. Det är detta som gör att RBM skiljer sig från autoenkoder. Den dolda bias RBM producerar aktiveringen i den framåtriktade passagen och den synliga bias hjälper RBM att rekonstruera inmatningen i den bakåtriktade passagen. Den rekonstruerade inmatningen skiljer sig alltid från den faktiska inmatningen eftersom det inte finns några kopplingar mellan de synliga enheterna och därför inget sätt att överföra information sinsemellan.

Ovanstående bild visar det första steget i träningen av en RBM med flera inmatningar. Ingångarna multipliceras med vikterna och läggs sedan till bias. Resultatet skickas sedan genom en sigmoid aktiveringsfunktion och resultatet avgör om det dolda tillståndet aktiveras eller inte. Vikterna kommer att vara en matris med antalet ingångsnoder som antal rader och antalet dolda noder som antal kolumner. Den första dolda noden kommer att få vektormultiplikationen av ingångarna multiplicerat med den första kolumnen av vikter innan motsvarande förskjutningsterm läggs till.
Och om du undrar vad en sigmoidfunktion är, här är formeln:

Så ekvationen som vi får i detta steg skulle vara,
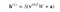
där h(1) och v(0) är motsvarande vektorer (kolumnmatriser) för det dolda och det synliga lagret med överst på sidan som iterationen (v(0) är den indata som vi ger nätverket) och a är det dolda lagrets biasvektor.
(Observera att vi har att göra med vektorer och matriser här och inte med endimensionella värden.)

Nu visar denna bild den omvända fasen eller rekonstruktionsfasen. Den liknar den första passagen men i motsatt riktning. Ekvationen blir:
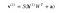
.
Leave a Reply