Anscombe’s Quartet
Jag har alltid trott på att ”numeriska beräkningar är exakta, men grafer är grova”. Eftersom jag är en person som precis har börjat lära mig dataanalys var det svårt för mig att förstå vikten av datavisualisering tillsammans med sammanfattande statistik. Men allt förändrades efter att ha deltagit i denna Data Visualization Meetup, och det var då jag introducerades till Anscombe’s Quartet.
Anscombe’s Quartet utvecklades av statistikern Francis Anscombe. Den består av fyra dataset som var och en innehåller elva (x,y)-par. Det viktigaste att notera om dessa dataset är att de har samma beskrivande statistik. Men saker och ting förändras helt, och jag måste betona HELT, när de grafiskt redovisas. Varje graf berättar en annan historia oavsett att deras sammanfattande statistik är likartad.
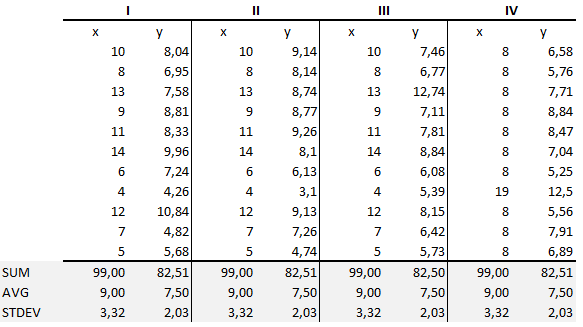
Den sammanfattande statistiken visar att medelvärdena och varianserna var identiska för x och y i alla grupper :
- Medelvärdet för x är 9 och medelvärdet för y är 7.50 för varje dataset.
- På samma sätt är variansen för x 11 och variansen för y 4,13 för varje dataset
- Korrelationskoefficienten (hur starkt sambandet är mellan två variabler) mellan x och y är 0.816 för varje dataset
När vi plottar dessa fyra dataset på ett x/y-koordinatplan kan vi observera att de också visar samma regressionslinjer, men varje dataset berättar en annan historia :

- Dataset I verkar ha rena och välpassande linjära modeller.
- Dataset II är inte normalt fördelat.
- I dataset III är fördelningen linjär, men den beräknade regressionen slås ut av en outlier.
- Dataset IV visar att det räcker med en outlier för att få fram en hög korrelationskoefficient.
Denna kvartett understryker vikten av visualisering vid dataanalys. Genom att titta på data avslöjas mycket av strukturen och en tydlig bild av datasetet.
En dator ska göra både beräkningar och grafer. Båda typerna av utdata bör studeras; var och en bidrar till förståelsen.
Leave a Reply