Dados grandes aplicados: Spark vs Flink
>
 >
>>
>909>>
Apenas como o termo Inteligência Artificial (IA) tem sido desprezado por muitos anos, logo em 2017 ‘Big Data’ começa algo que gera mais rejeição do que aceitação devido ao desgaste diário e ao bombardeio. Tudo é Big Data e tudo se resolve com Big Data. Mas então, o que fazemos com aqueles que trabalham com Big Data?
Big Data tem sido relacionado nos últimos anos com grandes quantidades de dados estruturados ou não estruturados produzidos por sistemas ou organizações. A sua importância não está nos dados em si, mas no que podemos fazer com esses dados. Sobre como os dados podem ser analisados para tomar melhores decisões. Frequentemente, muito do valor que pode ser extraído dos dados vem da nossa capacidade de processá-los a tempo. Portanto, é importante conhecer muito bem tanto as fontes de dados como a estrutura em que os vamos processar.
Um dos objetivos iniciais em todos os projetos de Grandes Dados é definir a arquitetura de processamento que melhor se adapta a um problema específico. Isto inclui uma imensidão de possibilidades e alternativas:
- Quais são as fontes?
- Como os dados são armazenados?
- Existem algumas restrições computacionais? E do tempo?
- Que algoritmos devemos aplicar?
- Que precisão devemos alcançar?
- Como o processo é crítico?
Precisamos conhecer muito bem o nosso domínio para podermos responder a estas questões e fornecer respostas de qualidade. Ao longo deste post, vamos propor uma simplificação de um caso de uso real e comparar duas grandes tecnologias de processamento de dados.
O caso de uso proposto é a aplicação da arquitetura Kappa para processar traços de Netflow, usando diferentes motores de processamento.
Netflow é um protocolo de rede para coletar informações sobre tráfego IP. Ele nos fornece informações como as datas de início e fim das conexões, endereços IP de origem e destino, portas, protocolos, bytes de pacotes, etc. Ele é atualmente um padrão para monitorar o tráfego de rede e é suportado por diferentes plataformas de hardware e software.
Cada evento contido nos traços do netflow nos dá informações estendidas de uma conexão estabelecida na rede monitorada. Estes eventos são ingeridos através do Apache Kafka para serem analisados pelo motor de processamento – neste caso Apache Spark ou Apache Flink-, realizando uma operação simples como o cálculo da distância Euclidiana entre pares de eventos. Este tipo de cálculos são básicos em algoritmos de detecção de anomalias.
No entanto, para realizar este processamento é necessário agrupar os eventos, por exemplo através de janelas temporárias, uma vez que num contexto puramente de streaming os dados não têm um início ou um fim.
Após os eventos de fluxo líquido serem agrupados, o cálculo das distâncias entre pares produz uma explosão combinatória. Por exemplo, caso recebamos 1000 eventos/s do mesmo IP, e os agrupemos a cada 5s, cada janela irá requerer um total de 12.497.500 cálculos.
A estratégia a ser aplicada é totalmente dependente do motor de processamento. No caso do Spark, o agrupamento de eventos é simples, pois não funciona em streaming, mas utiliza micro-batching, portanto a janela de processamento será sempre definida. No caso do Flink, no entanto, este parâmetro não é obrigatório, uma vez que se trata de um motor de processamento puramente streaming, pelo que é necessário definir a janela de processamento desejada no código.
O cálculo retornará como resultado um novo fluxo de dados que é publicado noutro tópico Kafka, como se mostra na figura seguinte. Desta forma é alcançada uma grande flexibilidade no design, podendo-se combinar este processamento com outros em pipelines de dados mais complexos.

Kappa Architecture
A arquitectura Kappa é um padrão de arquitectura de software que utiliza fluxos de dados ou “streams” em vez de utilizar dados já armazenados e persistentes. As fontes de dados serão, portanto, imutáveis e contínuas, tais como as entradas geradas em um log. Estas fontes de informação contrastam com as bases de dados tradicionais utilizadas nos sistemas de análise de lotes ou batch.
Estes “fluxos” são enviados através de um sistema de processamento e armazenados em sistemas auxiliares para a camada de serviço.
A arquitectura Kappa é uma simplificação da arquitectura Lambda, da qual difere nos seguintes aspectos:
- Todos os dados são um fluxo (batch é um caso particular)
- As fontes de dados são imutáveis (dados brutos persistem)
- Existe um único framework analítico (benéfico para manutenção)
- Funcionalidade Replay, ou seja, reprocessando todos os dados analisados até agora (por exemplo, ao ter um novo algoritmo)
Em resumo, a parte do lote é eliminada, favorecendo um sistema de processamento de dados em movimento.
Sujar as mãos
Para compreender melhor todos estes conceitos teóricos, nada melhor do que aprofundar a implementação. Um dos elementos que queremos colocar em prática com esta prova de conceito é poder trocar entre os diferentes motores de processamento de forma transparente. Em outras palavras, quão fácil é trocar entre Spark e Flink com base no mesmo código Scala? Infelizmente, as coisas não são tão simples, embora seja possível chegar a uma solução parcial comum, como você pode ver nas seções seguintes.
eventos de Netflow
Cada evento de Netflow fornece informações sobre uma conexão específica estabelecida na rede. Estes eventos são representados no formato JSON e são ingeridos em Kafka. Para simplificar, somente conexões IPv4 serão usadas.
Exemplo de evento:
{
"eventid":995491697672682,
"dvc_version":"3.2",
"aproto":"failed",
"src_ip4":168099844,
"dst_ip4":4294967295,
"eventtime":1490024708,
"out_packets":1,
"type":"flow",
"dvc_time":1490024739,
"dst_ip":"255.255.255.255",
"src_ip":"10.5.0.4",
"duration":0,
"in_bytes":0,
"conn_state":"new",
"@version":"1",
"out_bytes":157,
"dvc_type":"suricata",
"in_packets":0,
"nproto":"UDP",
"src_port":42126,
"@timestamp":"2017-03-20T15:45:08.000Z",
"dst_port":40237,
"category":"informational"
}
Partilha parte
Como mencionado acima, um dos objetivos deste artigo é usar transparentemente diferentes ambientes de processamento de Grandes Dados , ou seja, usar as mesmas funções Scala para Spark, Flink ou futuros frameworks. Infelizmente, as peculiaridades de cada framework significam que apenas uma parte do código Scala implementado pode ser comum para ambos.
O código comum inclui os mecanismos para serializar e deserializar os eventos de netflow. Confiamos na biblioteca json4s do Scala, e definimos uma classe de caso com os campos de interesse:
case class Flow_ip4(eventid: String,
dst_ip4: String,
dst_port: String,
duration: String,
in_bytes: String,
in_packets: String,
out_bytes: String,
out_packets: String,
src_ip4: String,
src_port: String) extends Serializable
Além disso, o objeto Flow que implementa essa serialização é definido para poder trabalhar confortavelmente com diferentes mecanismos de Big Data:
class Flow(trace: String) extends Serializable {implicit val formats =DefaultFormatsvar flow_case : Flow_ip4 = parse(trace).extractdef getFlow() : Flow_ip4 = flow_case}
Outro código compartilhado por ambos os frameworks são as funções para calcular a distância euclidiana, obter as combinações de uma série de objetos e gerar o Json de resultados:
object utils { def euclideanDistance(xs: List, ys: List) = {
sqrt((xs zip ys).map { case (x,y)=> pow(y - x, 2) }.sum)
} def getCombinations(lists : Iterable) = {
lists.toList.combinations(2).map(x=> (x(0),x(1))).toList
} def getAllValuesFromString(flow_case : Flow_ip4) = flow_case.productIterator.drop(1)
.map(_.asInstanceOf.toDouble).toList def calculateDistances(input: Iterable): List = {
val combinations: List = getCombinations(input)
val distances = combinations.map{
case(f1,f2) => (f1.eventid,f2.eventid,euclideanDistance(getAllValuesFromString(f1),
getAllValuesFromString(f2)))}
distances.sortBy(_._3)
} def generateJson(x: (String, String, Double)): String = {
val obj = Map("eventid_1" -> x._1,
"eventid_2" -> x._2,
"distance" -> x._3,
"timestamp" -> System.currentTimeMillis())
val str_obj = scala.util.parsing.json.JSONObject(obj).toString()
str_obj
}
}
Parte específica de cada framework
A aplicação de transformações e ações é onde as particularidades de cada framework impedem que ele seja um código genérico.
Como observado, Flink itera por cada evento, filtrando, serializando, agrupando por IP e tempo e finalmente aplicando cálculo de distância para enviá-lo para Kafka através de um produtor.
Em Spark, por outro lado, como os eventos já estão agrupados por tempo, só precisamos filtrar, serializar e agrupar por IP. Feito isso, as funções de cálculo de distância são aplicadas e o resultado pode ser enviado para Kafka com as bibliotecas apropriadas.
Para Flink:
val flow = stream
.filter(!_.contains("src_ip6"))
.map(trace =>{
new Flow(trace).getFlow()
})
.keyBy(_.src_ip4)
.timeWindow(Time.seconds(3))
.apply{(
key: String,
window: TimeWindow,
input: Iterable,
out: Collector]) => {
val distances: List = utils.calculateDistances(input)
out.collect(distances)
}
}
.flatMap(x => x)
flow.map( x=>{
val str_obj: String = utils.generateJson(x)
producer.send(new ProducerRecord(topic_out, str_obj))
})
Para Spark:
val flow = stream.map(_.value())
.filter(!_.contains("src_ip6"))
.map(record => {
implicit val formats = DefaultFormats
val flow = new Flow(record).getFlow()
(flow.src_ip4,flow)
})
.groupByKey()flow.foreachRDD(rdd => {
rdd.foreach{ case (key, input ) => {
val distances = utils.calculateDistances(input)
distances.map(x => {val str_obj: String = utils.generateJson(x)
producer.send(new ProducerRecord(topic_out, str_obj))
})
}}
})
Os IDs de cada evento, seus timestamps de ingestão, o resultado do cálculo de distância e o tempo em que o cálculo foi concluído são armazenados no tópico de saída de Kafka. Aqui está um exemplo de um traço:
{
"eventid_1":151852746453199,
"ts_flow1":1495466510792,
"eventid_2":1039884491535740,
"ts_flow2":1495466511125,
"distance":12322.94295207115,
"ts_output":1495466520212
}
Resultados
Executámos dois tipos diferentes de testes: múltiplos eventos numa única janela, e múltiplos eventos em janelas diferentes, onde um fenómeno torna o algoritmo combinatório aparentemente estocástico e oferece resultados diferentes. Isto ocorre devido ao fato de que os dados são ingeridos de forma desordenada, à medida que chegam ao sistema, sem levar em conta a hora do evento, e os agrupamentos são feitos com base nele, o que fará com que existam diferentes combinações.
A seguinte apresentação do Apache Beam explica com mais detalhes a diferença entre o tempo de processamento e a hora do evento: https://goo.gl/h5D1yR

Eventos múltiplos na mesma janela
Sobre 10.000 eventos são ingeridos na mesma janela, que, aplicando as combinações para os mesmos IPs, requerem quase 2 milhões de cálculos. O tempo total de cálculo em cada framework (ou seja, a diferença entre o maior e o menor timestamp de saída) com 8 núcleos de processamento é:
- Tempo total do Park: 41,50s
- Total time Flink: 40,24s
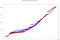
Linhas múltiplas da mesma cor são devidas ao paralelismo, uma vez que existem cálculos que terminam ao mesmo tempo.
Eventos múltiplos em janelas diferentes
Mais de 50.000 eventos são inseridos ao longo de janelas de tempo diferentes de 3s. É aqui que as particularidades de cada motor surgem claramente. Quando traçamos o mesmo gráfico de tempos de processamento, ocorre o seguinte:
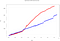
- Tempo total do Park: 614,1s
- Tempo total do Flink: 869,3s
Observamos um aumento no tempo de processamento do Flink. Isto é devido à forma como ele ingere eventos:

Como visto na última figura, Flink não usa micro-batches e paralela a janela do evento (ao contrário de Spark, ele usa janelas deslizantes sobrepostas). Isto causa um tempo de computação maior, mas menor tempo de ingestão. É uma das particularidades que devemos levar em conta ao definir nossa arquitetura de processamento de dados em streaming Big Data.
E quanto ao cálculo?
A distância euclidiana de 10.000 eventos tem a seguinte distribuição:

Assume-se que eventos anômalos estão na “cauda longa” do histograma. Mas será que isso faz realmente sentido? Vamos analisá-lo.
Neste caso, certos parâmetros categóricos (IP, porta) estão sendo considerados como numéricos para o cálculo. Decidimos fazer isso para aumentar a dimensionalidade e nos aproximarmos de um problema real. Mas é isto que obtemos quando mostramos todos os valores reais das distâncias:

Ou seja, ruído, uma vez que estes valores (IP, porto, origem e destino) distorcem o cálculo. Entretanto, quando eliminamos estes campos e processamos tudo novamente, mantendo:
- duração
- in_bytes
- in_packets
- out_bytes
- out_packets
- out_packets
Obtemos a seguinte distribuição:

>
>909>
A cauda longa já não está tão povoada e há algum pico no final. Se mostrarmos os valores do cálculo da distância, podemos ver onde estão os valores anômalos.

Graças a este simples refinamento facilitamos o trabalho do analista, oferecendo-lhe uma ferramenta poderosa, poupando tempo e apontando onde encontrar os problemas de uma rede.
Conclusões
Embora uma infinidade de possibilidades e conclusões pudesse ser discutida, o conhecimento mais notável obtido ao longo deste pequeno desenvolvimento é:
- Estrutura de processamento. Não é trivial passar de um framework para outro, por isso é importante desde o início decidir qual framework vai ser utilizado e conhecer muito bem as suas particularidades. Por exemplo, se precisarmos processar um evento instantaneamente e isso for crítico para o negócio, devemos selecionar um mecanismo de processamento que atenda a esse requisito.
- Big Picture. Para certos recursos, um motor se destacará sobre outros, mas o que você está disposto a sacrificar para obter este ou aquele recurso?
- Uso de recursos. Gerenciamento de memória, CPU, disco… É importante aplicar testes de estresse, benchmarks, etc. ao sistema para saber como ele se comportará como um todo e identificar possíveis pontos fracos e gargalos
- Características e contexto. É essencial ter sempre em conta o contexto específico e saber quais as características que devem ser introduzidas no sistema. Temos utilizado parâmetros como portas ou IPs no cálculo das distâncias para tentar detectar anomalias em uma rede. Estas características, apesar de serem numéricas, não têm um sentido espacial entre elas. No entanto, existem formas de aproveitar este tipo de dados, mas deixamos para um futuro post.
Este post foi publicado originalmente em https://www.gradiant.org/noticia/big-data-aplicado-spark-vs-flink/
Agradecimentos a Adrián Portabales ( adrianp )
Leave a Reply