RL – DQN Deep Q-network

Czy komputery mogą grać w gry wideo jak człowiek? W 2015 roku, DQN pokonał ludzkich ekspertów w wielu grach Atari. Ale gdy przychodzi do złożonych wojennych gier strategicznych, AI nie radzi sobie dobrze. W 2017 roku profesjonalny zespół z łatwością pokonał program DeepMind AI w Starcraft 2.
Jak zacytowano z papieru DeepMind:
Jest to problem wieloagentowy z wieloma graczami wchodzącymi w interakcję; istnieje niedoskonała informacja ze względu na częściowo obserwowaną mapę; ma dużą przestrzeń działań obejmującą wybór i kontrolę setek jednostek; ma dużą przestrzeń stanu, która musi być obserwowana wyłącznie z surowych wejściowych płaszczyzn cech; i ma opóźnione przydzielanie kredytów wymagające długoterminowych strategii w ciągu tysięcy kroków.
Rozpocznijmy naszą podróż z powrotem do Deep Q-Network DQN. W poniższej grze Seaquest, DQN uczy się, jak odczytywać wyniki, strzelać do wroga i ratować nurków z surowych obrazów, a wszystko to samodzielnie. Odkrywa również wiedzę, którą możemy określić jako strategię, np. kiedy wypłynąć łodzią podwodną na powierzchnię po tlen.

Q-learning uczy się funkcji wartości akcji Q(s, a): jak dobrze podjąć akcję w danym stanie. Na przykład, dla poniższej pozycji na planszy, jak dobrze jest przesunąć pionek o dwa kroki do przodu. Dosłownie, przypisujemy wartość skalarną do korzyści z wykonania takiego ruchu.
Q nazywamy funkcją wartości akcji (lub funkcją wartości Q w tym artykule).

W uczeniu Q budujemy tablicę pamięci Q do przechowywania wartości Q dla wszystkich możliwych kombinacji s i a. Jeśli jesteś szachistą, jest to arkusz szachowy dla najlepszego ruchu. W powyższym przykładzie, możemy zdać sobie sprawę, że przesunięcie pionka o 2 kroki do przodu ma najwyższą wartość Q w stosunku do wszystkich innych. (Zużycie pamięci będzie zbyt duże dla gry w szachy. Ale pozostańmy przy tym podejściu trochę dłużej.)
Technicznie rzecz biorąc, próbkujemy akcję z bieżącego stanu. Poznajemy nagrodę R (jeśli istnieje) i nowy stan s’ (nową pozycję na planszy). Z tablicy pamięci wyznaczamy następną akcję a’, która ma maksymalną wartość Q(s’, a’).
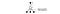
W grze wideo zdobywamy punkty (nagrody) zestrzeliwując przeciwnika. W grze w szachy nagrodą jest +1, gdy wygrywamy lub -1, gdy przegrywamy. Jest więc tylko jedna nagroda i jej zdobycie zajmuje trochę czasu.
Q-learning polega na stworzeniu arkusza oszukania Q.

Możemy wykonać pojedynczy ruch a i zobaczyć jaką nagrodę R możemy otrzymać. Tworzy to jednokrokowe spojrzenie w przyszłość. R + Q(s’, a’) staje się celem, którym chcemy, aby było Q(s, a). Na przykład, powiedzmy, że wszystkie wartości Q są teraz równe jeden. Jeśli przesuniemy joystick w prawo i zdobędziemy 2 punkty, chcemy zbliżyć Q(s, a) do 3 (tj. 2 + 1).

Grając dalej, utrzymujemy bieżącą średnią dla Q. Wartości te będą coraz lepsze, a przy zastosowaniu pewnych sztuczek, wartości Q będą zbieżne.
Algorytm uczenia Q
Poniżej przedstawiono algorytm dopasowywania Q do próbkowanych nagród. Jeśli γ (współczynnik dyskonta) jest mniejszy od jednego, istnieje duża szansa, że Q jest zbieżne.

Jeśli jednak kombinacje stanów i akcji są zbyt duże, pamięć i wymagania obliczeniowe dla Q będą zbyt duże. Aby temu zaradzić, przechodzimy na głęboką sieć Q (DQN), aby aproksymować Q(s, a). Algorytm uczenia nazywamy uczeniem głębokiej sieci Q (Deep Q-learning). Dzięki nowemu podejściu uogólniamy aproksymację funkcji wartości Q, zamiast zapamiętywać rozwiązania.
Jakie wyzwania stoją przed RL w porównaniu z DL?
W uczeniu nadzorowanym chcemy, aby dane wejściowe były i.i.d. (independent and identically distributed), czyli
- Próbki są randomizowane pomiędzy partiami i dlatego każda partia ma taki sam (lub podobny) rozkład danych.
- Próbki są niezależne od siebie w tej samej partii.
Jeśli nie, model może być przepasowany dla pewnej klasy (lub grup) próbek w różnym czasie i rozwiązanie nie będzie uogólnione.
Dodatkowo, dla tego samego wejścia, jego etykieta nie zmienia się w czasie. Ten rodzaj stabilnego warunku dla wejścia i wyjścia zapewnia warunek, aby uczenie nadzorowane działało dobrze.
W uczeniu wzmacniającym zarówno dane wejściowe, jak i cel zmieniają się stale podczas procesu i sprawiają, że szkolenie jest niestabilne.
Target unstable: Budujemy głęboką sieć, aby nauczyć się wartości Q, ale jej wartości docelowe zmieniają się w miarę jak lepiej poznajemy rzeczy. Jak widać poniżej, wartości docelowe dla Q zależą od samego Q, ścigamy niestacjonarny cel.

i.i.d.: Istnieje inny problem związany z korelacjami wewnątrz trajektorii. W ramach iteracji treningowej aktualizujemy parametry modelu, aby zbliżyć Q(s, a) do prawdy o terenie. Te aktualizacje będą miały wpływ na inne estymacje. Kiedy podciągamy wartości Q w głębokiej sieci, wartości Q w otaczających stanach również zostaną podciągnięte, jak sieć.

Powiedzmy, że właśnie zdobyliśmy nagrodę i dostosowujemy sieć Q, aby to odzwierciedlić. Następnie wykonujemy kolejny ruch. Nowy stan będzie wyglądał podobnie do ostatniego, zwłaszcza jeśli do reprezentacji stanów użyjemy surowych obrazów. Nowo odzyskane Q(s’, a’) będzie wyższe, a nasz nowy cel dla Q przesunie się wyżej również bez względu na wartość nowej akcji. Jeśli zaktualizujemy sieć za pomocą sekwencji działań na tej samej trajektorii, powiększy to efekt poza naszą intencję. To destabilizuje proces uczenia się i brzmi jak psy goniące swój ogon.
Jakie jest podstawowe wyzwanie w treningu RL? W RL, często polegamy na polityce lub funkcjach wartości do próbkowania działań. Jednakże, to się często zmienia, ponieważ wiemy lepiej co badać. W miarę jak gramy w grę, lepiej poznajemy prawdziwe wartości stanów i akcji. Tak więc nasze docelowe dane wyjściowe również się zmieniają. Teraz próbujemy nauczyć się odwzorowania f dla ciągle zmieniających się danych wejściowych i wyjściowych!
Na szczęście zarówno dane wejściowe, jak i wyjściowe mogą być zbieżne. Jeśli więc wystarczająco spowolnimy zmiany na wejściu i wyjściu, możemy mieć szansę na modelowanie f, pozwalając mu ewoluować.
Rozwiązania
Odtwarzanie doświadczeń: Przykładowo, umieszczamy ostatni milion przejść (lub klatek wideo) w buforze i z tego bufora próbkujemy mini partię próbek o rozmiarze 32 w celu wytrenowania sieci głębokiej. To tworzy wejściowy zbiór danych, który jest wystarczająco stabilny do treningu. Ponieważ losowo próbkujemy z bufora powtórek, dane są bardziej niezależne od siebie i bliższe i.i.d.
Sieć docelowa: Tworzymy dwie głębokie sieci θ- i θ. Używamy pierwszej z nich do pobierania wartości Q, podczas gdy druga uwzględnia wszystkie aktualizacje w treningu. Po powiedzmy 100 000 aktualizacji, synchronizujemy θ- z θ. Celem jest tymczasowe ustalenie celów wartości Q, abyśmy nie mieli ruchomego celu do ścigania. Dodatkowo, zmiany parametrów nie wpływają na θ- natychmiastowo i dlatego nawet dane wejściowe mogą nie być w 100% i.i.d., nie spowoduje to nieprawidłowego powiększenia jego efektu, jak wspomniano wcześniej.

Dzięki zarówno powtórzeniu doświadczenia, jak i sieci docelowej, mamy bardziej stabilne wejście i wyjście do trenowania sieci i zachowuje się ona bardziej jak szkolenie nadzorowane.
Odtwarzanie doświadczenia ma największą poprawę wydajności w DQN. Poprawa sieci docelowej jest znacząca, ale nie tak krytyczna jak powtórka. Ale staje się ważniejsza, gdy pojemność sieci jest mała.
Deep Q-learning with experience replay
Oto algorytm:

gdzie ϕ wstępnie przetwarzamy ostatnie 4 klatki obrazu, aby reprezentować stan. Aby uchwycić ruch, używamy czterech klatek do reprezentowania stanu.
Szczegóły implementacji
Funkcja straty
Przejrzyjmy się jeszcze kilku szczegółom implementacji, aby poprawić wydajność. DQN używa straty Hubera (zielona krzywa), gdzie strata jest kwadratowa dla małych wartości a, i liniowa dla dużych wartości.


Wprowadzenie straty Hubera pozwala na mniej drastyczne zmiany, które często szkodzą RL.
Optymalizacja
Trening RL jest wrażliwy na metody optymalizacji. Prosty harmonogram szybkości uczenia nie jest wystarczająco dynamiczny, aby poradzić sobie ze zmianami danych wejściowych podczas treningu. Wiele szkoleń RL używa RMSProp lub optymalizatora Adam. DQN jest trenowany za pomocą RMSProp. Użycie zaawansowanej metody optymalizacji w metodach gradientowych jest również intensywnie badane.
ϵ-greedy
DQN używa ϵ-greedy do wyboru pierwszej akcji.
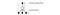
Aby poprawić trening, ϵ zaczyna się od 1 i anneal do 0.1 lub 0.05 przez pierwszy milion klatek używając następującej polityki.

gdzie m jest liczbą możliwych akcji. Na początku szkolenia wybieramy równomiernie możliwe akcje, ale w miarę postępu szkolenia częściej wybieramy optymalną akcję a*. Pozwala to na maksymalną eksplorację na początku, która ostatecznie przechodzi w eksploatację.
Ale nawet podczas testowania, możemy utrzymać ϵ na małej wartości jak 0.05. Polityka deterministyczna może utknąć w lokalnym optimum. Polityka niedeterministyczna pozwala nam wyrwać się na szansę osiągnięcia lepszego optimum.

Architektura
Oto architektura DQN. Bierzemy 4 ostatnie klatki wideo i wprowadzamy je do warstw konwolucyjnych, a następnie w pełni połączonych warstw, aby obliczyć wartości Q dla każdej akcji.

W poniższym przykładzie, jeśli nie przesuniemy łopatki w górę na klatce 3, nie trafimy w piłkę. Jak można się spodziewać po DQN, wartość Q przesunięcia łopatki do góry jest znacznie wyższa w porównaniu z innymi działaniami.


Ulepszenia DQN
Wiele ulepszeń zostało wprowadzonych do DQN. W tej sekcji pokażemy kilka metod, które pokazują znaczące ulepszenia.
Double DQN
W uczeniu Q, używamy następującego wzoru na wartość docelową dla Q.

Jednakże operacja max tworzy pozytywną stronniczość w stosunku do estymacji Q.

Z powyższego przykładu widzimy, że max Q(s, a) jest wyższe niż wartość zbieżna 1.0. tzn. operacja max przeszacowuje Q. Teoria i eksperymenty pokazują, że wydajność DQN poprawia się, jeśli używamy sieci online θ do chciwego wyboru akcji i sieci docelowej θ- do oszacowania wartości Q.

Prioritized Experience Replay
DQN równomiernie próbkuje przejścia z bufora powtórek. Powinniśmy jednak zwracać mniejszą uwagę na próbki, które są już blisko celu. Powinniśmy próbkować przejścia, które mają duży odstęp od celu:

W związku z tym możemy wybierać przejścia z bufora
- na podstawie wartości błędu powyżej (częściej wybierać przejścia z większym błędem), lub
- uszeregować je według wartości błędu i wybierać według rangi (częściej wybierać te z większą rangą).
Szczegóły równań dotyczących próbkowania danych można znaleźć w dokumencie Prioritized Experience Replay.
Dueling DQN
W Dueling DQN, Q jest obliczane za pomocą innej formuły poniżej z funkcją wartości V i zależną od stanu funkcją przewagi akcji A poniżej:

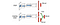
Zamiast uczyć Q, używamy dwóch oddzielnych głowic do obliczania V i A. Eksperymenty empiryczne pokazują poprawę wydajności. DQN aktualizuje funkcję wartości Q stanu tylko dla określonej akcji. Dueling DQN aktualizuje V, z którego mogą korzystać również inne aktualizacje Q(s, a’). Tak więc każda iteracja szkolenia Dueling DQN ma większy wpływ.
Noisy Nets for Exploration
DQN używa ϵ-greedy do wyboru działań. Alternatywnie, NoisyNet zastępuje ją poprzez dodanie parametrycznego szumu do warstwy liniowej, aby wspomóc eksplorację. W NoisyNet, ε-greedy nie jest używana. Używa on metody zachłannej do wyboru działań z funkcji wartości Q. Ale dla w pełni połączonych warstw aproksymatora Q, dodajemy trenowalny szum parametryczny poniżej, aby zbadać działania. Dodanie szumu do głębokiej sieci jest często równoważne lub lepsze niż dodanie szumu do akcji, jak w metodzie ϵ-greedy.

Więcej myśli
DQN należy do jednej z ważnych klas RL, a mianowicie uczenia wartości. W praktyce często łączymy gradienty polityki z metodami uczenia wartości w rozwiązywaniu rzeczywistych problemów.
.
Leave a Reply