Kwartet Anscombe’a
Zawsze wierzyłem w „obliczenia numeryczne są dokładne, ale wykresy są szorstkie”. Pochodząc od osoby, która dopiero zaczęła uczyć się analityki danych, trudno było mi zrozumieć znaczenie wizualizacji danych wraz z podsumowującymi statystykami. Ale to wszystko zmieniło się po uczestnictwie w Data Visualization Meetup, kiedy to zostałem wprowadzony do Kwartetu Anscombe’a.
Kwartet Anscombe’a został opracowany przez statystyka Francisa Anscombe’a. Składa się on z czterech zestawów danych, z których każdy zawiera jedenaście par (x,y). Najważniejszą rzeczą, którą należy zauważyć w tych zestawach danych jest to, że mają one te same statystyki opisowe. Ale wszystko zmienia się całkowicie, i muszę podkreślić KOMPLETNIE, gdy zestawi się je na wykresach. Każdy wykres opowiada inną historię, niezależnie od podobnych statystyk zbiorczych.
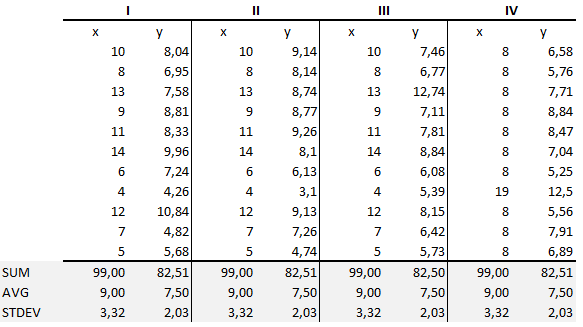
Statystyki zbiorcze pokazują, że średnie i wariancje były identyczne dla x i y we wszystkich grupach :
- Średnia x wynosi 9, a średnia y wynosi 7.50 dla każdego zestawu danych.
- Podobnie, wariancja x wynosi 11, a wariancja y wynosi 4.13 dla każdego zestawu danych
- Współczynnik korelacji (jak silny jest związek między dwiema zmiennymi) między x i y wynosi 0.816 dla każdego zestawu danych
Gdy wykreślimy te cztery zestawy danych na płaszczyźnie współrzędnych x/y, możemy zaobserwować, że pokazują one te same linie regresji, ale każdy zestaw danych opowiada inną historię:

- Zbiór danych I wydaje się mieć czyste i dobrze dopasowane modele liniowe.
- Zbiór danych II nie ma rozkładu normalnego.
- W zbiorze danych III rozkład jest liniowy, ale obliczona regresja jest zaburzona przez wartość odstającą.
- Zbiór danych IV pokazuje, że wystarczy jedna wartość odstająca, aby uzyskać wysoki współczynnik korelacji.
Ten kwartet podkreśla znaczenie wizualizacji w analizie danych. Spojrzenie na dane ujawnia wiele ze struktury i jasny obraz zbioru danych.
Komputer powinien wykonywać zarówno obliczenia jak i wykresy. Oba rodzaje danych wyjściowych powinny być badane; każdy z nich przyczyni się do zrozumienia.
.
Leave a Reply