RL – DQN Deep Q-network

Os computadores podem jogar videojogos como um humano? Em 2015, a DQN venceu os peritos humanos em muitos jogos Atari. Mas uma vez que se trata de jogos complexos de estratégia de guerra, a IA não se sai bem. Em 2017, uma equipe de profissionais venceu facilmente um programa DeepMind AI no Starcraft 2.
Como citado no artigo do DeepMind:
É um problema multi-agente com múltiplos jogadores interagindo; há informação imperfeita devido a um mapa parcialmente observado; tem um grande espaço de ação envolvendo a seleção e controle de centenas de unidades; tem um grande espaço de estado que deve ser observado somente a partir de planos de recursos de entrada bruta; e tem atrasado a atribuição de créditos que requerem estratégias de longo prazo ao longo de milhares de passos.
Vamos reiniciar a nossa viagem de volta à Rede Q Profunda DQN. No jogo Seaquest abaixo, o DQN aprende a ler pontuações, a disparar contra o inimigo e a resgatar mergulhadores das imagens em bruto, tudo por si só. Descobre também conhecimentos que podemos referir como uma estratégia, como, quando levar o submarino à superfície para obter oxigénio.
>

>>
Q-learning aprende a função acção-valor Q(s, a): como é bom tomar uma acção num determinado estado. Por exemplo, para a posição do quadro abaixo, como é bom mover o peão dois passos à frente. Literalmente, atribuímos um valor escalar sobre o benefício de fazer tal movimento.
Q é chamado de função de valor de ação (ou função de valor Q neste artigo).

No Q-learning, construímos uma tabela de memória Q para armazenar valores Q para todas as combinações possíveis de s e a. Se você é um jogador de xadrez, ela é a folha de batota para o melhor movimento. No exemplo acima, podemos perceber que mover o peão 2 passos à frente tem os valores de Q mais altos sobre todos os outros. (O consumo de memória será demasiado elevado para o jogo de xadrez. Mas vamos continuar com esta abordagem um pouco mais.)
Técnico falando, nós experimentamos uma ação a partir do estado atual. Descobrimos a recompensa R (se houver) e o novo estado s’ (a nova posição do tabuleiro). Da tabela de memória, determinamos a próxima ação a’ a tomar que tem o máximo Q(s’, a’).
>
Num jogo de vídeo, marcamos pontos (recompensas) ao derrubar o inimigo. Em um jogo de xadrez, a recompensa é +1 quando ganhamos ou -1 se perdemos. Portanto, há apenas uma recompensa dada e leva um tempo para obtê-la.
Q-learning é sobre a criação da folha de batota Q.

Podemos dar um único movimento a e ver que recompensa R podemos obter. Isto cria uma visão de um passo à frente. R + Q(s’, a’) torna-se o alvo que queremos que o Q(s, a’) seja. Por exemplo, digamos que todos os valores de Q são iguais a um agora. Se movermos o joystick para a direita e marcarmos 2 pontos, queremos mover Q(s, a) mais perto de 3 (i.e. 2 + 1).
>
 >
>
>
Como continuamos a jogar, mantemos uma média de execução para Q. Os valores vão melhorar e com alguns truques, os valores de Q vão convergir.
Algoritmo de aprendizagem de Q
O algoritmo a seguir é o algoritmo para encaixar Q com as recompensas amostradas. Se γ (fator de desconto) for menor que um, há uma boa chance do Q convergir.

No entanto, se as combinações de estados e ações forem muito grandes, a necessidade de memória e de computação do Q será muito alta. Para resolver isso, mudamos para uma rede profunda Q (DQN) para aproximar Q(s, a). O algoritmo de aprendizagem é chamado de Aprendizagem Q Profunda. Com a nova abordagem, generalizamos a aproximação da função valor Q em vez de lembrar as soluções.
Que desafios a RL enfrenta em comparação com DL?
Na aprendizagem supervisionada, queremos que a entrada seja i.i.d. (independente e identicamente distribuída), ou seja
- Amostras são aleatórias entre lotes e, portanto, cada lote tem a mesma distribuição de dados (ou similar).
- As amostras são independentes umas das outras no mesmo lote.
Se não, o modelo pode ser montado em excesso para alguma classe (ou grupos) de amostras em tempos diferentes e a solução não será generalizada.
Além disso, para o mesmo input, sua etiqueta não muda com o tempo. Este tipo de condição estável para a entrada e saída fornece a condição para que a aprendizagem supervisionada tenha um bom desempenho.
Na aprendizagem de reforço, tanto a entrada como o alvo mudam constantemente durante o processo e tornam o treino instável.
Alvo instável: Construímos uma rede profunda para aprender os valores de Q mas os seus valores alvo estão a mudar à medida que conhecemos melhor as coisas. Como mostrado abaixo, os valores alvo de Q dependem do próprio Q, estamos perseguindo um alvo não estacionário.
>

i.i.d.: Há outro problema relacionado com as correlações dentro de uma trajetória. Dentro de uma iteração de treinamento, nós atualizamos os parâmetros do modelo para aproximar Q(s, a) da verdade do solo. Essas atualizações terão impacto em outras estimativas. Quando puxamos os valores Q na rede profunda, os valores Q nos estados circundantes serão puxados também como uma rede.

Digamos que apenas pontuamos uma recompensa e ajustamos a rede Q para refleti-la. A seguir, fazemos outro movimento. O novo estado será semelhante ao último em particular se usarmos imagens brutas para representar estados. O novo Q(s’, a’) recuperado será maior e nosso novo alvo para o Q se moverá mais alto também independentemente do mérito da nova ação. Se actualizarmos a rede com uma sequência de acções na mesma trajectória, o efeito será ampliado para além da nossa intenção. Isto desestabiliza o processo de aprendizagem e soa como cães perseguindo suas caudas.
Qual é o desafio fundamental no treinamento de RL? Em RL, muitas vezes dependemos das funções de política ou de valor para samplear ações. No entanto, isto está frequentemente a mudar, pois sabemos melhor o que explorar. À medida que jogamos o jogo, sabemos melhor sobre os valores da verdade dos estados e ações. Portanto, os nossos resultados-alvo também estão a mudar. Agora, tentamos aprender um mapeamento f para uma entrada e saída em constante mudança!
Felizmente, tanto a entrada como a saída podem convergir. Assim, se abrandarmos o suficiente as mudanças tanto no input como no output, podemos ter uma chance de modelar f enquanto permitimos que ele evolua.
Soluções
Repetição de experiência: Por exemplo, colocamos as últimas milhões de transições (ou quadros de vídeo) em um buffer e sampleamos um mini-batch de amostras de tamanho 32 deste buffer para treinar a rede profunda. Isto forma um conjunto de dados de entrada que é estável o suficiente para o treinamento. À medida que fazemos amostras aleatórias a partir do buffer de replay, os dados são mais independentes uns dos outros e mais próximos do i.i.d.
Target network: Criamos duas redes profundas θ- e θ. Usamos a primeira para recuperar os valores de Q enquanto a segunda inclui todas as atualizações no treinamento. Após 100.000 actualizações, sincronizamos θ- com θ. O objectivo é fixar temporariamente os valores Q para que não tenhamos um alvo móvel a perseguir. Além disso, as alterações de parâmetros não têm impacto imediato em θ- e, portanto, mesmo a entrada pode não ser 100% i.i.d., não irá aumentar incorretamente o seu efeito como mencionado anteriormente.

Com a repetição da experiência e da rede alvo, temos uma entrada e saída mais estável para treinar a rede e comportamo-nos mais como um treino supervisionado.
A repetição da experiência tem a maior melhoria de desempenho no DQN. A melhoria da rede alvo é significativa mas não tão crítica como a repetição. Mas torna-se mais importante quando a capacidade da rede é pequena.
Deep Q-learning with experience replay
Aqui está o algoritmo:
>

where ϕ pré-processar os últimos 4 frames de imagem para representar o estado. Para capturar o movimento, usamos quatro frames para representar um estado.
Pormenores de implementação
Perda de função
Vamos passar por mais alguns detalhes de implementação para melhorar o desempenho. DQN usa a perda Huber (curva verde) onde a perda é quadrática para valores pequenos de a, e linear para valores grandes.


A introdução da perda de Huber permite mudanças menos dramáticas que muitas vezes prejudicam a RL.
Optimização
O treinamento do RL é sensível aos métodos de otimização. O horário simples da taxa de aprendizagem não é dinâmico o suficiente para lidar com mudanças nas entradas durante o treinamento. Muitos treinamentos RL usam RMSProp ou Adam optimizer. O DQN é treinado com RMSProp. O uso do método de otimização avançada nos métodos Policy Gradient também é muito estudado.
ϵ-greedy
DQN usa ϵ-greedy para selecionar a primeira ação.
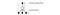
Para melhorar o treinamento, ϵ começa em 1 e passa a 0.1 ou 0,05 sobre o primeiro milhão de quadros usando a seguinte política.
>

onde m é o número de ações possíveis. No início do treinamento, selecionamos uniformemente as ações possíveis, mas à medida que o treinamento avança, selecionamos a ação ótima a* com mais freqüência. Isto permite uma exploração máxima no início que eventualmente muda para exploração.
Mas mesmo durante os testes, podemos manter ϵ a um valor pequeno como 0,05. Uma política determinística pode ficar presa em um ótimo local. Uma política não determinística permite-nos quebrar para uma chance de alcançar um melhor óptimo.

Arquitectura
Aqui está a arquitectura DQN. Pegamos os últimos 4 frames de vídeo anteriores e os alimentamos em camadas convolutivas seguidas por camadas totalmente conectadas para calcular os valores Q para cada ação.
>
 >
>
No exemplo abaixo, se não movermos a palheta para cima no frame 3, vamos perder a bola. Como esperado do DQN, o valor Q de mover a palheta para cima é muito maior em comparação com outras ações.


Improvimentos ao DQN
Muitas melhorias são feitas ao DQN. Nesta seção, mostraremos alguns métodos que demonstram melhorias significativas.
Dobrar DQN
Em Q-learning, usamos a seguinte fórmula para o valor alvo de Q.

No entanto, a operação máxima cria um viés positivo para as estimativas de Q.

Do exemplo acima, vemos que o Q(s, a) máximo é maior que o valor convergente 1.0. Ou seja, a operação máxima sobrestima Q. Por teoria e experimentos, o desempenho do DQN melhora se usarmos a rede online θ para selecionar a ação e a rede alvo θ- para estimar o valor Q.

Prioritized Experience Replay
DQN amostras transições do buffer de replay uniformemente. No entanto, devemos prestar menos atenção às amostras que já estão perto do alvo. Devemos amostrar as transições que têm uma grande lacuna no alvo:

Por isso, podemos selecionar transições do buffer
- com base no valor de erro acima (escolha transições com erro mais freqüente), ou
- classificá-las de acordo com o valor de erro e selecioná-las por classificação (escolha aquela com classificação mais freqüente).
Para detalhes sobre as equações dos dados de amostragem, por favor consulte o documento Prioritized Experience Replay.
Dueling DQN
Em Dueling DQN, Q é computado com uma fórmula diferente abaixo com a função de valor V e uma função de vantagem de ação dependente do estado A abaixo:

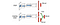
Em vez de aprender Q, usamos duas cabeças separadas para calcular V e A. As experiências empíricas mostram que o desempenho melhora. O DQN actualiza a função de valor Q de um estado apenas para uma acção específica. Dueling DQN atualiza V que outras atualizações de Q(s, a’) também podem tirar vantagem. Assim, cada iteração de treinamento de Dueling DQN é considerada como tendo um impacto maior.
Redes Ruído para Exploração
DQN usa ϵ-greedy para selecionar ações. Alternativamente, NoisyNet substitui-a adicionando ruído paramétrico à camada linear para ajudar na exploração. Em NoisyNet, ε-greedy não é utilizado. Ele usa um método ganancioso para selecionar ações da função de valor Q. Mas para as camadas totalmente conectadas do aproximador Q, nós adicionamos ruído paramétrico treinável abaixo para explorar as ações. Adicionar ruído a uma rede profunda é muitas vezes equivalente ou melhor do que adicionar ruído a uma acção como a do método de ϵ-greedy.
>

Outros pensamentos
DQN pertence a uma classe importante de RL, nomeadamente a aprendizagem de valores. Na prática, muitas vezes combinamos gradientes de políticas com métodos de value-learning na resolução de problemas da vida real.
Leave a Reply