Big Data tillämpas: Spark vs Flink

Just som begreppet Artificiell Intelligens (AI) har föraktats under många år, börjar just 2017 ”Big Data” något som genererar mer förkastande än acceptans på grund av daglig slitage och bombning. Allt är Big Data och allt löses med Big Data. Men vad gör vi då de som arbetar med Big Data?
Big Data har under de senaste åren relaterats till stora mängder strukturerade eller ostrukturerade data som produceras av system eller organisationer. Dess betydelse ligger inte i själva uppgifterna utan i vad vi kan göra med dessa uppgifter. Om hur data kan analyseras för att fatta bättre beslut. Ofta kommer mycket av det värde som kan utvinnas ur data från vår förmåga att bearbeta dem i tid. Därför är det viktigt att mycket väl känna till både datakällorna och den ram inom vilken vi ska bearbeta dem.
Ett av de inledande målen i alla Big Data-projekt är att definiera den bearbetningsarkitektur som bäst anpassar sig till ett specifikt problem. Detta innefattar ett oändligt antal möjligheter och alternativ:
- Vad är källorna?
- Hur lagras uppgifterna?
- Är det några beräkningsmässiga begränsningar? Och av tid?
- Vilka algoritmer ska vi använda?
- Vilken noggrannhet ska vi uppnå?
- Hur kritisk är processen?
Vi måste känna till vår domän mycket väl för att kunna besvara dessa frågor och ge kvalitetssvar. I det här inlägget kommer vi att föreslå en förenkling av ett verkligt användningsfall och jämföra två tekniker för bearbetning av stora data.
Det föreslagna användningsfallet är tillämpningen av Kappa-arkitekturen för bearbetning av Netflow-spår, med hjälp av olika bearbetningsmotorer.
Netflow är ett nätverksprotokoll för att samla in information om IP-trafik. Det ger oss information som start- och slutdatum för anslutningar, käll- och destinations-IP-adresser, portar, protokoll, paketbytes osv. Det är för närvarande en standard för övervakning av nätverkstrafik och stöds av olika hårdvaru- och mjukvaruplattformar.
Varje händelse som ingår i netflow-spåren ger oss utökad information om en anslutning som upprättats i det övervakade nätverket. Dessa händelser tas in via Apache Kafka för att analyseras av bearbetningsmotorn – i det här fallet Apache Spark eller Apache Flink – som utför en enkel operation, t.ex. beräkning av det euklidiska avståndet mellan par av händelser. Denna typ av beräkningar är grundläggande i algoritmer för anomalidetektion.
För att kunna utföra denna behandling är det dock nödvändigt att gruppera händelserna, till exempel genom tillfälliga fönster, eftersom data i ett rent strömningssammanhang saknar en början eller ett slut.
När nätflödeshändelserna väl är grupperade ger beräkningen av avstånden mellan paren upphov till en kombinatorisk explosion. Om vi till exempel får 1000 händelser/s från samma IP och grupperar dem var 5:e sekund, kommer varje fönster att kräva totalt 12 497 500 beräkningar.
Den strategi som skall tillämpas är helt beroende av bearbetningsmotorn. När det gäller Spark är händelsegruppering okomplicerad eftersom den inte arbetar i streaming utan istället använder micro-batching, så bearbetningsfönstret kommer alltid att vara definierat. När det gäller Flink är denna parameter dock inte obligatorisk eftersom det är en ren streamingmotor, så det är nödvändigt att definiera det önskade behandlingsfönstret i koden.
Beräkningen returnerar som resultat en ny dataström som publiceras i ett annat Kafka-ämne, vilket visas i följande figur. På detta sätt uppnås en stor flexibilitet i designen, att kunna kombinera denna behandling med andra i mer komplexa datapipelines.

Kappa-arkitektur
Kappa-arkitekturen är ett mjukvaruarkitektoniskt mönster som använder dataströmmar eller ”streams” i stället för att använda data som redan är lagrade och persisterade. Datakällorna kommer därför att vara oföränderliga och kontinuerliga, t.ex. de poster som genereras i en loggbok. Dessa informationskällor står i kontrast till de traditionella databaser som används i system för batch- eller batchanalys.
Dessa ”strömmar” skickas genom ett behandlingssystem och lagras i hjälpsystem för tjänsteskiktet.
Kappa-arkitekturen är en förenkling av Lambda-arkitekturen, från vilken den skiljer sig i följande avseenden:
- Allt är en ström (batch är ett specialfall)
- Datakällor är oföränderliga (rådata kvarstår)
- Det finns ett enda analytiskt ramverk (fördelaktigt för underhåll)
- Replay-funktionalitet, det vill säga att alla data som analyserats hittills kan bearbetas på nytt (till exempel när man har en ny algoritm)
Sammanfattningsvis elimineras batch-delen, vilket gynnar ett databehandlingssystem som är i rörelse.
För att få händerna smutsiga
För att bättre förstå alla dessa teoretiska begrepp finns det inget bättre än att fördjupa genomförandet. Ett av de element som vi vill omsätta i praktiken med detta proof of concept är att kunna utbyta mellan olika bearbetningsmotorer på ett transparent sätt. Med andra ord, hur enkelt är det att växla mellan Spark och Flink baserat på samma Scalakod? Tyvärr är saker och ting inte så okomplicerade, även om det är möjligt att nå en gemensam dellösning, vilket du kan se i följande avsnitt.
Netflow-händelser
Varje Netflow-händelse ger information om en specifik anslutning som upprättats i nätverket. Dessa händelser representeras i JSON-format och tas in i Kafka. För enkelhetens skull kommer endast IPv4-anslutningar att användas.
Exempel på händelse:
{
"eventid":995491697672682,
"dvc_version":"3.2",
"aproto":"failed",
"src_ip4":168099844,
"dst_ip4":4294967295,
"eventtime":1490024708,
"out_packets":1,
"type":"flow",
"dvc_time":1490024739,
"dst_ip":"255.255.255.255",
"src_ip":"10.5.0.4",
"duration":0,
"in_bytes":0,
"conn_state":"new",
"@version":"1",
"out_bytes":157,
"dvc_type":"suricata",
"in_packets":0,
"nproto":"UDP",
"src_port":42126,
"@timestamp":"2017-03-20T15:45:08.000Z",
"dst_port":40237,
"category":"informational"
}
Shared part
Som nämnts ovan är ett av syftena med den här artikeln att på ett transparent sätt använda olika Big Data-bearbetningsmiljöer , det vill säga att använda samma Scala-funktioner för Spark, Flink eller framtida ramverk. Tyvärr har särdragen hos varje ramverk inneburit att endast en del av den implementerade Scalakoden kan vara gemensam för båda.
Den gemensamma koden omfattar mekanismerna för att serialisera och deserialisera netflowhändelser. Vi förlitar oss på biblioteket json4s i Scala och definierar en fallklass med de intressanta fälten:
case class Flow_ip4(eventid: String,
dst_ip4: String,
dst_port: String,
duration: String,
in_bytes: String,
in_packets: String,
out_bytes: String,
out_packets: String,
src_ip4: String,
src_port: String) extends Serializable
Det Flow-objekt som implementerar denna serialisering är dessutom definierat för att kunna arbeta bekvämt med olika Big Data-motorer:
class Flow(trace: String) extends Serializable {implicit val formats =DefaultFormatsvar flow_case : Flow_ip4 = parse(trace).extractdef getFlow() : Flow_ip4 = flow_case}
En annan kod som delas av båda ramverken är funktionerna för att beräkna det euklidiska avståndet, erhålla kombinationerna av en serie objekt och generera Json-resultatet:
object utils { def euclideanDistance(xs: List, ys: List) = {
sqrt((xs zip ys).map { case (x,y)=> pow(y - x, 2) }.sum)
} def getCombinations(lists : Iterable) = {
lists.toList.combinations(2).map(x=> (x(0),x(1))).toList
} def getAllValuesFromString(flow_case : Flow_ip4) = flow_case.productIterator.drop(1)
.map(_.asInstanceOf.toDouble).toList def calculateDistances(input: Iterable): List = {
val combinations: List = getCombinations(input)
val distances = combinations.map{
case(f1,f2) => (f1.eventid,f2.eventid,euclideanDistance(getAllValuesFromString(f1),
getAllValuesFromString(f2)))}
distances.sortBy(_._3)
} def generateJson(x: (String, String, Double)): String = {
val obj = Map("eventid_1" -> x._1,
"eventid_2" -> x._2,
"distance" -> x._3,
"timestamp" -> System.currentTimeMillis())
val str_obj = scala.util.parsing.json.JSONObject(obj).toString()
str_obj
}
}
Specifik del av varje ramverk
Användningen av transformationer och åtgärder är där särdragen hos varje ramverk förhindrar att det är en generisk kod.
Som observerats itererar Flink av varje händelse, filtrerar, serialiserar, grupperar efter IP och tid och tillämpar slutligen avståndsberäkning för att skicka ut den till Kafka via en producent.
I Spark, å andra sidan, eftersom händelserna redan är grupperade efter tid, behöver vi bara filtrera, serialisera och gruppera efter IP. När detta är gjort tillämpas funktionerna för avståndsberäkning och resultatet kan skickas ut till Kafka med de rätta biblioteken.
För Flink:
val flow = stream
.filter(!_.contains("src_ip6"))
.map(trace =>{
new Flow(trace).getFlow()
})
.keyBy(_.src_ip4)
.timeWindow(Time.seconds(3))
.apply{(
key: String,
window: TimeWindow,
input: Iterable,
out: Collector]) => {
val distances: List = utils.calculateDistances(input)
out.collect(distances)
}
}
.flatMap(x => x)
flow.map( x=>{
val str_obj: String = utils.generateJson(x)
producer.send(new ProducerRecord(topic_out, str_obj))
})
För Spark:
val flow = stream.map(_.value())
.filter(!_.contains("src_ip6"))
.map(record => {
implicit val formats = DefaultFormats
val flow = new Flow(record).getFlow()
(flow.src_ip4,flow)
})
.groupByKey()flow.foreachRDD(rdd => {
rdd.foreach{ case (key, input ) => {
val distances = utils.calculateDistances(input)
distances.map(x => {val str_obj: String = utils.generateJson(x)
producer.send(new ProducerRecord(topic_out, str_obj))
})
}}
})
Id:n för varje händelse, deras tidsstämplar för intag, resultatet av avståndsberäkningen och den tid då beräkningen slutfördes lagras i Kafka-utgångsämnet. Här är ett exempel på en spårning:
{
"eventid_1":151852746453199,
"ts_flow1":1495466510792,
"eventid_2":1039884491535740,
"ts_flow2":1495466511125,
"distance":12322.94295207115,
"ts_output":1495466520212
}
Resultat
Vi har kört två olika typer av tester: flera händelser inom ett enda fönster och flera händelser i olika fönster, där ett fenomen gör att den kombinatoriska algoritmen till synes är stokastisk och ger olika resultat. Detta uppstår på grund av att data tas in på ett oordnat sätt, allteftersom de anländer till systemet, utan att ta hänsyn till händelsetiden, och grupperingar görs utifrån den, vilket gör att olika kombinationer uppstår.
I följande presentation från Apache Beam förklaras skillnaden mellan behandlingstid och händelsetid mer ingående: https://goo.gl/h5D1yR

Flera händelser i samma fönster
Omkring 10 000 händelser tas in i samma fönster, vilket, om man tillämpar kombinationerna för samma IP:er, kräver nästan 2 miljoner beräkningar. Den totala beräkningstiden i varje ram (dvs. skillnaden mellan den högsta och lägsta utgående tidsstämpeln) med 8 bearbetningskärnor är:
- Spark total tid: 41.50s
- Totaltid Flink:
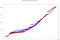
Flera rader av samma färg beror på parallellitet, eftersom det finns beräkningar som slutar vid samma tidpunkt.
Flera händelser i olika fönster
Mer än 50 000 händelser är infogade i olika tidsfönster på 3 sekunder. Det är här som särdragen hos varje motor tydligt framträder. När vi ritar upp samma graf över bearbetningstider uppstår följande:
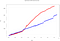
- Spark total tid: 614,1s
- Total tid Flink: 869.3s
Vi observerar en ökning av bearbetningstiden för Flink. Detta beror på hur den tar emot händelser:

Som framgår av den sista figuren använder Flink inte micro-batches och parallelliserar händelsernas fönstren (till skillnad från Spark använder Flink överlappande glidande fönster). Detta leder till en längre beräkningstid, men kortare inmatningstid. Det är en av de särdrag som vi måste ta hänsyn till när vi definierar vår arkitektur för behandling av strömmande Big Data.
Och hur är det med beräkningen?
Det euklidiska avståndet mellan 10 000 händelser har följande fördelning:
Det antas att onormala händelser befinner sig i den ”långa svansen” av histogrammet. Men är det verkligen rimligt? Låt oss analysera det.
I det här fallet betraktas vissa kategoriska parametrar (IP, port) som numeriska för beräkningen. Vi bestämde oss för att göra detta för att öka dimensionaliteten och närma oss ett verkligt problem. Men detta är vad vi får när vi visar alla verkliga värden för avstånden:

Det vill säga brus, eftersom dessa värden (IP, port, källa och destination) förvränger beräkningen. När vi eliminerar dessa fält och bearbetar allting på nytt och behåller:
- duration
- in_bytes
- in_packets
- out_bytes
- out_packets
Vi får följande fördelning:

Den långa svansen är inte längre så befolkad och det finns en viss topp i slutet. Om vi visar värdena från avståndsberäkningen kan vi se var de onormala värdena finns.

Tack vare denna enkla förfining underlättar vi analytikerns arbete, och erbjuder honom/henne ett kraftfullt verktyg, som sparar tid och visar var man kan hitta problemen i ett nätverk.
Slutsatser
Och även om en oändlighet av möjligheter och slutsatser skulle kunna diskuteras, är den mest anmärkningsvärda kunskapen som erhållits genom denna lilla utveckling:
- Bearbetningsram. Det är inte trivialt att gå från ett ramverk till ett annat, så det är viktigt att redan från början bestämma vilket ramverk som ska användas och att känna till dess särdrag mycket väl. Om vi till exempel behöver behandla en händelse omedelbart och detta är kritiskt för verksamheten måste vi välja en bearbetningsmotor som uppfyller detta krav.
- Storbild. För vissa funktioner kommer en motor att vara bättre än andra, men vad är du villig att offra för att få den ena eller andra funktionen?
- Resursanvändning. Minneshantering, CPU, disk … Det är viktigt att tillämpa stresstester, benchmarks etc. på systemet för att veta hur det kommer att bete sig som helhet och identifiera eventuella svaga punkter och flaskhalsar
- Egenskaper och sammanhang. Det är viktigt att alltid ta hänsyn till det specifika sammanhanget och veta vilka egenskaper som bör införas i systemet. Vi har använt parametrar som portar eller IP:er i beräkningen av avstånd för att försöka upptäcka anomalier i ett nätverk. Dessa egenskaper, trots att de är numeriska, har ingen rumslig innebörd. Det finns dock sätt att dra nytta av denna typ av data, men vi lämnar det till ett framtida inlägg.
Detta inlägg publicerades ursprungligen på https://www.gradiant.org/noticia/big-data-aplicado-spark-vs-flink/
Tack till Adrián Portabales ( adrianp )
.
Leave a Reply