Máquinas Boltzmann Restritas – Simplificadas
O que são máquinas Boltzmann Restritas?
RBMs são uma rede neural artificial de duas camadas com capacidades generativas. Eles têm a capacidade de aprender uma distribuição de probabilidade sobre seu conjunto de entrada. Os RBMs foram inventados por Geoffrey Hinton e podem ser usados para redução de dimensionalidade, classificação, regressão, filtragem colaborativa, aprendizagem de características, e modelagem de tópicos.
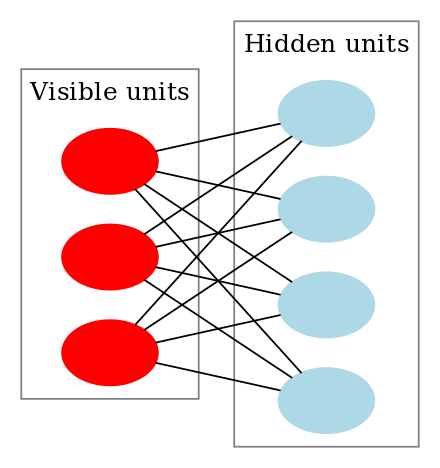
RBMs são uma classe especial de Máquinas Boltzmann e são restritas em termos de conexões entre as unidades visíveis e as unidades ocultas. Isto facilita a sua implementação quando comparado com as Máquinas Boltzmann. Como dito anteriormente, elas são uma rede neural de duas camadas (sendo uma a camada visível e a outra a camada oculta) e estas duas camadas são conectadas por um gráfico totalmente bipartido. Isto significa que cada nó da camada visível está conectado a cada nó da camada oculta, mas não há dois nós no mesmo grupo conectados um ao outro. Esta restrição permite algoritmos de treinamento mais eficientes do que os disponíveis para a classe geral das máquinas Boltzmann, em particular, o algoritmo de divergência contrastiva baseada no gradiente.
Uma Máquina Boltzmann Restrita se parece com isto:
>
Como funcionam as Máquinas Boltzmann Restritas?
Num RBM, temos um gráfico bipartido simétrico onde não há duas unidades dentro do mesmo grupo conectadas. Múltiplos RBMs também podem ser stacked e podem ser afinados através do processo de descida de gradiente e retropropagação. Tal rede é chamada de Rede de Crença Profunda. Embora RBMs sejam usadas ocasionalmente, a maioria das pessoas na comunidade de deep-learning começaram a substituir seu uso por Redes Adversariais Gerais ou Autocodificadores Variáveis.
RBM é uma Rede Neural Estocástica, o que significa que cada neurônio terá algum comportamento aleatório quando ativado. Existem duas outras camadas de unidades de polarização (polarização oculta e polarização visível) em uma RBM. Isto é o que torna as RBMs diferentes dos autoencoders. O viés oculto RBM produz a ativação no passe para frente e o viés visível ajuda o RBM a reconstruir a entrada durante um passe para trás. O input reconstruído é sempre diferente do input real, pois não há conexões entre as unidades visíveis e, portanto, nenhuma maneira de transferir informações entre elas.
>
 >
>
>
>
>
A imagem acima mostra o primeiro passo no treinamento de um RBM com múltiplos inputs. As entradas são multiplicadas pelos pesos e depois adicionadas ao viés. O resultado é então passado por uma função de ativação sigmóide e a saída determina se o estado oculto é ativado ou não. Os pesos serão uma matriz com o número de nós de entrada como o número de linhas e o número de nós ocultos como o número de colunas. O primeiro nó oculto receberá a multiplicação vetorial dos inputs multiplicados pela primeira coluna de pesos antes que o termo de polarização correspondente seja adicionado a ele.
E se você estiver se perguntando o que é uma função sigmóide, aqui está a fórmula:

>
>
>
Então a equação que obtemos neste passo seria,
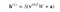
>
>
>
>
onde h(1) e v(0) são os vetores correspondentes (matrizes de colunas) para as camadas ocultas e visíveis com o superescrito como a iteração (v(0) significa a entrada que fornecemos para a rede) e a é o vetor de polarização da camada oculta.
(Note que estamos lidando com vetores e matrizes aqui e não valores unidimensionais.)
 >
>
>
>
Agora esta imagem mostra a fase reversa ou a fase de reconstrução. É semelhante à primeira passagem, mas em sentido contrário. A equação sai como:
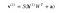 >
>>
>
>
>
Leave a Reply