Big Data anvendes: Spark vs Flink

Sådan som begrebet kunstig intelligens (AI) har været foragtet i mange år, lige i 2017 begynder ‘Big Data’ noget, der genererer mere afvisning end accept på grund af daglig slid og bombning. Alt er Big Data, og alt bliver løst med Big Data. Men hvad gør vi så dem, der arbejder med Big Data?
Big Data er i de senere år blevet relateret til store mængder af strukturerede eller ustrukturerede data, der produceres af systemer eller organisationer. Dens betydning ligger ikke i selve dataene, men i det, vi kan gøre med disse data. Om hvordan data kan analyseres for at træffe bedre beslutninger. Ofte kommer en stor del af den værdi, der kan hentes fra data, fra vores evne til at behandle dem i tide. Derfor er det vigtigt at kende både datakilderne og den ramme, som vi skal behandle dem i, meget godt.
Et af de indledende mål i alle Big Data-projekter er at definere den behandlingsarkitektur, der bedst passer til et specifikt problem. Dette omfatter et utal af muligheder og alternativer:
- Hvad er kilderne?
- Hvordan lagres dataene?
- Er der nogen beregningsmæssige begrænsninger? Og af tid?
- Hvilke algoritmer skal vi anvende?
- Hvilken nøjagtighed skal vi opnå?
- Hvor kritisk er processen?
Vi er nødt til at kende vores domæne meget godt for at kunne besvare disse spørgsmål og give kvalitetssvar. I løbet af dette indlæg vil vi foreslå en forenkling af en rigtig brugssag og sammenligne to Big Data-behandlingsteknologier.
Den foreslåede brugssag er anvendelsen af Kappa-arkitekturen til behandling af Netflow-spor ved hjælp af forskellige behandlingsmotorer.
Netflow er en netværksprotokol til indsamling af oplysninger om IP-trafik. Den giver os oplysninger som f.eks. start- og slutdatoer for forbindelser, kilde- og destinations-IP-adresser, porte, protokoller, pakkebyte’er osv. Det er i øjeblikket en standard for overvågning af netværkstrafik og understøttes af forskellige hardware- og softwareplatforme.
Hver begivenhed i netflow-sporene giver os udvidede oplysninger om en forbindelse, der er etableret i det overvågede netværk. Disse hændelser indlæses via Apache Kafka for at blive analyseret af behandlingsmotoren – i dette tilfælde Apache Spark eller Apache Flink – og udfører en simpel operation som f.eks. beregning af den euklidiske afstand mellem parvis af hændelser. Denne type beregninger er grundlæggende i algoritmer til påvisning af anomalier.
For at kunne udføre denne behandling er det imidlertid nødvendigt at gruppere begivenhederne, f.eks. gennem midlertidige vinduer, da dataene i en ren streamingkontekst mangler en begyndelse eller en slutning.
Når netflowbegivenhederne er grupperet, giver beregningen af afstandene mellem parrene en kombinatorisk eksplosion. Hvis vi f.eks. modtager 1000 begivenheder/s fra den samme IP, og vi grupperer dem hver 5. sekund, vil hvert vindue kræve i alt 12 497 500 beregninger.
Den strategi, der skal anvendes, er helt afhængig af behandlingsmotoren. I tilfælde af Spark er gruppering af hændelser ligetil, da den ikke arbejder i streaming, men i stedet bruger micro-batching, så behandlingsvinduet vil altid være defineret. I tilfældet med Flink er denne parameter imidlertid ikke obligatorisk, da det er en ren streamingmotor, så det er nødvendigt at definere det ønskede behandlingsvindue i koden.
Beregningen returnerer som resultat en ny datastrøm, der offentliggøres i et andet Kafka-emne, som vist i følgende figur. På denne måde opnås en stor fleksibilitet i designet, idet man kan kombinere denne behandling med andre i mere komplekse datapipelines.

Kappa-arkitektur
Kappa-arkitekturen er et softwarearkitekturmønster, der anvender datastrømme eller “streams” i stedet for at bruge data, der allerede er lagret og persisteret. Datakilderne vil derfor være uforanderlige og kontinuerlige, som f.eks. de poster, der genereres i en logbog. Disse informationskilder står i modsætning til de traditionelle databaser, der anvendes i batch- eller batch-analysesystemer.
Disse “streams” sendes gennem et behandlingssystem og lagres i hjælpesystemer til servicelaget.
Kappa-arkitekturen er en forenkling af Lambda-arkitekturen, som den adskiller sig fra på følgende punkter:
- Alt er en stream (batch er et særtilfælde)
- Datakilderne er uforanderlige (rådata persisterer)
- Der er en enkelt analytisk ramme (fordelagtigt for vedligeholdelse)
- Replay-funktionalitet, dvs. genbehandling af alle de data, der er analyseret indtil nu (f.eks. når man har en ny algoritme)
Sammenfattende er batchdelen elimineret, hvilket fremmer et databehandlingssystem, der er i bevægelse.
Få hænderne beskidte
For bedre at forstå alle disse teoretiske begreber er der intet bedre end at uddybe gennemførelsen. Et af de elementer, som vi ønsker at omsætte i praksis med dette proof of concept, er at kunne udveksle mellem forskellige behandlingsmotorer på en gennemsigtig måde. Med andre ord, hvor let er det at skifte mellem Spark og Flink baseret på den samme Scala-kode? Desværre er tingene ikke så ligetil, selv om det er muligt at nå frem til en fælles delløsning, som du kan se i de følgende afsnit.
Netflow-hændelser
Hver Netflow-hændelse giver oplysninger om en specifik forbindelse, der er etableret i netværket. Disse hændelser er repræsenteret i JSON-format og indlæses i Kafka. For enkelhedens skyld vil der kun blive anvendt IPv4-forbindelser.
Eksempel på begivenhed:
{
"eventid":995491697672682,
"dvc_version":"3.2",
"aproto":"failed",
"src_ip4":168099844,
"dst_ip4":4294967295,
"eventtime":1490024708,
"out_packets":1,
"type":"flow",
"dvc_time":1490024739,
"dst_ip":"255.255.255.255",
"src_ip":"10.5.0.4",
"duration":0,
"in_bytes":0,
"conn_state":"new",
"@version":"1",
"out_bytes":157,
"dvc_type":"suricata",
"in_packets":0,
"nproto":"UDP",
"src_port":42126,
"@timestamp":"2017-03-20T15:45:08.000Z",
"dst_port":40237,
"category":"informational"
}
Shared part
Som nævnt ovenfor er et af formålene med denne artikel at anvende forskellige Big Data-behandlingsmiljøer på en gennemsigtig måde , dvs. at anvende de samme Scala-funktioner til Spark, Flink eller fremtidige frameworks. Desværre har de enkelte rammers særegenheder betydet, at kun en del af den implementerede Scala-kode kan være fælles for begge.
Den fælles kode omfatter mekanismerne til at serialisere og deserialisere netflow-hændelser. Vi stoler på Scalas json4s-bibliotek og definerer en case-klasse med de interessante felter:
case class Flow_ip4(eventid: String,
dst_ip4: String,
dst_port: String,
duration: String,
in_bytes: String,
in_packets: String,
out_bytes: String,
out_packets: String,
src_ip4: String,
src_port: String) extends Serializable
Dertil kommer, at Flow-objektet, der implementerer denne serialisering, er defineret for at kunne arbejde komfortabelt med forskellige Big Data-motorer:
class Flow(trace: String) extends Serializable {implicit val formats =DefaultFormatsvar flow_case : Flow_ip4 = parse(trace).extractdef getFlow() : Flow_ip4 = flow_case}
En anden kode, der deles af begge rammer, er funktionerne til at beregne den euklidiske afstand, opnå kombinationer af en række objekter og generere Json af resultaterne:
object utils { def euclideanDistance(xs: List, ys: List) = {
sqrt((xs zip ys).map { case (x,y)=> pow(y - x, 2) }.sum)
} def getCombinations(lists : Iterable) = {
lists.toList.combinations(2).map(x=> (x(0),x(1))).toList
} def getAllValuesFromString(flow_case : Flow_ip4) = flow_case.productIterator.drop(1)
.map(_.asInstanceOf.toDouble).toList def calculateDistances(input: Iterable): List = {
val combinations: List = getCombinations(input)
val distances = combinations.map{
case(f1,f2) => (f1.eventid,f2.eventid,euclideanDistance(getAllValuesFromString(f1),
getAllValuesFromString(f2)))}
distances.sortBy(_._3)
} def generateJson(x: (String, String, Double)): String = {
val obj = Map("eventid_1" -> x._1,
"eventid_2" -> x._2,
"distance" -> x._3,
"timestamp" -> System.currentTimeMillis())
val str_obj = scala.util.parsing.json.JSONObject(obj).toString()
str_obj
}
}
Specifik del af hver ramme
Anvendelsen af transformationer og handlinger er der, hvor de særlige forhold i hver ramme forhindrer det i at være en generisk kode.
Som observeret itererer Flink ved hver enkelt begivenhed, filtrerer, serialiserer, grupperer efter IP og tid og til sidst anvender afstandsberegning for at sende den ud til Kafka gennem en producent.
I Spark, på den anden side, da begivenhederne allerede er grupperet efter tid, behøver vi kun at filtrere, serialisere og gruppere efter IP. Når dette er gjort, anvendes afstandsberegningsfunktionerne, og resultatet kan sendes ud til Kafka med de rette biblioteker.
For Flink:
val flow = stream
.filter(!_.contains("src_ip6"))
.map(trace =>{
new Flow(trace).getFlow()
})
.keyBy(_.src_ip4)
.timeWindow(Time.seconds(3))
.apply{(
key: String,
window: TimeWindow,
input: Iterable,
out: Collector]) => {
val distances: List = utils.calculateDistances(input)
out.collect(distances)
}
}
.flatMap(x => x)
flow.map( x=>{
val str_obj: String = utils.generateJson(x)
producer.send(new ProducerRecord(topic_out, str_obj))
})
For Spark:
val flow = stream.map(_.value())
.filter(!_.contains("src_ip6"))
.map(record => {
implicit val formats = DefaultFormats
val flow = new Flow(record).getFlow()
(flow.src_ip4,flow)
})
.groupByKey()flow.foreachRDD(rdd => {
rdd.foreach{ case (key, input ) => {
val distances = utils.calculateDistances(input)
distances.map(x => {val str_obj: String = utils.generateJson(x)
producer.send(new ProducerRecord(topic_out, str_obj))
})
}}
})
ID’erne for hver enkelt begivenhed, deres tidsstempler for indlæsning, resultatet af afstandsberegningen og det tidspunkt, hvor beregningen blev afsluttet, gemmes i Kafka-udgangstemaet. Her er et eksempel på et spor:
{
"eventid_1":151852746453199,
"ts_flow1":1495466510792,
"eventid_2":1039884491535740,
"ts_flow2":1495466511125,
"distance":12322.94295207115,
"ts_output":1495466520212
}
Resultater
Vi har kørt to forskellige typer af test: flere begivenheder inden for et enkelt vindue og flere begivenheder i forskellige vinduer, hvor et fænomen gør, at den kombinatoriske algoritme tilsyneladende er stokastisk og giver forskellige resultater. Det skyldes, at data indlæses på en uordnet måde, efterhånden som de ankommer til systemet, uden at der tages hensyn til hændelsestidspunktet, og der foretages grupperinger på baggrund heraf, hvilket vil medføre, at der findes forskellige kombinationer.
Den følgende præsentation fra Apache Beam forklarer mere detaljeret forskellen mellem behandlingstid og hændelsestidspunkt: https://goo.gl/h5D1yR

Flere hændelser i samme vindue
Omkring 10.000 hændelser indlæses i samme vindue, hvilket ved anvendelse af kombinationerne for de samme IP’er kræver næsten 2 millioner beregninger. Den samlede beregningstid i hver ramme (dvs. forskellen mellem det højeste og det laveste output-tidsstempel) med 8 processorkerner er:
- Spark samlet tid: 41.50s
- Total tid Flink: 40,24s
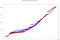
Flere linjer af samme farve skyldes parallelisme, da der er beregninger, der slutter på samme tidspunkt.
Flere hændelser i forskellige vinduer
Mere end 50 000 hændelser er indsat langs forskellige tidsvinduer på 3s. Det er her, at de enkelte motorers særpræg træder tydeligt frem. Når vi plotter den samme graf over behandlingstider, opstår følgende:
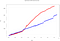
- Spark samlet tid: 614,1s
- Total tid Flink: 869.3s
Vi observerer en stigning i behandlingstiden for Flink. Dette skyldes den måde, den indtager hændelser på:

Som det ses i den sidste figur, bruger Flink ikke micro-batches og paralleliserer hændelsesvinduet (i modsætning til Spark, der bruger overlappende glidende vinduer). Dette medfører en længere beregningstid, men en kortere indlæsningstid. Det er et af de særlige forhold, som vi skal tage hensyn til, når vi definerer vores arkitektur til behandling af streaming Big Data.
Og hvad med beregningen?
Den euklidiske afstand for 10.000 hændelser har følgende fordeling:
Det antages, at unormale hændelser befinder sig i “den lange hale” af histogrammet. Men giver det virkelig mening? Lad os analysere det.
I dette tilfælde betragtes visse kategoriske parametre (IP, port) som numeriske for beregningen. Vi besluttede at gøre dette for at øge dimensionaliteten og komme tættere på et reelt problem. Men dette er, hvad vi får, når vi viser alle de reelle værdier for afstandene:

Det vil sige støj, da disse værdier (IP, port, kilde og destination) forvrænger beregningen. Men når vi fjerner disse felter og behandler alting igen, idet vi beholder:
- duration
- in_bytes
- in_packets
- out_bytes
- out_packets
Vi får følgende fordeling:

Den lange hale er ikke længere så tæt befolket, og der er en vis top i slutningen. Hvis vi viser værdierne for afstandsberegningen, kan vi se, hvor de unormale værdier er.

Takket være denne enkle forfinelse letter vi analytikerens arbejde, idet vi tilbyder ham/hende et effektivt værktøj, der sparer tid og peger på, hvor problemerne i et netværk kan findes.
Konklusioner
Og selv om der kunne diskuteres et uendeligt antal muligheder og konklusioner, er den mest bemærkelsesværdige viden, der er opnået gennem denne lille udvikling:
- Behandlingsramme. Det er ikke trivielt at gå fra en ramme til en anden, så det er vigtigt fra starten at beslutte, hvilken ramme der skal bruges, og at kende dens særlige karakteristika meget godt. Hvis vi f.eks. skal behandle en begivenhed med det samme, og dette er kritisk for virksomheden, skal vi vælge en behandlingsmotor, der opfylder dette krav.
- Det store billede. For visse funktioner vil en motor skille sig ud i forhold til andre, men hvad er du villig til at ofre for at opnå denne eller hin funktion?
- Ressourceudnyttelse. Hukommelsesstyring, CPU, disk … Det er vigtigt at anvende stresstest, benchmarks osv. på systemet for at vide, hvordan det vil opføre sig som helhed og identificere mulige svage punkter og flaskehalse
- Egenskaber og kontekst. Det er vigtigt altid at tage hensyn til den specifikke kontekst og vide, hvilke egenskaber der skal indføres i systemet. Vi har brugt parametre som f.eks. porte eller IP’er i beregningen af afstande for at forsøge at opdage anomalier i et netværk. Selv om disse karakteristika er numeriske, har de ikke en rumlig betydning. Der er dog måder at drage fordel af denne type data på, men vi lader det blive til et fremtidigt indlæg.
Dette indlæg blev oprindeligt offentliggjort på https://www.gradiant.org/noticia/big-data-aplicado-spark-vs-flink/
Tak til Adrián Portabales ( adrianp )
Leave a Reply