Restricted Boltzmann Machines – Vereinfacht
Was sind Restricted Boltzmann Machines?
RBMs sind ein zweischichtiges künstliches neuronales Netz mit generativen Fähigkeiten. Sie sind in der Lage, eine Wahrscheinlichkeitsverteilung über ihre Eingabedaten zu lernen. RBMs wurden von Geoffrey Hinton erfunden und können für Dimensionalitätsreduktion, Klassifizierung, Regression, kollaboratives Filtern, Merkmalslernen und Themenmodellierung verwendet werden.
RBMs sind eine spezielle Klasse von Boltzmann-Maschinen und sind in Bezug auf die Verbindungen zwischen den sichtbaren und den verborgenen Einheiten eingeschränkt. Dadurch sind sie im Vergleich zu Boltzmann-Maschinen einfach zu implementieren. Wie bereits erwähnt, handelt es sich um ein zweischichtiges neuronales Netz (eine sichtbare Schicht und eine verborgene Schicht), und diese beiden Schichten sind durch einen vollständig bipartiten Graphen verbunden. Das bedeutet, dass jeder Knoten in der sichtbaren Schicht mit jedem Knoten in der verborgenen Schicht verbunden ist, aber keine zwei Knoten in derselben Gruppe miteinander verbunden sind. Diese Einschränkung ermöglicht effizientere Trainingsalgorithmen als die, die für die allgemeine Klasse der Boltzmann-Maschinen verfügbar sind, insbesondere den gradientenbasierten kontrastiven Divergenzalgorithmus.
Eine Restricted Boltzmann Machine sieht wie folgt aus:
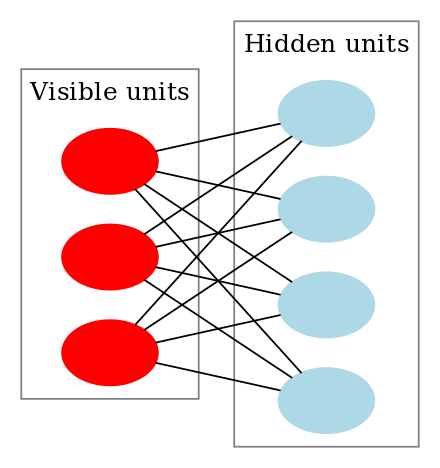
Wie funktionieren Restricted Boltzmann Machines?
In einer RBM haben wir einen symmetrischen bipartiten Graphen, bei dem keine zwei Einheiten innerhalb derselben Gruppe miteinander verbunden sind. Es können auch mehrere RBMs stacked verwendet werden, die durch den Prozess des Gradientenabstiegs und der Backpropagation feinabgestimmt werden können. Ein solches Netz wird als Deep Belief Network bezeichnet. Obwohl RBMs gelegentlich verwendet werden, haben die meisten Leute in der Deep-Learning-Gemeinschaft damit begonnen, sie durch General Adversarial Networks oder Variational Autoencoders zu ersetzen.
RBM ist ein stochastisches neuronales Netz, was bedeutet, dass jedes Neuron ein gewisses Zufallsverhalten aufweist, wenn es aktiviert wird. Es gibt zwei weitere Schichten von Bias-Einheiten (hidden bias und visible bias) in einem RBM. Dadurch unterscheiden sich RBMs von Autoencodern. Die versteckten RBM erzeugen die Aktivierung beim Vorwärtsdurchlauf, und die sichtbare Vorspannung hilft den RBM bei der Rekonstruktion der Eingabe während eines Rückwärtsdurchlaufs. Die rekonstruierte Eingabe unterscheidet sich immer von der tatsächlichen Eingabe, da es keine Verbindungen zwischen den sichtbaren Einheiten gibt und daher keine Möglichkeit, Informationen untereinander zu übertragen.

Das obige Bild zeigt den ersten Schritt beim Training eines RBM mit mehreren Eingaben. Die Eingänge werden mit den Gewichten multipliziert und dann zum Bias addiert. Das Ergebnis wird dann durch eine sigmoidale Aktivierungsfunktion geleitet, und die Ausgabe bestimmt, ob der versteckte Zustand aktiviert wird oder nicht. Die Gewichte sind eine Matrix mit der Anzahl der Eingabeknoten als Anzahl der Zeilen und der Anzahl der versteckten Knoten als Anzahl der Spalten. Der erste versteckte Knoten erhält die Vektormultiplikation der Eingaben multipliziert mit der ersten Spalte der Gewichte, bevor der entsprechende Bias-Term hinzugefügt wird.
Und falls Sie sich fragen, was eine Sigmoid-Funktion ist, hier ist die Formel:

Die Gleichung, die wir in diesem Schritt erhalten, wäre also,
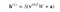
wobei h(1) und v(0) die entsprechenden Vektoren (Spaltenmatrizen) für die verborgene und die sichtbare Schicht sind, mit dem Hochkomma als Iteration (v(0) bedeutet die Eingabe, die wir dem Netzwerk zur Verfügung stellen) und a ist der Biasvektor der verborgenen Schicht.
(Beachten Sie, dass wir es hier mit Vektoren und Matrizen und nicht mit eindimensionalen Werten zu tun haben.)

Nun zeigt dieses Bild die umgekehrte Phase oder die Rekonstruktionsphase. Sie ist ähnlich wie der erste Durchgang, aber in umgekehrter Richtung. Die Gleichung lautet:
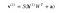
Leave a Reply