RL – DQN Deep Q-network

I computer possono giocare ai videogiochi come un umano? Nel 2015, DQN ha battuto gli esperti umani in molti giochi Atari. Ma quando si tratta di complessi giochi di strategia di guerra, l’IA non se la cava bene. Nel 2017, una squadra di professionisti ha battuto facilmente un programma AI DeepMind in Starcraft 2.
Come citato dal documento di DeepMind:
È un problema multi-agente con più giocatori che interagiscono; c’è un’informazione imperfetta a causa di una mappa parzialmente osservata; ha un grande spazio d’azione che coinvolge la selezione e il controllo di centinaia di unità; ha un grande spazio di stato che deve essere osservato esclusivamente da piani di caratteristiche di input grezzi; e ha un’assegnazione di credito ritardata che richiede strategie a lungo termine su migliaia di passi.
Ricominciamo il nostro viaggio di ritorno al Deep Q-Network DQN. Nel gioco Seaquest qui sotto, DQN impara come leggere i punteggi, sparare al nemico e salvare i subacquei dalle immagini grezze, tutto da solo. Scopre anche la conoscenza che possiamo chiamare strategia, come quando portare il sottomarino in superficie per l’ossigeno.

Q-learning impara la funzione azione-valore Q(s, a): quanto bene intraprendere un’azione in un particolare stato. Per esempio, per la posizione della scacchiera qui sotto, quanto è buono muovere il pedone di due passi in avanti. Letteralmente, assegniamo un valore scalare sul beneficio di fare tale mossa.
Q è chiamata funzione azione-valore (o funzione Q-valore in questo articolo).

Nel Q-learning, costruiamo una tabella di memoria Q per memorizzare i valori Q per tutte le possibili combinazioni di s e a. Se sei un giocatore di scacchi, è la scheda per la mossa migliore. Nell’esempio di cui sopra, potremmo capire che muovere il pedone 2 passi avanti ha i valori Q più alti di tutti gli altri. (Il consumo di memoria sarà troppo alto per il gioco degli scacchi. Ma rimaniamo con questo approccio un po’ più a lungo.)
In termini tecnici, campioniamo un’azione dallo stato attuale. Scopriamo la ricompensa R (se esiste) e il nuovo stato s’ (la nuova posizione della scacchiera). Dalla tabella di memoria, determiniamo la prossima azione a’ da prendere che ha il massimo Q(s’, a’).
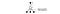
In un videogioco, otteniamo punti (ricompense) abbattendo il nemico. In un gioco di scacchi, la ricompensa è +1 quando vinciamo o -1 se perdiamo. Quindi c’è solo una ricompensa data e ci vuole un po’ di tempo per ottenerla.
Il Q-learning consiste nel creare il cheat sheet Q.

Si può prendere una singola mossa a e vedere quale ricompensa R possiamo ottenere. Questo crea uno sguardo in avanti di un passo. R + Q(s’, a’) diventa l’obiettivo che vogliamo che sia Q(s, a). Per esempio, diciamo che ora tutti i valori di Q sono uguali a uno. Se spostiamo il joystick verso destra e segniamo 2 punti, vogliamo spostare Q(s, a) più vicino a 3 (cioè 2 + 1).

Continuando a giocare, manteniamo una media corrente per Q. I valori miglioreranno e con alcuni accorgimenti, i valori di Q convergeranno.
Algoritmo di apprendimento di Q
Il seguente è l’algoritmo per adattare Q con le ricompense campionate. Se γ (fattore di sconto) è più piccolo di uno, c’è una buona probabilità che Q converga.

Tuttavia, se le combinazioni di stati e azioni sono troppo grandi, la memoria e i requisiti di calcolo per Q saranno troppo alti. Per risolvere questo problema, passiamo a una rete profonda Q (DQN) per approssimare Q(s, a). L’algoritmo di apprendimento è chiamato Deep Q-learning. Con il nuovo approccio, generalizziamo l’approssimazione della funzione di valore Q piuttosto che ricordare le soluzioni.
Quali sfide affronta RL rispetto a DL?
Nell’apprendimento supervisionato, vogliamo che l’input sia i.i.d. (indipendente e identicamente distribuito), cioè
- I campioni sono randomizzati tra i lotti e quindi ogni lotto ha la stessa (o simile) distribuzione dei dati.
- I campioni sono indipendenti l’uno dall’altro nello stesso lotto.
Se no, il modello può essere overfitted per alcune classi (o gruppi) di campioni in tempi diversi e la soluzione non sarà generalizzata.
Inoltre, per lo stesso input, la sua etichetta non cambia nel tempo. Questo tipo di condizione stabile per l’input e l’output fornisce la condizione per l’apprendimento supervisionato per eseguire bene.
Nell’apprendimento di rinforzo, sia l’input che il target cambiano costantemente durante il processo e rendono l’addestramento instabile.
Target instabile: Costruiamo una rete profonda per imparare i valori di Q ma i suoi valori target cambiano man mano che conosciamo meglio le cose. Come mostrato sotto, i valori target per Q dipendono da Q stesso, stiamo inseguendo un target non stazionario.

i.i.d.: C’è un altro problema legato alle correlazioni all’interno di una traiettoria. All’interno di un’iterazione di addestramento, aggiorniamo i parametri del modello per spostare Q(s, a) più vicino alla verità di base. Questi aggiornamenti avranno un impatto su altre stime. Quando tiriamo su i valori Q nella rete profonda, anche i valori Q negli stati circostanti saranno tirati su come una rete.

Diciamo che abbiamo appena ottenuto una ricompensa e regoliamo la rete Q per rifletterla. Successivamente, facciamo un’altra mossa. Il nuovo stato sarà simile all’ultimo in particolare se usiamo immagini grezze per rappresentare gli stati. Il nuovo Q(s’, a’) recuperato sarà più alto e anche il nostro nuovo obiettivo per Q si sposterà più in alto, indipendentemente dal merito della nuova azione. Se aggiorniamo la rete con una sequenza di azioni nella stessa traiettoria, si ingrandisce l’effetto oltre la nostra intenzione. Questo destabilizza il processo di apprendimento e sembra che i cani si inseguano la coda.
Qual è la sfida fondamentale nell’addestramento della RL? Nella RL, spesso dipendiamo dalla politica o dalle funzioni di valore per campionare le azioni. Tuttavia, questo cambia frequentemente man mano che sappiamo meglio cosa esplorare. Man mano che giochiamo, conosciamo meglio i valori di verità a terra degli stati e delle azioni. Quindi anche i nostri output di destinazione cambiano. Ora, cerchiamo di imparare una mappatura f per un input e un output in costante cambiamento!
Per fortuna, sia l’input che l’output possono convergere. Quindi, se rallentiamo abbastanza i cambiamenti sia in ingresso che in uscita, possiamo avere la possibilità di modellare f permettendogli di evolvere.
Soluzioni
Ripetizione dell’esperienza: Per esempio, mettiamo l’ultimo milione di transizioni (o fotogrammi video) in un buffer e campioniamo un mini-batch di campioni di dimensione 32 da questo buffer per addestrare la rete profonda. Questo forma un set di dati di input che è abbastanza stabile per l’addestramento. Poiché campioniamo casualmente dal buffer di replay, i dati sono più indipendenti l’uno dall’altro e più vicini all’i.i.d.
Rete target: Creiamo due reti profonde θ- e θ. Usiamo la prima per recuperare i valori Q mentre la seconda include tutti gli aggiornamenti nella formazione. Dopo diciamo 100.000 aggiornamenti, sincronizziamo θ- con θ. Lo scopo è quello di fissare temporaneamente gli obiettivi dei valori Q in modo da non avere un obiettivo mobile da inseguire. Inoltre, i cambiamenti dei parametri non hanno un impatto immediato su θ- e quindi anche l’input potrebbe non essere al 100% i.i.d, non ingrandirà erroneamente il suo effetto come menzionato prima.

Con entrambi i replay dell’esperienza e la rete target, abbiamo un input e un output più stabili per addestrare la rete e si comporta più come un addestramento supervisionato.
Il replay dell’esperienza ha il maggior miglioramento delle prestazioni in DQN. Il miglioramento della rete target è significativo ma non così critico come il replay. Ma diventa più importante quando la capacità della rete è piccola.
Deep Q-learning with experience replay
Ecco l’algoritmo:

dove ϕ preprocessa gli ultimi 4 frame di immagine per rappresentare lo stato. Per catturare il movimento, usiamo quattro fotogrammi per rappresentare uno stato.
Dettagli d’implementazione
Funzione di perdita
Esaminiamo qualche altro dettaglio d’implementazione per migliorare le prestazioni. DQN usa la perdita di Huber (curva verde) dove la perdita è quadratica per piccoli valori di a, e lineare per grandi valori.


L’introduzione della perdita di Huber permette cambiamenti meno drammatici che spesso danneggiano la RL.
Ottimizzazione
L’addestramento RL è sensibile ai metodi di ottimizzazione. La semplice programmazione del tasso di apprendimento non è abbastanza dinamica per gestire i cambiamenti di input durante l’allenamento. Molti addestramenti RL utilizzano RMSProp o l’ottimizzatore Adam. DQN è addestrato con RMSProp. L’uso del metodo di ottimizzazione avanzata nei metodi Policy Gradient è anche molto studiato.
ϵ-greedy
DQN usa ϵ-greedy per selezionare la prima azione.
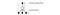
Per migliorare l’addestramento, ϵ inizia a 1 e ricuce a 0.1 o 0,05 sul primo milione di fotogrammi usando la seguente politica.

dove m è il numero di azioni possibili. All’inizio dell’addestramento, selezioniamo uniformemente le azioni possibili, ma man mano che l’addestramento procede, selezioniamo l’azione ottimale a* più frequentemente. Questo permette la massima esplorazione all’inizio che alla fine passa allo sfruttamento.
Ma anche durante i test, possiamo mantenere ϵ ad un piccolo valore come 0,05. Una politica deterministica può bloccarsi in un ottimo locale. Una politica non deterministica ci permette di uscire per avere la possibilità di raggiungere un ottimo migliore.

Architettura
Ecco l’architettura DQN. Prendiamo gli ultimi 4 fotogrammi video precedenti e li alimentiamo in strati convoluzionali seguiti da strati completamente connessi per calcolare i valori Q per ogni azione.

Nell’esempio seguente, se non muoviamo la racchetta in alto al fotogramma 3, perderemo la palla. Come previsto dal DQN, il valore Q di muovere la racchetta verso l’alto è molto più alto rispetto alle altre azioni.


Miglioramenti alla DQN
Vengono apportati molti miglioramenti alla DQN. In questa sezione, mostreremo alcuni metodi che dimostrano miglioramenti significativi.
Double DQN
Nell’apprendimento Q, usiamo la seguente formula per il valore target di Q.

Tuttavia, l’operazione max crea un bias positivo verso le stime di Q.

Dall’esempio precedente, vediamo che il max Q(s, a) è superiore al valore convergente 1.0. cioè l’operazione max sovrastima Q. Dalla teoria e dagli esperimenti, le prestazioni DQN migliorano se usiamo la rete online θ per selezionare avidamente l’azione e la rete target θ- per stimare il valore Q.

Prioritized Experience Replay
DQN campiona le transizioni dal replay buffer in modo uniforme. Tuttavia, dovremmo prestare meno attenzione ai campioni che sono già vicini all’obiettivo. Dovremmo campionare le transizioni che hanno una grande distanza dal target:

Pertanto, possiamo selezionare le transizioni dal buffer
- in base al valore di errore di cui sopra (scegliere le transizioni con errore più alto più frequentemente), o
- classificarle in base al valore di errore e selezionarle per grado (scegliere quella con grado più alto più spesso).
Per i dettagli sulle equazioni sui dati di campionamento, fare riferimento al documento Prioritized Experience Replay.
Dueling DQN
Nel Dueling DQN, Q è calcolato con una formula diversa sotto con la funzione di valore V e una funzione di vantaggio dell’azione dipendente dallo stato A sotto:

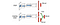
Invece di imparare Q, usiamo due teste separate per calcolare V e A. Gli esperimenti empirici mostrano che le prestazioni migliorano. DQN aggiorna la funzione di valore Q di uno stato solo per una specifica azione. Dueling DQN aggiorna V di cui possono approfittare anche altri aggiornamenti di Q(s, a’). Quindi ogni iterazione di addestramento di Dueling DQN si pensa abbia un impatto maggiore.
Reti rumorose per l’esplorazione
DQN usa ϵ-greedy per selezionare le azioni. In alternativa, NoisyNet lo sostituisce aggiungendo rumore parametrico allo strato lineare per aiutare l’esplorazione. In NoisyNet, ε-greedy non è usato. Utilizza un metodo greedy per selezionare le azioni dalla funzione Q-value. Ma per gli strati completamente connessi dell’approssimatore Q, aggiungiamo rumore parametrico addestrabile in basso per esplorare le azioni. L’aggiunta di rumore a una rete profonda è spesso equivalente o migliore dell’aggiunta di rumore a un’azione come nel metodo ϵ-greedy.

Più pensieri
DQN appartiene a una classe importante di RL, cioè il value-learning. In pratica, spesso combiniamo i gradienti di policy con i metodi di value-learning nella risoluzione di problemi della vita reale.
Leave a Reply