Big Data toegepast: Spark vs Flink

Net zoals de term Artificial Intelligence (AI) al vele jaren wordt verfoeid, begint juist in 2017 ‘Big Data’ iets dat door de dagelijkse sleet meer afwijzing dan acceptatie genereert. Alles is Big Data en alles wordt opgelost met Big Data. Maar wat doen we dan met degenen die aan Big Data werken?
Big Data wordt de laatste jaren in verband gebracht met grote hoeveelheden gestructureerde of ongestructureerde gegevens die door systemen of organisaties worden geproduceerd. Het belang ervan ligt niet in de gegevens zelf, maar in wat we met die gegevens kunnen doen. In hoe gegevens kunnen worden geanalyseerd om betere beslissingen te nemen. Vaak komt een groot deel van de waarde die uit gegevens kan worden gehaald voort uit ons vermogen ze tijdig te verwerken. Daarom is het belangrijk zowel de gegevensbronnen als het kader waarin wij ze gaan verwerken, zeer goed te kennen.
Een van de eerste doelstellingen bij alle Big Data-projecten is de verwerkingsarchitectuur te definiëren die het best is toegesneden op een specifiek probleem. Dit omvat een immens aantal mogelijkheden en alternatieven:
- Wat zijn de bronnen?
- Hoe worden de gegevens opgeslagen?
- Zijn er rekenkundige beperkingen? En van tijd?
- Welke algoritmen moeten we toepassen?
- Welke nauwkeurigheid moeten we bereiken?
- Hoe kritisch is het proces?
We moeten ons domein heel goed kennen om deze vragen te kunnen beantwoorden en kwalitatief goede antwoorden te kunnen geven. In deze post zullen we een vereenvoudiging van een echte use-case voorstellen en twee Big Data-verwerkingstechnologieën vergelijken.
De voorgestelde use-case is de toepassing van de Kappa architectuur voor de verwerking van Netflow-traces, waarbij verschillende verwerkingsengines worden gebruikt.
Netflow is een netwerkprotocol om informatie over IP-verkeer te verzamelen. Het verschaft ons informatie zoals de begin- en einddatum van verbindingen, bron- en doel-IP-adressen, poorten, protocollen, pakketbytes, enz. Het is momenteel een standaard voor het monitoren van netwerkverkeer en wordt ondersteund door verschillende hardware en software platforms.
Elke gebeurtenis in de netflow traces geeft ons uitgebreide informatie over een verbinding die tot stand is gebracht in het gemonitorde netwerk. Deze gebeurtenissen worden opgenomen via Apache Kafka te worden geanalyseerd door de processing engine -in dit geval Apache Spark of Apache Flink-, het uitvoeren van een eenvoudige bewerking, zoals de berekening van de Euclidische afstand tussen paren van gebeurtenissen. Dit soort berekeningen zijn fundamenteel in anomalie detectie algoritmen.
Om deze verwerking uit te voeren is het echter noodzakelijk om de gebeurtenissen te groeperen, bijvoorbeeld door middel van tijdelijke vensters, omdat in een zuivere streaming context de gegevens een begin of een einde missen.
Zodra de netflow gebeurtenissen zijn gegroepeerd, levert de berekening van afstanden tussen paren een combinatorische explosie op. Bijvoorbeeld, in het geval ontvangen we 1000 gebeurtenissen / s van hetzelfde IP, en we groeperen ze elke 5s, zal elk venster vereisen een totaal van 12.497.500 berekeningen.
De toe te passen strategie is volledig afhankelijk van de processing engine. In het geval van Spark, event grouping is rechttoe rechtaan, omdat het niet werkt in streaming, maar in plaats daarvan maakt gebruik van micro-batching, dus de verwerking venster zal altijd worden gedefinieerd. In het geval van Flink is deze parameter echter niet verplicht omdat het een zuivere streaming engine is, zodat het noodzakelijk is om het gewenste verwerkingsvenster in de code te definiëren.
De berekening zal als resultaat een nieuwe datastroom opleveren die in een ander Kafka topic wordt gepubliceerd, zoals in de volgende figuur wordt getoond. Op deze manier wordt een grote flexibiliteit in het ontwerp bereikt, waardoor deze verwerking met andere in complexere gegevenspijplijnen kan worden gecombineerd.

Kappa architectuur
De Kappa architectuur is een software architectuurpatroon dat gebruik maakt van gegevensstromen of “streams” in plaats van reeds opgeslagen en bewaarde gegevens te gebruiken. De gegevensbronnen zijn dus onveranderlijk en continu, zoals de in een logboek gegenereerde gegevens. Deze informatiebronnen staan in contrast met de traditionele databanken die in batch- of batchanalysesystemen worden gebruikt.
Deze “stromen” worden door een verwerkingssysteem gestuurd en opgeslagen in hulpsystemen voor de servicelaag.
De Kappa architectuur is een vereenvoudiging van de Lambda architectuur, waarvan zij op de volgende punten verschilt:
- Alles is een stroom (batch is een bijzonder geval)
- Gegevensbronnen zijn onveranderlijk (ruwe gegevens persisteren)
- Er is één analytisch raamwerk (gunstig voor het onderhoud)
- Replay-functionaliteit, dat wil zeggen, het opnieuw verwerken van alle tot nu toe geanalyseerde gegevens (bijvoorbeeld bij een nieuw algoritme)
Samenvattend, het batch-gedeelte is geëlimineerd, ten gunste van een in beweging gegevensverwerkend systeem.
Handen vuil maken
Om al deze theoretische concepten beter te begrijpen, gaat er niets boven een verdieping in de implementatie. Een van de elementen die we met dit proof of concept in de praktijk willen brengen, is de mogelijkheid om op een transparante manier tussen verschillende verwerkingsmachines uit te wisselen. Met andere woorden, hoe gemakkelijk is het schakelen tussen Spark en Flink op basis van dezelfde Scala code? Helaas zijn de dingen niet zo rechtlijnig, hoewel het mogelijk is om tot een gemeenschappelijke gedeeltelijke oplossing te komen, zoals u in de volgende secties kunt zien.
Netflow events
Elke Netflow event geeft informatie over een specifieke verbinding die in het netwerk tot stand is gebracht. Deze events worden weergegeven in JSON formaat en worden opgenomen in Kafka. Voor de eenvoud zullen alleen IPv4 verbindingen worden gebruikt.
Voorbeeld van event:
{
"eventid":995491697672682,
"dvc_version":"3.2",
"aproto":"failed",
"src_ip4":168099844,
"dst_ip4":4294967295,
"eventtime":1490024708,
"out_packets":1,
"type":"flow",
"dvc_time":1490024739,
"dst_ip":"255.255.255.255",
"src_ip":"10.5.0.4",
"duration":0,
"in_bytes":0,
"conn_state":"new",
"@version":"1",
"out_bytes":157,
"dvc_type":"suricata",
"in_packets":0,
"nproto":"UDP",
"src_port":42126,
"@timestamp":"2017-03-20T15:45:08.000Z",
"dst_port":40237,
"category":"informational"
}
Gedeeld deel
Zoals hierboven vermeld, is een van de doelstellingen van dit artikel om op transparante wijze verschillende Big Data verwerkingsomgevingen te gebruiken , dat wil zeggen, om dezelfde Scala functies te gebruiken voor Spark, Flink of toekomstige frameworks. Helaas hebben de eigenaardigheden van elk kader ertoe geleid dat slechts een deel van de Scala-code geïmplementeerd gemeenschappelijk kan zijn voor beide.
De gemeenschappelijke code omvat de mechanismen om netflow-events te serialiseren en deserialiseren. Wij vertrouwen op de json4s bibliotheek van Scala, en definiëren een geval klasse met de velden van belang:
case class Flow_ip4(eventid: String,
dst_ip4: String,
dst_port: String,
duration: String,
in_bytes: String,
in_packets: String,
out_bytes: String,
out_packets: String,
src_ip4: String,
src_port: String) extends Serializable
Daarnaast is de Flow object dat deze serialisatie implementeert gedefinieerd om comfortabel te kunnen werken met verschillende Big Data-engines:
class Flow(trace: String) extends Serializable {implicit val formats =DefaultFormatsvar flow_case : Flow_ip4 = parse(trace).extractdef getFlow() : Flow_ip4 = flow_case}
Een andere code gedeeld door beide raamwerken zijn de functies voor het berekenen van de Euclidische afstand, het verkrijgen van de combinaties van een reeks objecten en het genereren van de Json van de resultaten:
object utils { def euclideanDistance(xs: List, ys: List) = {
sqrt((xs zip ys).map { case (x,y)=> pow(y - x, 2) }.sum)
} def getCombinations(lists : Iterable) = {
lists.toList.combinations(2).map(x=> (x(0),x(1))).toList
} def getAllValuesFromString(flow_case : Flow_ip4) = flow_case.productIterator.drop(1)
.map(_.asInstanceOf.toDouble).toList def calculateDistances(input: Iterable): List = {
val combinations: List = getCombinations(input)
val distances = combinations.map{
case(f1,f2) => (f1.eventid,f2.eventid,euclideanDistance(getAllValuesFromString(f1),
getAllValuesFromString(f2)))}
distances.sortBy(_._3)
} def generateJson(x: (String, String, Double)): String = {
val obj = Map("eventid_1" -> x._1,
"eventid_2" -> x._2,
"distance" -> x._3,
"timestamp" -> System.currentTimeMillis())
val str_obj = scala.util.parsing.json.JSONObject(obj).toString()
str_obj
}
}
Specifiek deel van elk Framework
De toepassing van transformaties en acties is waar de bijzonderheden van elk raamwerk te voorkomen dat het een generieke code.
Zoals waargenomen, gaat Flink iteratief te werk bij elke gebeurtenis, filteren, serialiseren, groeperen op IP en tijd en ten slotte de afstandsberekening toepassen om het via een producent naar Kafka te sturen.
In Spark daarentegen, hoeven we, omdat de gebeurtenissen al op tijd zijn gegroepeerd, alleen maar te filteren, te serialiseren en op IP te groeperen. Zodra dit is gedaan, worden de afstand berekeningsfuncties toegepast en het resultaat kan worden verzonden naar Kafka met de juiste bibliotheken.
Voor Flink:
val flow = stream
.filter(!_.contains("src_ip6"))
.map(trace =>{
new Flow(trace).getFlow()
})
.keyBy(_.src_ip4)
.timeWindow(Time.seconds(3))
.apply{(
key: String,
window: TimeWindow,
input: Iterable,
out: Collector]) => {
val distances: List = utils.calculateDistances(input)
out.collect(distances)
}
}
.flatMap(x => x)
flow.map( x=>{
val str_obj: String = utils.generateJson(x)
producer.send(new ProducerRecord(topic_out, str_obj))
})
Voor Spark:
val flow = stream.map(_.value())
.filter(!_.contains("src_ip6"))
.map(record => {
implicit val formats = DefaultFormats
val flow = new Flow(record).getFlow()
(flow.src_ip4,flow)
})
.groupByKey()flow.foreachRDD(rdd => {
rdd.foreach{ case (key, input ) => {
val distances = utils.calculateDistances(input)
distances.map(x => {val str_obj: String = utils.generateJson(x)
producer.send(new ProducerRecord(topic_out, str_obj))
})
}}
})
De ID’s van elke gebeurtenis, hun ingestion timestamps, het resultaat van de afstand berekening en de tijd waarop de berekening is voltooid, worden opgeslagen in de Kafka output topic. Hier is een voorbeeld van een trace:
{
"eventid_1":151852746453199,
"ts_flow1":1495466510792,
"eventid_2":1039884491535740,
"ts_flow2":1495466511125,
"distance":12322.94295207115,
"ts_output":1495466520212
}
Results
We hebben twee verschillende soorten tests uitgevoerd: meerdere gebeurtenissen binnen één venster, en meerdere gebeurtenissen in verschillende vensters, waarbij een fenomeen ervoor zorgt dat het combinatorische algoritme blijkbaar stochastisch is en verschillende resultaten oplevert. Dit is te wijten aan het feit dat de gegevens ongeordend worden ingevoerd, wanneer ze in het systeem aankomen, zonder rekening te houden met de tijd van de gebeurtenis, en dat op basis daarvan groeperingen worden gemaakt, waardoor verschillende combinaties ontstaan.
In de volgende presentatie van Apache Beam wordt het verschil tussen verwerkingstijd en gebeurtenistijd nader toegelicht: https://goo.gl/h5D1yR

Meerdere gebeurtenissen in hetzelfde venster
Er worden ongeveer 10.000 gebeurtenissen in hetzelfde venster opgenomen, die, als de combinaties voor dezelfde IP’s worden toegepast, bijna 2 miljoen berekeningen vergen. De totale rekentijd in elk kader (d.w.z. het verschil tussen de hoogste en de laagste uitvoertijdstempel) met 8 verwerkingskernen bedraagt:
- Spark totale tijd: 41,50s
- Totale tijd Flink: 40,24s
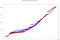
Meerdere lijnen van dezelfde kleur zijn het gevolg van parallellisme, aangezien er berekeningen zijn die op hetzelfde moment eindigen.
Meerdere gebeurtenissen in verschillende vensters
Meer dan 50.000 gebeurtenissen worden ingevoegd langs verschillende tijdvensters van 3s. Dit is waar de bijzonderheden van elke motor duidelijk naar voren komen. Wanneer we dezelfde grafiek van verwerkingstijden plotten, doet zich het volgende voor:
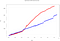
- Totale tijd Flink: 614,1s
- Totale tijd Flink: 869.3s
We zien een toename in verwerkingstijd voor Flink. Dit is te wijten aan de manier waarop het gebeurtenissen binnenhaalt:

Zoals te zien is in de laatste figuur, maakt Flink geen gebruik van micro-batches en parallelliseert het de gebeurtenis windowing (in tegenstelling tot Spark, dat overlappende schuifvensters gebruikt). Dit leidt tot een langere rekentijd, maar een kortere opnametijd. Het is een van de bijzonderheden waar we rekening mee moeten houden bij het definiëren van onze streaming Big Data-verwerkingsarchitectuur.
En hoe zit het met de berekening?
De Euclidische afstand van 10.000 gebeurtenissen heeft de volgende verdeling:

Aanname is dat afwijkende gebeurtenissen zich in de “lange staart” van het histogram bevinden. Maar heeft dat wel zin? Laten we het analyseren.
In dit geval worden bepaalde categorische parameters (IP, poort) voor de berekening als numeriek beschouwd. Wij besloten dit te doen om de dimensionaliteit te verhogen en dichter bij een echt probleem te komen. Maar dit is wat we krijgen wanneer we alle reële waarden van de afstanden weergeven:

Dat is ruis, aangezien deze waarden (IP, poort, bron en bestemming) de berekening vertekenen. Wanneer we deze velden echter elimineren en alles opnieuw verwerken, met behoud van:
- duration
- in_bytes
- in_packets
- out_bytes
- out_packets
Wij verkrijgen de volgende verdeling:

De lange staart is niet meer zo bevolkt en er is een piek aan het eind. Als we de waarden van de afstandsberekening laten zien, kunnen we zien waar de afwijkende waarden zich bevinden.

Dankzij deze eenvoudige verfijning vergemakkelijken we het werk van de analist, bieden we hem/haar een krachtig hulpmiddel dat hem/haar tijd bespaart en aangeeft waar de problemen van een netwerk te vinden zijn.
Conclusies
Hoewel een oneindigheid aan mogelijkheden en conclusies zou kunnen worden besproken, is de meest opmerkelijke kennis die in deze kleine ontwikkeling is verkregen:
- Verwerkingskader. Het is niet triviaal om van het ene raamwerk op het andere over te stappen, dus is het belangrijk om vanaf het begin te beslissen welk raamwerk zal worden gebruikt en de bijzonderheden daarvan zeer goed te kennen. Bijvoorbeeld, als we een gebeurtenis onmiddellijk moeten verwerken en dit is van kritiek belang voor het bedrijf, dan moeten we een processing engine kiezen die aan deze eis voldoet.
- Big Picture. Voor bepaalde functies zal de ene engine boven de andere uitsteken, maar wat bent u bereid op te offeren om deze of gene functie te verkrijgen?
- Gebruik van middelen. Geheugenbeheer, CPU, schijf … Het is belangrijk om stresstests, benchmarks, enz. op het systeem toe te passen om te weten hoe het zich als geheel zal gedragen en om mogelijke zwakke punten en knelpunten te identificeren
- Kenmerken en context. Het is van essentieel belang altijd rekening te houden met de specifieke context en te weten welke kenmerken in het systeem moeten worden ingevoerd. Wij hebben parameters zoals poorten of IP’s gebruikt bij de berekening van afstanden om te trachten anomalieën in een netwerk op te sporen. Deze kenmerken zijn weliswaar numeriek, maar hebben geen ruimtelijke betekenis. Er zijn echter manieren om te profiteren van dit soort gegevens, maar we laten het voor een toekomstige post.
Dit bericht werd oorspronkelijk gepubliceerd op https://www.gradiant.org/noticia/big-data-aplicado-spark-vs-flink/
Met dank aan Adrián Portabales ( adrianp )
Leave a Reply