ビッグデータ応用。 Spark vs Flink
1/31, 2018 – 10 min read

ちょうど人工知能(AI)という言葉が長年蔑まれてきたように。 2017年、「ビッグデータ」は、日々の消耗と爆撃により、受容よりも拒絶を生み出すものになりつつあります。 すべてがビッグデータであり、すべてがビッグデータで解決される。 しかし、その後、我々はビッグデータに取り組む人々をどうするか?
ビッグデータは、近年、システムや組織によって生成される大量の構造化または非構造化データに関連している。 その重要性は、データそのものではなく、そのデータを使って何ができるかにあります。 より良い意思決定を行うために、データをどのように分析できるかについて。 しばしば、データから引き出せる価値の多くは、データを時間内に処理する能力によってもたらされる。 したがって、データ ソースとそれを処理するフレームワークの両方をよく知ることが重要です。
すべてのビッグ データ プロジェクトの最初の目的の 1 つは、特定の問題に最もよく適応する処理アーキテクチャを定義することです。
- ソースは何か、
- データはどのように保存されるか、
- 計算上の制約はあるか、
- どのように処理するか、
- どのように処理するか、 どのように処理するかなど、無数の可能性と代替案が含まれる。 そして時間の?
- どのようなアルゴリズムを適用すべきか?
- どのような精度に到達すべきか?
- プロセスはどれほど重要か?
これらの質問に答え、質の高い答えを提供できるようにするには、ドメインを非常によく知る必要がある。 この投稿を通じて、実際のユースケースの簡略化を提案し、2つのビッグデータ処理技術を比較します。
提案するユースケースは、異なる処理エンジンを使用してNetflowトレースを処理するためのKappaアーキテクチャのアプリケーションです。 接続の開始日と終了日、送信元と送信先のIPアドレス、ポート、プロトコル、パケットバイトなどの情報を得ることができる。 現在、ネットワーク トラフィックを監視するための標準となっており、さまざまなハードウェアおよびソフトウェア プラットフォームでサポートされています。
netflow トレースに含まれる各イベントは、監視対象のネットワークで確立された接続の詳細情報を提供します。 これらのイベントは Apache Kafka を介して取り込まれ、処理エンジン (この場合は Apache Spark または Apache Flink) によって分析され、イベントのペア間のユークリッド距離の計算などの簡単な処理を実行します。 このタイプの計算は、異常検出アルゴリズムの基本です。
しかし、この処理を実行するためには、純粋なストリーミング コンテキストではデータに開始または終了がないため、たとえば一時ウィンドウを通じて、イベントをグループ化する必要があります。 たとえば、同じ IP から 1000 イベント/秒を受信し、それらを 5 秒ごとにグループ化する場合、各ウィンドウは合計 12,497,500 回の計算を必要とすることになります。 Spark の場合、イベントのグループ化はストリーミングで動作せず、代わりにマイクロバッチを使用するので、処理ウィンドウは常に定義されていることになり、簡単です。 しかし、Flink の場合、純粋なストリーミング エンジンであるため、このパラメーターは必須ではありません。したがって、コード内で希望の処理ウィンドウを定義する必要があります。
計算結果は、次の図のように、別の Kafka トピックで公開される新しいデータ ストリームとして返されます。 このようにして、より複雑なデータ パイプラインでこの処理を他のものと組み合わせることができる、設計の大きな柔軟性が達成されます。

Kappa Architecture
Kappaアーキテクチャとは、すでに保存および持続されるデータを使用せずにデータの流れ、すなわち「ストリーム」を使うソフトウェア建築パターンのことである。 したがって、データソースは、ログに生成されるエントリのような、不変で連続的なものになる。 これらの情報源は、バッチまたはバッチ分析システムで使用される従来のデータベースとは対照的である。
これらの「ストリーム」は処理システムを通じて送られ、サービス層用の補助システムに格納される。
KappaアーキテクチャはLambdaアーキテクチャを単純化したものであり、以下の点で異なる。
- すべてがストリーム(バッチは特殊なケース)
- どのように処理するか、
データソースは不変(生のデータは持続する) 単一の分析フレームワークがある(保守に有利)
まとめると、バッチ処理部分を排除し、インモーションデータプロセッシングシステムが有利である。
Get our hands dirty
これらすべての理論的概念をよりよく理解するためには、実装を深めるに越したことはありません。 この概念実証で実践したい要素の1つは、異なる処理エンジン間を透過的に交換できるようにすることです。 つまり、同じScalaのコードで、SparkとFlinkを簡単に切り替えられるかどうかということです。 残念ながら、物事はそれほど単純ではありませんが、次のセクションで説明するように、共通の部分的なソリューションに到達することは可能です。
Netflow events
各 Netflow イベントは、ネットワークで確立された特定の接続に関する情報を提供します。 これらのイベントは、JSON 形式で表され、Kafka に取り込まれます。
Example of event:
{
"eventid":995491697672682,
"dvc_version":"3.2",
"aproto":"failed",
"src_ip4":168099844,
"dst_ip4":4294967295,
"eventtime":1490024708,
"out_packets":1,
"type":"flow",
"dvc_time":1490024739,
"dst_ip":"255.255.255.255",
"src_ip":"10.5.0.4",
"duration":0,
"in_bytes":0,
"conn_state":"new",
"@version":"1",
"out_bytes":157,
"dvc_type":"suricata",
"in_packets":0,
"nproto":"UDP",
"src_port":42126,
"@timestamp":"2017-03-20T15:45:08.000Z",
"dst_port":40237,
"category":"informational"
}
Shared part
前述のように、この記事の目的の1つは、異なるビッグ データ処理環境を透過的に使用すること、つまり、同じ Scala 関数を Spark や Flink、その他のフレームワークで使用することです。
共通のコードには、ネットフローイベントをシリアライズおよびデシリアライズするメカニズムが含まれます。 Scalaのjson4sライブラリに依存し、関心のあるフィールドを持つcaseクラスを定義します。
case class Flow_ip4(eventid: String,
dst_ip4: String,
dst_port: String,
duration: String,
in_bytes: String,
in_packets: String,
out_bytes: String,
out_packets: String,
src_ip4: String,
src_port: String) extends Serializable
さらに、このシリアライズを実装するFlowオブジェクトは、異なるビッグデータエンジンと快適に動作できるように定義されています。
class Flow(trace: String) extends Serializable {implicit val formats =DefaultFormatsvar flow_case : Flow_ip4 = parse(trace).extractdef getFlow() : Flow_ip4 = flow_case}
両フレームワークに共通するもう1つのコードは、ユークリッド距離の計算、一連のオブジェクトの組み合わせの取得、結果のJson生成の関数です:
object utils { def euclideanDistance(xs: List, ys: List) = {
sqrt((xs zip ys).map { case (x,y)=> pow(y - x, 2) }.sum)
} def getCombinations(lists : Iterable) = {
lists.toList.combinations(2).map(x=> (x(0),x(1))).toList
} def getAllValuesFromString(flow_case : Flow_ip4) = flow_case.productIterator.drop(1)
.map(_.asInstanceOf.toDouble).toList def calculateDistances(input: Iterable): List = {
val combinations: List = getCombinations(input)
val distances = combinations.map{
case(f1,f2) => (f1.eventid,f2.eventid,euclideanDistance(getAllValuesFromString(f1),
getAllValuesFromString(f2)))}
distances.sortBy(_._3)
} def generateJson(x: (String, String, Double)): String = {
val obj = Map("eventid_1" -> x._1,
"eventid_2" -> x._2,
"distance" -> x._3,
"timestamp" -> System.currentTimeMillis())
val str_obj = scala.util.parsing.json.JSONObject(obj).toString()
str_obj
}
}
Specific part of each Framework
変換とアクションのアプリケーションは、それぞれのフレームワークの特殊性が汎用コードにならないようにしているところです。
観察されたように、Flinkは各イベントによって反復し、フィルタリング、シリアライズ、IPと時間によるグループ化、最後に距離計算を適用してプロデューサーを通してKafkaに送出します。一方、Sparkでは、イベントはすでに時間によってグループ化されているので、フィルター、シリアライズ、IPによるグループ化だけが必要です。 これが終わると、距離計算の関数が適用され、その結果を適切なライブラリを使ってKafkaに送出できます。
Flinkの場合:
val flow = stream
.filter(!_.contains("src_ip6"))
.map(trace =>{
new Flow(trace).getFlow()
})
.keyBy(_.src_ip4)
.timeWindow(Time.seconds(3))
.apply{(
key: String,
window: TimeWindow,
input: Iterable,
out: Collector]) => {
val distances: List = utils.calculateDistances(input)
out.collect(distances)
}
}
.flatMap(x => x)
flow.map( x=>{
val str_obj: String = utils.generateJson(x)
producer.send(new ProducerRecord(topic_out, str_obj))
})
Sparkの場合:
val flow = stream.map(_.value())
.filter(!_.contains("src_ip6"))
.map(record => {
implicit val formats = DefaultFormats
val flow = new Flow(record).getFlow()
(flow.src_ip4,flow)
})
.groupByKey()flow.foreachRDD(rdd => {
rdd.foreach{ case (key, input ) => {
val distances = utils.calculateDistances(input)
distances.map(x => {val str_obj: String = utils.generateJson(x)
producer.send(new ProducerRecord(topic_out, str_obj))
})
}}
})
それぞれのイベントのID、それらのインジェストタイムスタンプ、距離計算結果、計算完了時刻はKafka出力トピックに格納されます。 以下はトレースの例です:
{
"eventid_1":151852746453199,
"ts_flow1":1495466510792,
"eventid_2":1039884491535740,
"ts_flow2":1495466511125,
"distance":12322.94295207115,
"ts_output":1495466520212
}
Results
1つのウィンドウ内の複数のイベントと、異なるウィンドウ内の複数のイベントの2種類のテストを実行しましたが、ある現象により組み合わせアルゴリズムが一見確率的になり、異なる結果を提供するようになりました。 これは、データがシステムに到着したときに、イベント時間を考慮せずに順不同に取り込まれ、それに基づいてグループ化が行われるため、異なる組み合わせが存在することになります。
Apache Beam の次のプレゼンテーションでは、処理時間とイベント時間の違いについてより詳細に説明されています。 https://goo.gl/h5D1yR
Multiple events in the same window
約1万個のイベントが同じウィンドウに取り込まれ、同じIPに対して組み合わせを適用すると、約200万の計算が必要になります。 8つの処理コアを使用した場合の各フレームワークの総計算時間(=最高出力タイムスタンプと最低出力タイムスタンプの差)は、
- Spark total time: 41.50s
- Total time Flink: 40,24s
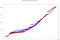
同色の複数の線は、同じ時間に終了する計算があるため、並列性のため。
Multiple events in different windows
3秒間の異なる時間窓に沿って5万以上のイベントが挿入されています。 このあたりは、それぞれのエンジンの特殊性がはっきりと出ています。 同じように処理時間のグラフをプロットすると、次のようになります。
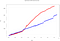
- Sparkの総時間: 614.1s
- Total time Flink.Flinkの総時間: 614.1s
- duration
- in_bytes
- in_packets
- out_bytes
- out_packets
- 処理フレームワーク。 あるフレームワークから別のフレームワークに移行するのは簡単なことではありません。したがって、最初から、どのフレームワークを使用するかを決定し、その特殊性をよく知ることが重要です。 たとえば、イベントを即座に処理する必要があり、それがビジネスにとって重要である場合、この要件を満たす処理エンジンを選択する必要があります。 特定の機能については、あるエンジンが他のエンジンよりも目立ちますが、この機能やその機能を得るために何を犠牲にするのか。 メモリ管理、CPU、ディスク……ストレステストやベンチマークなどを適用して、システム全体としてどのように動作するかを知り、考えられる弱点やボトルネックを特定することが重要です
- 特徴と文脈。 常に特定のコンテキストを考慮に入れ、どのような特性をシステムに導入すべきかを知ることが不可欠である。 私たちは、ネットワークの異常を検出しようとして、距離の計算にポートやIPなどのパラメータを使用しました。 これらの特性は、数値的なものであるにもかかわらず、その中に空間的な意味合いはありません。 しかし、この種のデータを活用する方法はありますが、それは今後の投稿に譲ります。
Flinkの処理時間が増加していることが確認できます。 これは、イベントを取り込む方法によるものです。

最後の図に見られるように、Flinkはマイクロバッチを使わず、イベントウィンドウ処理を平行しています(スパークと異なり、重複したスライドウィンドウを使っています)。 このため、計算時間は長くなりますが、取り込み時間は短くなります。 これは、ストリーミング・ビッグデータ処理アーキテクチャを定義する際に考慮しなければならない特殊性の1つです。
では、計算についてはどうでしょうか?
1万イベントのユークリッド距離は次のような分布になります:

異常なイベントはヒストグラムの「長い尾」にあると仮定されているのです。 しかし、本当に意味があるのでしょうか? 分析してみましょう。
この場合、あるカテゴリカルなパラメーター(IP、ポート)は、計算のために数値として考慮されています。 次元を増やして実際の問題に近づけるためにそうすることにしたのです。 しかし、距離の実値をすべて表示するとこのようになります:

つまり、これらの値 (IP, port, source and destination) が計算に歪みを与えているのでノイズとなるのです。 しかし、これらのフィールドを排除し、
を維持してすべてを再度処理すると、以下の分布となる。

ロングテールはもはやそれほど多くなく、最後にはある程度のピークがある。

この単純な改良のおかげで、分析者の作業が容易になり、時間を節約して、ネットワークの問題を見つける場所を指摘する強力なツールを提供することが可能になりました。
結論
無限の可能性と結論を論じることができますが、この小さな開発を通して得られた最も注目すべき知識は、次のとおりです:
この投稿は https://www.gradiant.org/noticia/big-data-aplicado-spark-vs-flink/
Thanks to Adrián Portabales ( adrianp )
で発表されたものです。
Leave a Reply