Big Data applicato: Spark vs Flink

Così come il termine Intelligenza Artificiale (AI) è stato disprezzato per molti anni, proprio nel 2017 ‘Big Data’ inizia qualcosa che genera più rifiuto che accettazione a causa del logorio quotidiano. Tutto è Big Data e tutto si risolve con Big Data. Ma allora, cosa fanno quelli che lavorano sui Big Data?
I Big Data sono stati collegati negli ultimi anni a grandi quantità di dati strutturati o non strutturati prodotti da sistemi o organizzazioni. La sua importanza non risiede nei dati in sé, ma in ciò che possiamo fare con quei dati. Su come i dati possono essere analizzati per prendere decisioni migliori. Spesso, gran parte del valore che può essere estratto dai dati deriva dalla nostra capacità di elaborarli in tempo. Quindi, è importante conoscere molto bene sia le fonti di dati che il quadro in cui li elaboreremo.
Uno degli obiettivi iniziali in tutti i progetti Big Data è quello di definire l’architettura di elaborazione che meglio si adatta a un problema specifico. Questo include un’immensità di possibilità e alternative:
- Quali sono le fonti?
- Come vengono memorizzati i dati?
- Ci sono vincoli computazionali? E di tempo?
- Quali algoritmi dobbiamo applicare?
- Quale precisione dobbiamo raggiungere?
- Quanto è critico il processo?
Dobbiamo conoscere molto bene il nostro dominio per poter rispondere a queste domande e fornire risposte di qualità. Nel corso di questo post, proporremo una semplificazione di un caso d’uso reale e confronteremo due tecnologie di elaborazione dei Big Data.
Il caso d’uso proposto è l’applicazione dell’architettura Kappa per l’elaborazione delle tracce Netflow, utilizzando diversi motori di elaborazione.
Netflow è un protocollo di rete per raccogliere informazioni sul traffico IP. Ci fornisce informazioni come le date di inizio e fine delle connessioni, indirizzi IP di origine e destinazione, porte, protocolli, byte di pacchetti, ecc. Attualmente è uno standard per il monitoraggio del traffico di rete ed è supportato da diverse piattaforme hardware e software.
Ogni evento contenuto nelle tracce netflow ci fornisce informazioni estese di una connessione stabilita nella rete monitorata. Questi eventi vengono ingeriti attraverso Apache Kafka per essere analizzati dal motore di elaborazione -in questo caso Apache Spark o Apache Flink-, eseguendo una semplice operazione come il calcolo della distanza euclidea tra coppie di eventi. Questo tipo di calcoli sono fondamentali negli algoritmi di rilevamento delle anomalie.
Tuttavia, per effettuare questa elaborazione è necessario raggruppare gli eventi, ad esempio attraverso finestre temporanee, poiché in un contesto di puro streaming i dati non hanno un inizio o una fine.
Una volta raggruppati gli eventi netflow, il calcolo delle distanze tra coppie produce un’esplosione combinatoria. Per esempio, nel caso in cui riceviamo 1000 eventi/s dallo stesso IP, e li raggruppiamo ogni 5s, ogni finestra richiederà un totale di 12.497.500 calcoli.
La strategia da applicare dipende totalmente dal motore di elaborazione. Nel caso di Spark, il raggruppamento degli eventi è semplice in quanto non lavora in streaming ma utilizza invece il micro-batching, quindi la finestra di elaborazione sarà sempre definita. Nel caso di Flink, invece, questo parametro non è obbligatorio in quanto è un motore puramente di streaming, quindi è necessario definire la finestra di elaborazione desiderata nel codice.
Il calcolo restituirà come risultato un nuovo flusso di dati che viene pubblicato in un altro argomento Kafka, come mostrato nella figura seguente. In questo modo si ottiene una grande flessibilità nella progettazione, potendo combinare questa elaborazione con altre in pipeline di dati più complesse.

Architettura Kappa
L’architettura Kappa è un pattern di architettura software che utilizza flussi di dati o “streams” invece di utilizzare dati già memorizzati e persistiti. Le fonti di dati saranno, quindi, immutabili e continue, come le voci generate in un log. Queste fonti di informazione contrastano con i tradizionali database utilizzati nei sistemi di analisi batch o in batch.
Questi “flussi” vengono inviati attraverso un sistema di elaborazione e memorizzati in sistemi ausiliari per il livello di servizio.
L’architettura Kappa è una semplificazione dell’architettura Lambda, dalla quale differisce nei seguenti aspetti:
- Tutto è un flusso (il batch è un caso particolare)
- Le fonti dei dati sono immutabili (i dati grezzi persistono)
- C’è un unico framework analitico (vantaggioso per la manutenzione)
- Funzionalità di replay, cioè rielaborare tutti i dati analizzati fino a quel momento (per esempio, quando si ha un nuovo algoritmo)
In sintesi, la parte batch viene eliminata, favorendo un sistema di elaborazione dati in movimento.
Si sporcano le mani
Per capire meglio tutti questi concetti teorici, niente di meglio che approfondire l’implementazione. Uno degli elementi che vogliamo mettere in pratica con questo proof of concept è poter scambiare tra diversi motori di elaborazione in modo trasparente. In altre parole, quanto è facile passare da Spark a Flink basandosi sullo stesso codice Scala? Sfortunatamente, le cose non sono così semplici, anche se è possibile raggiungere una soluzione parziale comune, come si può vedere nelle sezioni seguenti.
Eventi Netflow
Ogni evento Netflow fornisce informazioni su una specifica connessione stabilita nella rete. Questi eventi sono rappresentati in formato JSON e sono inseriti in Kafka. Per semplicità, saranno utilizzate solo le connessioni IPv4.
Esempio di evento:
{
"eventid":995491697672682,
"dvc_version":"3.2",
"aproto":"failed",
"src_ip4":168099844,
"dst_ip4":4294967295,
"eventtime":1490024708,
"out_packets":1,
"type":"flow",
"dvc_time":1490024739,
"dst_ip":"255.255.255.255",
"src_ip":"10.5.0.4",
"duration":0,
"in_bytes":0,
"conn_state":"new",
"@version":"1",
"out_bytes":157,
"dvc_type":"suricata",
"in_packets":0,
"nproto":"UDP",
"src_port":42126,
"@timestamp":"2017-03-20T15:45:08.000Z",
"dst_port":40237,
"category":"informational"
}
Parte condivisa
Come accennato in precedenza, uno degli obiettivi di questo articolo è quello di utilizzare in modo trasparente diversi ambienti di elaborazione dei Big Data, cioè, utilizzare le stesse funzioni Scala per Spark, Flink o framework futuri. Sfortunatamente, le peculiarità di ciascun framework hanno fatto sì che solo una parte del codice Scala implementato possa essere comune per entrambi.
Il codice comune include i meccanismi per serializzare e deserializzare gli eventi netflow. Ci affidiamo alla libreria json4s di Scala, e definiamo una classe caso con i campi di interesse:
case class Flow_ip4(eventid: String,
dst_ip4: String,
dst_port: String,
duration: String,
in_bytes: String,
in_packets: String,
out_bytes: String,
out_packets: String,
src_ip4: String,
src_port: String) extends Serializable
Inoltre, l’oggetto Flow che implementa questa serializzazione è definito per poter lavorare comodamente con diversi motori Big Data:
class Flow(trace: String) extends Serializable {implicit val formats =DefaultFormatsvar flow_case : Flow_ip4 = parse(trace).extractdef getFlow() : Flow_ip4 = flow_case}
Un altro codice condiviso da entrambi i framework sono le funzioni per calcolare la distanza euclidea, ottenere le combinazioni di una serie di oggetti e generare il Json dei risultati:
object utils { def euclideanDistance(xs: List, ys: List) = {
sqrt((xs zip ys).map { case (x,y)=> pow(y - x, 2) }.sum)
} def getCombinations(lists : Iterable) = {
lists.toList.combinations(2).map(x=> (x(0),x(1))).toList
} def getAllValuesFromString(flow_case : Flow_ip4) = flow_case.productIterator.drop(1)
.map(_.asInstanceOf.toDouble).toList def calculateDistances(input: Iterable): List = {
val combinations: List = getCombinations(input)
val distances = combinations.map{
case(f1,f2) => (f1.eventid,f2.eventid,euclideanDistance(getAllValuesFromString(f1),
getAllValuesFromString(f2)))}
distances.sortBy(_._3)
} def generateJson(x: (String, String, Double)): String = {
val obj = Map("eventid_1" -> x._1,
"eventid_2" -> x._2,
"distance" -> x._3,
"timestamp" -> System.currentTimeMillis())
val str_obj = scala.util.parsing.json.JSONObject(obj).toString()
str_obj
}
}
Parte specifica di ogni Framework
L’applicazione di trasformazioni e azioni è dove le particolarità di ogni framework impediscono di essere un codice generico.
Come osservato, Flink itera per ogni evento, filtrando, serializzando, raggruppando per IP e tempo e infine applicando il calcolo della distanza per inviarlo a Kafka attraverso un produttore.
In Spark, invece, poiché gli eventi sono già raggruppati per tempo, abbiamo solo bisogno di filtrare, serializzare e raggruppare per IP. Una volta fatto questo, le funzioni di calcolo della distanza vengono applicate e il risultato può essere inviato a Kafka con le librerie appropriate.
Per Flink:
val flow = stream
.filter(!_.contains("src_ip6"))
.map(trace =>{
new Flow(trace).getFlow()
})
.keyBy(_.src_ip4)
.timeWindow(Time.seconds(3))
.apply{(
key: String,
window: TimeWindow,
input: Iterable,
out: Collector]) => {
val distances: List = utils.calculateDistances(input)
out.collect(distances)
}
}
.flatMap(x => x)
flow.map( x=>{
val str_obj: String = utils.generateJson(x)
producer.send(new ProducerRecord(topic_out, str_obj))
})
Per Spark:
val flow = stream.map(_.value())
.filter(!_.contains("src_ip6"))
.map(record => {
implicit val formats = DefaultFormats
val flow = new Flow(record).getFlow()
(flow.src_ip4,flow)
})
.groupByKey()flow.foreachRDD(rdd => {
rdd.foreach{ case (key, input ) => {
val distances = utils.calculateDistances(input)
distances.map(x => {val str_obj: String = utils.generateJson(x)
producer.send(new ProducerRecord(topic_out, str_obj))
})
}}
})
Gli ID di ogni evento, i loro timestamp di ingestione, il risultato del calcolo della distanza e il tempo in cui il calcolo è stato completato sono memorizzati nell’argomento di output di Kafka. Ecco un esempio di traccia:
{
"eventid_1":151852746453199,
"ts_flow1":1495466510792,
"eventid_2":1039884491535740,
"ts_flow2":1495466511125,
"distance":12322.94295207115,
"ts_output":1495466520212
}
Results
Abbiamo eseguito due diversi tipi di test: eventi multipli all’interno di una singola finestra, ed eventi multipli in finestre diverse, dove un fenomeno rende l’algoritmo combinatorio apparentemente stocastico e offre risultati diversi. Ciò si verifica a causa del fatto che i dati vengono ingeriti in modo non ordinato, man mano che arrivano al sistema, senza tener conto del tempo dell’evento, e vengono fatti dei raggruppamenti in base ad esso, il che causerà l’esistenza di diverse combinazioni.
La seguente presentazione di Apache Beam spiega più in dettaglio la differenza tra tempo di elaborazione e tempo dell’evento: https://goo.gl/h5D1yR

Eventi multipli nella stessa finestra
Sono ingeriti circa 10.000 eventi nella stessa finestra, che, applicando le combinazioni per gli stessi IP, richiedono quasi 2 milioni di calcoli. Il tempo totale di calcolo in ogni quadro (cioè la differenza tra il timestamp di uscita più alto e quello più basso) con 8 core di elaborazione è:
- Tempo totale di Spark: 41,50s
- Tempo totale Flink: 40,24s
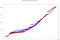
Le linee multiple dello stesso colore sono dovute al parallelismo, poiché ci sono calcoli che finiscono allo stesso tempo.
Eventi multipli in finestre diverse
Più di 50.000 eventi sono inseriti lungo diverse finestre temporali di 3s. È qui che emergono chiaramente le particolarità di ogni motore. Quando tracciamo lo stesso grafico dei tempi di elaborazione, si verifica quanto segue:
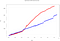
- Tempo totale Spark: 614.1s
- Tempo totale Flink: 869.3s
Si osserva un aumento del tempo di elaborazione per Flink. Questo è dovuto al modo in cui ingerisce gli eventi:

Come si vede nell’ultima figura, Flink non usa micro-batches e parallelizza il windowing degli eventi (a differenza di Spark, usa finestre scorrevoli sovrapposte). Questo causa un tempo di calcolo più lungo, ma un tempo di ingestione più breve. È una delle particolarità di cui dobbiamo tenere conto quando definiamo la nostra architettura di elaborazione dei Big Data in streaming.
E che dire del calcolo?
La distanza euclidea di 10.000 eventi ha la seguente distribuzione:

Si presume che gli eventi anomali siano nella “coda lunga” dell’istogramma. Ma ha davvero senso? Analizziamolo.
In questo caso, alcuni parametri categorici (IP, porta) sono stati considerati come numerici per il calcolo. Abbiamo deciso di farlo per aumentare la dimensionalità e avvicinarci a un problema reale. Ma questo è ciò che otteniamo quando mostriamo tutti i valori reali delle distanze:

Questo è rumore, poiché questi valori (IP, porta, fonte e destinazione) falsano il calcolo. Tuttavia, quando eliminiamo questi campi ed elaboriamo di nuovo tutto, mantenendo:
- durata
- in_bytes
- in_packets
- out_bytes
- out_packets
Abbiamo la seguente distribuzione:

La coda lunga non è più così popolata e c’è qualche picco alla fine. Se mostriamo i valori del calcolo della distanza, possiamo vedere dove sono i valori anomali.

Grazie a questo semplice perfezionamento facilitiamo il lavoro dell’analista, offrendogli un potente strumento, risparmiando tempo e indicando dove trovare i problemi di una rete.
Conclusioni
Anche se si potrebbe discutere un’infinità di possibilità e conclusioni, la conoscenza più notevole ottenuta durante questo piccolo sviluppo è:
- Quadro di elaborazione. Non è banale passare da un framework all’altro, quindi è importante fin dall’inizio decidere quale framework verrà utilizzato e conoscere molto bene le sue particolarità. Per esempio, se abbiamo bisogno di processare un evento istantaneamente e questo è critico per il business, dobbiamo selezionare un motore di elaborazione che soddisfi questo requisito.
- Big Picture. Per certe caratteristiche, un motore si distinguerà dagli altri, ma cosa siete disposti a sacrificare per ottenere questa o quella caratteristica? Gestione della memoria, CPU, disco… È importante applicare stress test, benchmark, ecc. al sistema per sapere come si comporterà nel suo insieme e identificare possibili punti deboli e colli di bottiglia
- Caratteristiche e contesto. È essenziale prendere sempre in considerazione il contesto specifico e sapere quali caratteristiche devono essere introdotte nel sistema. Abbiamo usato parametri come le porte o gli IP nel calcolo delle distanze per cercare di individuare anomalie in una rete. Queste caratteristiche, nonostante siano numeriche, non hanno un senso spaziale tra loro. Tuttavia, ci sono modi per sfruttare questo tipo di dati, ma lo lasciamo per un post futuro.
Questo post è stato originariamente pubblicato su https://www.gradiant.org/noticia/big-data-aplicado-spark-vs-flink/
Grazie a Adrián Portabales ( adrianp )
Leave a Reply