アンスコムのカルテット
9月19日。 2018 – 2 min read
「数値計算は正確だが、グラフは大雑把」というのが私の信条です。 データ分析を学び始めたばかりの私にとって、要約統計とともにデータビジュアライゼーションの重要性を理解するのは難しいことでした。 しかし、今回のData Visualization Meetupに参加して、Anscombe’s Quartetに出会ったことで、すべてが変わりました。 これは4つのデータセットからなり、それぞれが11組の(x,y)を含んでいます。 これらのデータセットで重要なことは、同じ記述統計量を共有していることです。 しかし、グラフ化されると、状況は一変する。
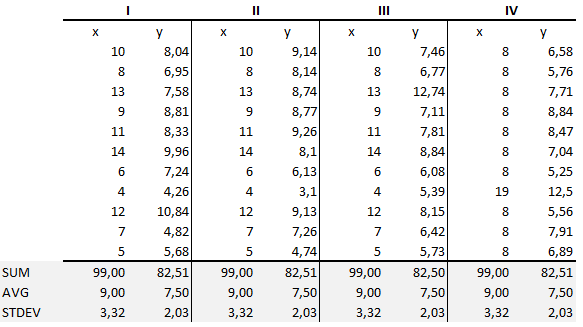
The summary statistics shows that the means and the variances were identical for x and y across the groups :
- Mean of x is 9 and mean of y is 7.All Rights Reserved.同様に、xの分散は11、yの分散は4.13である。
- xとyの相関係数(二つの変数の間にどれだけの強い関係があるか)は0.816である。
これらの4つのデータセットをx/y座標平面上にプロットすると、同じ回帰線を示すが、それぞれのデータセットが異なるストーリーを語っていることが観察される.

- Dataset I はきれいでよくフィットする線形モデルであるように見えます。
- Dataset IIは正規分布ではありません。
- Dataset IIIでは、分布は線形ですが、計算された回帰は外れ値によって混乱します。
- Dataset IVは、1つの外れ値が高い相関係数を生成するのに十分であることを示しています。 データを見ることで、多くの構造とデータセットの明確なイメージが明らかになる。
コンピュータは、計算とグラフの両方を作成する必要があります。 両方の出力が研究されるべきで、それぞれが理解に貢献することになる」
。
Leave a Reply