Big Data applied: Spark vs Flink

Tak jak termin sztuczna inteligencja (AI) jest pogardzany od wielu lat, zaraz w 2017 roku „Big Data” zaczyna być czymś, co generuje więcej odrzucenia niż akceptacji ze względu na codzienne zużycie i bombardowanie. Wszystko jest Big Data i wszystko jest rozwiązywane za pomocą Big Data. Ale wtedy, co robimy tych, którzy pracują na Big Data?
Big Data została związana w ostatnich latach do dużych ilości ustrukturyzowanych lub nieustrukturyzowanych danych produkowanych przez systemy lub organizacje. Jego znaczenie nie leży w samych danych, ale w tym, co możemy zrobić z tymi danymi. Na tym, jak dane mogą być analizowane w celu podejmowania lepszych decyzji. Często, duża część wartości, którą można wydobyć z danych pochodzi z naszej zdolności do przetwarzania ich w czasie. Dlatego ważne jest, aby bardzo dobrze znać zarówno źródła danych, jak i ramy, w których będziemy je przetwarzać.
Jednym z początkowych celów we wszystkich projektach Big Data jest zdefiniowanie architektury przetwarzania, która najlepiej dostosuje się do konkretnego problemu. Wiąże się to z ogromem możliwości i alternatyw:
- Jakie są źródła?
- Jak przechowywane są dane?
- Czy istnieją ograniczenia obliczeniowe? I czasowe?
- Jakie algorytmy powinniśmy zastosować?
- Jaką dokładność powinniśmy osiągnąć?
- Jak krytyczny jest to proces?
Musimy bardzo dobrze znać naszą domenę, aby móc odpowiedzieć na te pytania i dostarczyć wysokiej jakości odpowiedzi. W tym poście zaproponujemy uproszczenie rzeczywistego przypadku użycia i porównamy dwie technologie przetwarzania Big Data.
Proponowanym przypadkiem użycia jest zastosowanie architektury Kappa do przetwarzania śladów Netflow, przy użyciu różnych silników przetwarzania.
Netflow jest protokołem sieciowym służącym do zbierania informacji o ruchu IP. Dostarcza nam takich informacji jak daty rozpoczęcia i zakończenia połączeń, źródłowe i docelowe adresy IP, porty, protokoły, bajty pakietów itp. Jest to obecnie standard monitorowania ruchu sieciowego i jest obsługiwany przez różne platformy sprzętowe i programowe.
Każde zdarzenie zawarte w śladach netflow daje nam rozszerzoną informację o połączeniu nawiązanym w monitorowanej sieci. Zdarzenia te są pobierane poprzez Apache Kafka, aby następnie zostać przeanalizowane przez silnik przetwarzający – w tym przypadku Apache Spark lub Apache Flink – wykonujący proste operacje, takie jak obliczenie odległości euklidesowej pomiędzy parami zdarzeń. Tego typu obliczenia są podstawowe w algorytmach wykrywania anomalii.
Jednakże, aby przeprowadzić takie przetwarzanie, konieczne jest pogrupowanie zdarzeń, np. poprzez okna tymczasowe, ponieważ w kontekście czysto strumieniowym dane nie mają początku ani końca.
Po pogrupowaniu zdarzeń netflow, obliczanie odległości pomiędzy parami powoduje eksplozję kombinatoryczną. Na przykład, w przypadku, gdy otrzymujemy 1000 zdarzeń / s z tego samego IP i grupujemy je co 5s, każde okno będzie wymagało w sumie 12 497 500 obliczeń.
Strategia, którą należy zastosować, jest całkowicie zależna od silnika przetwarzania. W przypadku Sparka grupowanie zdarzeń jest proste, ponieważ nie działa on w strumieniowaniu, a zamiast tego wykorzystuje mikropatching, więc okno przetwarzania zawsze będzie zdefiniowane. Natomiast w przypadku Flink parametr ten nie jest obowiązkowy, ponieważ jest to silnik czysto strumieniowy, więc konieczne jest zdefiniowanie pożądanego okna przetwarzania w kodzie.
Wyliczenie zwróci jako wynik nowy strumień danych, który zostanie opublikowany w innym temacie Kafka, jak pokazano na poniższym rysunku. W ten sposób osiąga się dużą elastyczność w projekcie, mogąc połączyć to przetwarzanie z innymi w bardziej złożonych potokach danych.

Architektura Kappa
Architektura Kappa jest wzorcem architektury oprogramowania, który wykorzystuje strumienie danych lub „strumienie” zamiast korzystania z danych już przechowywanych i utrzymywanych. Źródła danych będą zatem niezmienne i ciągłe, takie jak wpisy generowane w dzienniku. Te źródła informacji kontrastują z tradycyjnymi bazami danych stosowanymi w systemach analizy wsadowej lub batchowej.
Te „strumienie” są przesyłane przez system przetwarzania i przechowywane w systemach pomocniczych dla warstwy usługowej.
Architektura Kappa jest uproszczeniem architektury Lambda, od której różni się w następujących aspektach:
- Wszystko jest strumieniem (batch jest szczególnym przypadkiem)
- Źródła danych są niezmienne (surowe dane persystują)
- Istnieje jeden framework analityczny (korzystne dla utrzymania)
- Funkcjonalność reprolay, czyli ponowne przetwarzanie wszystkich danych analizowanych do tej pory (na przykład, gdy mamy nowy algorytm)
Podsumowując, część wsadowa jest wyeliminowana, co sprzyja systemowi przetwarzania danych w ruchu.
Get our hands dirty
Aby lepiej zrozumieć wszystkie te teoretyczne koncepcje, nie ma nic lepszego niż pogłębienie implementacji. Jednym z elementów, które chcemy zastosować w praktyce w tym proof of concept, jest możliwość wymiany pomiędzy różnymi silnikami przetwarzania w przejrzysty sposób. Innymi słowy, jak łatwo jest przełączać się pomiędzy Sparkiem i Florkiem w oparciu o ten sam kod Scali? Niestety, sprawy nie są takie proste, chociaż możliwe jest osiągnięcie wspólnego częściowego rozwiązania, jak można zobaczyć w następujących sekcjach.
Zdarzenia Netflow
Każde zdarzenie Netflow dostarcza informacji o konkretnym połączeniu nawiązanym w sieci. Zdarzenia te są reprezentowane w formacie JSON i są pobierane do Kafki. Dla uproszczenia zostaną wykorzystane tylko połączenia IPv4.
Przykład zdarzenia:
{
"eventid":995491697672682,
"dvc_version":"3.2",
"aproto":"failed",
"src_ip4":168099844,
"dst_ip4":4294967295,
"eventtime":1490024708,
"out_packets":1,
"type":"flow",
"dvc_time":1490024739,
"dst_ip":"255.255.255.255",
"src_ip":"10.5.0.4",
"duration":0,
"in_bytes":0,
"conn_state":"new",
"@version":"1",
"out_bytes":157,
"dvc_type":"suricata",
"in_packets":0,
"nproto":"UDP",
"src_port":42126,
"@timestamp":"2017-03-20T15:45:08.000Z",
"dst_port":40237,
"category":"informational"
}
Część współdzielona
Jak wspomniano powyżej, jednym z celów tego artykułu jest przejrzyste korzystanie z różnych środowisk przetwarzania Big Data , czyli wykorzystanie tych samych funkcji Scali dla Sparka, Flinka lub przyszłych frameworków. Niestety, specyfika każdego z tych frameworków sprawiła, że tylko część zaimplementowanego kodu Scali może być wspólna dla obu tych środowisk.
Wspólny kod obejmuje mechanizmy serializacji i deserializacji zdarzeń netflow. Opieramy się na bibliotece json4s w Scali i definiujemy klasę case z interesującymi nas polami:
case class Flow_ip4(eventid: String,
dst_ip4: String,
dst_port: String,
duration: String,
in_bytes: String,
in_packets: String,
out_bytes: String,
out_packets: String,
src_ip4: String,
src_port: String) extends Serializable
Dodatkowo obiekt Flow, który implementuje tę serializację, jest zdefiniowany tak, aby mógł wygodnie współpracować z różnymi silnikami Big Data:
class Flow(trace: String) extends Serializable {implicit val formats =DefaultFormatsvar flow_case : Flow_ip4 = parse(trace).extractdef getFlow() : Flow_ip4 = flow_case}
Innym kodem wspólnym dla obu frameworków są funkcje obliczające odległość euklidesową, uzyskujące kombinacje serii obiektów oraz generujące Json wyników:
object utils { def euclideanDistance(xs: List, ys: List) = {
sqrt((xs zip ys).map { case (x,y)=> pow(y - x, 2) }.sum)
} def getCombinations(lists : Iterable) = {
lists.toList.combinations(2).map(x=> (x(0),x(1))).toList
} def getAllValuesFromString(flow_case : Flow_ip4) = flow_case.productIterator.drop(1)
.map(_.asInstanceOf.toDouble).toList def calculateDistances(input: Iterable): List = {
val combinations: List = getCombinations(input)
val distances = combinations.map{
case(f1,f2) => (f1.eventid,f2.eventid,euclideanDistance(getAllValuesFromString(f1),
getAllValuesFromString(f2)))}
distances.sortBy(_._3)
} def generateJson(x: (String, String, Double)): String = {
val obj = Map("eventid_1" -> x._1,
"eventid_2" -> x._2,
"distance" -> x._3,
"timestamp" -> System.currentTimeMillis())
val str_obj = scala.util.parsing.json.JSONObject(obj).toString()
str_obj
}
}
Szczególna część każdego z Framework’ów
Zastosowanie transformacji i akcji to miejsce, w którym specyfika każdego z frameworków uniemożliwia bycie kodem generycznym.
Jak zaobserwowano, Flink iteruje przez każde zdarzenie, filtrując, serializując, grupując według IP i czasu i w końcu stosując obliczanie odległości, aby wysłać je do Kafki przez producenta.
W Sparku, z drugiej strony, ponieważ zdarzenia są już pogrupowane według czasu, musimy tylko filtrować, serializować i grupować według IP. Po wykonaniu tych czynności stosowane są funkcje obliczania odległości, a wynik może zostać wysłany do Kafki za pomocą odpowiednich bibliotek.
Dla Flink:
val flow = stream
.filter(!_.contains("src_ip6"))
.map(trace =>{
new Flow(trace).getFlow()
})
.keyBy(_.src_ip4)
.timeWindow(Time.seconds(3))
.apply{(
key: String,
window: TimeWindow,
input: Iterable,
out: Collector]) => {
val distances: List = utils.calculateDistances(input)
out.collect(distances)
}
}
.flatMap(x => x)
flow.map( x=>{
val str_obj: String = utils.generateJson(x)
producer.send(new ProducerRecord(topic_out, str_obj))
})
Dla Spark:
val flow = stream.map(_.value())
.filter(!_.contains("src_ip6"))
.map(record => {
implicit val formats = DefaultFormats
val flow = new Flow(record).getFlow()
(flow.src_ip4,flow)
})
.groupByKey()flow.foreachRDD(rdd => {
rdd.foreach{ case (key, input ) => {
val distances = utils.calculateDistances(input)
distances.map(x => {val str_obj: String = utils.generateJson(x)
producer.send(new ProducerRecord(topic_out, str_obj))
})
}}
})
W temacie wyjściowym Kafki przechowywane są identyfikatory każdego zdarzenia, ich znaczniki czasowe ingestion, wynik obliczenia odległości oraz czas, w którym obliczenia zostały zakończone. Oto przykładowy ślad:
{
"eventid_1":151852746453199,
"ts_flow1":1495466510792,
"eventid_2":1039884491535740,
"ts_flow2":1495466511125,
"distance":12322.94295207115,
"ts_output":1495466520212
}
Results
Wykonaliśmy dwa różne typy testów: wiele zdarzeń w jednym oknie oraz wiele zdarzeń w różnych oknach, gdzie pewne zjawisko sprawia, że algorytm kombinatoryczny jest pozornie stochastyczny i oferuje różne wyniki. Dzieje się tak dlatego, że dane są pobierane w sposób nieuporządkowany, w miarę ich napływu do systemu, bez uwzględnienia czasu zdarzenia, i na jego podstawie dokonywane są grupowania, co powoduje występowanie różnych kombinacji.
Następująca prezentacja z Apache Beam wyjaśnia bardziej szczegółowo różnicę między czasem przetwarzania a czasem zdarzenia: https://goo.gl/h5D1yR

Wielość zdarzeń w tym samym oknie
W tym samym oknie ingestowanych jest około 10 000 zdarzeń, które stosując kombinacje dla tych samych IP wymagają prawie 2 milionów obliczeń. Całkowity czas obliczeń w każdym z ram (tj. różnica pomiędzy najwyższym i najniższym wyjściowym timestampem) przy 8 rdzeniach obliczeniowych wynosi:
- Całkowity czas Spark: 41,50s
- Całkowity czas Flink: 40,24s
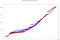
Wielokrotne linie tego samego koloru wynikają z równoległości, ponieważ istnieją obliczenia, które kończą się w tym samym czasie.
Wielokrotne zdarzenia w różnych oknach
Ponad 50 000 zdarzeń jest wstawianych wzdłuż różnych okien czasowych o długości 3s. W tym miejscu wyraźnie widać specyfikę każdego silnika. Gdy wykreślimy ten sam wykres czasów przetwarzania, otrzymamy następujący wynik:
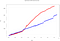
- Całkowity czas Spark: 614.1s
- Całkowity czas Flink: 869.3s
Obserwujemy wzrost czasu przetwarzania dla Flinka. Wynika to ze sposobu w jaki przyjmuje zdarzenia:

Jak widać na ostatnim rysunku, Flink nie używa mikropatchy i paralelizuje okienkowanie zdarzeń (w przeciwieństwie do Sparka, używa nakładających się okien przesuwnych). Powoduje to wydłużenie czasu obliczeń, ale skrócenie czasu ingestion. Jest to jedna z cech szczególnych, którą musimy wziąć pod uwagę przy definiowaniu naszej architektury przetwarzania strumieniowego Big Data.
A co z obliczeniami?
Dystans euklidesowy 10 000 zdarzeń ma następujący rozkład:

Założono, że zdarzenia anomalne znajdują się w „długim ogonie” histogramu. Ale czy to naprawdę ma sens? Przeanalizujmy to.
W tym przypadku pewne parametry kategoryczne (IP, port) są traktowane jako liczbowe do obliczeń. Postanowiliśmy to zrobić, aby zwiększyć wymiarowość i zbliżyć się do prawdziwego problemu. Ale oto co otrzymamy, gdy pokażemy wszystkie rzeczywiste wartości odległości:

Czyli szum, ponieważ te wartości (IP, port, źródło i cel) zniekształcają obliczenia. Gdy jednak wyeliminujemy te pola i przetworzymy wszystko od nowa, zachowując:
- duration
- in_bytes
- in_packets
- out_bytes
- out_packets
otrzymujemy następujący rozkład:

Długi ogon nie jest już tak zaludniony i na końcu pojawia się pewien szczyt. Jeśli pokażemy wartości obliczeń odległości, możemy zobaczyć, gdzie są anomalie.

Dzięki temu prostemu udoskonaleniu ułatwiamy pracę analityka, oferując mu potężne narzędzie, oszczędzające czas i wskazujące, gdzie szukać problemów z siecią.
Wnioski
Mimo, że można by dyskutować o nieskończonej ilości możliwości i wniosków, najbardziej godną uwagi wiedzą uzyskaną podczas tego małego rozwoju jest:
- Ramy przetwarzania. Przejście z jednego frameworka na drugi nie jest trywialne, dlatego ważne jest, aby od początku zdecydować, który framework będzie używany i dobrze poznać jego specyfikę. Na przykład, jeśli potrzebujemy przetworzyć zdarzenie natychmiastowo i jest to krytyczne dla biznesu, musimy wybrać silnik przetwarzania, który spełnia ten wymóg.
- Big Picture. Dla niektórych funkcji, jeden silnik będzie wyróżniać się nad innymi, ale co jesteś gotów poświęcić, aby uzyskać tę lub inną funkcję?
- Wykorzystanie zasobów. Zarządzanie pamięcią, CPU, dysk … Ważne jest, aby zastosować stress testy, benchmarki, itp. do systemu, aby wiedzieć, jak będzie się zachowywał jako całość i zidentyfikować możliwe słabe punkty i wąskie gardła
- Charakterystyka i kontekst. Istotne jest, aby zawsze brać pod uwagę konkretny kontekst i wiedzieć, jakie cechy powinny być wprowadzone do systemu. Używaliśmy parametrów takich jak porty lub IP w obliczaniu odległości, aby spróbować wykryć anomalie w sieci. Te cechy, mimo że są liczbowe, nie mają sensu przestrzennego. Istnieją jednak sposoby na wykorzystanie tego typu danych, ale zostawiamy to na przyszły post.
Ten post został pierwotnie opublikowany na stronie https://www.gradiant.org/noticia/big-data-aplicado-spark-vs-flink/
Dzięki Adrián Portabales ( adrianp )
.
Leave a Reply