Big Data appliqué : Spark vs Flink

De même que le terme Intelligence Artificielle (IA) a été méprisé pendant de nombreuses années, en 2017, le terme « Big Data » commence à susciter plus de rejet que d’acceptation en raison de son usure quotidienne. Tout est Big Data et tout est résolu avec le Big Data. Mais alors, que font ceux qui travaillent sur le Big Data ?
Le Big Data est lié ces dernières années à de grandes quantités de données structurées ou non structurées produites par des systèmes ou des organisations. Son importance ne réside pas dans les données elles-mêmes, mais dans ce que nous pouvons faire avec ces données. Sur la façon dont les données peuvent être analysées pour prendre de meilleures décisions. Souvent, une grande partie de la valeur qui peut être extraite des données provient de notre capacité à les traiter à temps. D’où l’importance de très bien connaître à la fois les sources de données et le cadre dans lequel nous allons les traiter.
L’un des objectifs initiaux de tous les projets Big Data est de définir l’architecture de traitement qui s’adapte le mieux à un problème spécifique. Cela inclut une immensité de possibilités et d’alternatives :
- Quelles sont les sources ?
- Comment sont stockées les données ?
- Y a-t-il des contraintes de calcul ? Et de temps ?
- Quels algorithmes devons-nous appliquer ?
- Quelle précision devons-nous atteindre ?
- Quelle est la criticité du processus ?
Nous devons très bien connaître notre domaine pour pouvoir répondre à ces questions et fournir des réponses de qualité. Tout au long de ce billet, nous allons proposer une simplification d’un cas d’utilisation réel et comparer deux technologies de traitement des Big Data.
Le cas d’utilisation proposé est l’application de l’architecture Kappa pour le traitement des traces Netflow, en utilisant différents moteurs de traitement.
Netflow est un protocole réseau permettant de collecter des informations sur le trafic IP. Il nous fournit des informations telles que les dates de début et de fin des connexions, les adresses IP source et destination, les ports, les protocoles, les octets de paquets, etc. C’est actuellement un standard pour la surveillance du trafic réseau et il est supporté par différentes plateformes matérielles et logicielles.
Chaque événement contenu dans les traces netflow nous donne des informations étendues d’une connexion établie dans le réseau surveillé. Ces événements sont ingérés via Apache Kafka pour être analysés par le moteur de traitement -dans ce cas Apache Spark ou Apache Flink-, en effectuant une opération simple comme le calcul de la distance euclidienne entre des paires d’événements. Ce type de calculs est fondamental dans les algorithmes de détection d’anomalies.
Cependant, pour effectuer ce traitement, il est nécessaire de regrouper les événements, par exemple à travers des fenêtres temporaires, puisque dans un contexte de streaming pur, les données n’ont pas de début ou de fin.
Une fois que les événements de netflow sont regroupés, le calcul des distances entre les paires produit une explosion combinatoire. Par exemple, dans le cas où nous recevons 1000 événements / s de la même IP, et que nous les regroupons toutes les 5s, chaque fenêtre nécessitera un total de 12 497 500 calculs.
La stratégie à appliquer dépend totalement du moteur de traitement. Dans le cas de Spark, le regroupement des événements est simple car il ne fonctionne pas en streaming mais utilise plutôt le micro-batching, la fenêtre de traitement sera donc toujours définie. Dans le cas de Flink, en revanche, ce paramètre n’est pas obligatoire puisqu’il s’agit d’un moteur purement streaming, il est donc nécessaire de définir la fenêtre de traitement souhaitée dans le code.
Le calcul renverra comme résultat un nouveau flux de données qui sera publié dans un autre sujet Kafka, comme le montre la figure suivante. De cette façon, on obtient une grande flexibilité dans la conception, en étant capable de combiner ce traitement avec d’autres dans des pipelines de données plus complexes.

Architecture Kappa
L’architecture Kappa est un modèle d’architecture logicielle qui utilise des flux de données ou « streams » au lieu d’utiliser des données déjà stockées et persistées. Les sources de données seront, par conséquent, immuables et continues, comme les entrées générées dans un journal. Ces sources d’information contrastent avec les bases de données traditionnelles utilisées dans les systèmes d’analyse par lot ou par lot.
Ces « flux » sont envoyés par un système de traitement et stockés dans des systèmes auxiliaires pour la couche de service.
L’architecture Kappa est une simplification de l’architecture Lambda, dont elle diffère par les aspects suivants :
- Tout est un flux (le batch est un cas particulier)
- Les sources de données sont immuables (les données brutes persistent)
- Il existe un seul cadre analytique (bénéfique pour la maintenance)
- Fonctionnalité de relecture, c’est-à-dire le retraitement de toutes les données analysées jusqu’à présent (par exemple, lorsqu’on a un nouvel algorithme)
En résumé, la partie batch est éliminée, favorisant un système de traitement des données en mouvement.
Mettre la main à la pâte
Pour mieux comprendre tous ces concepts théoriques, rien de mieux que d’approfondir la mise en œuvre. L’un des éléments que nous voulons mettre en pratique avec cette preuve de concept est de pouvoir échanger entre différents moteurs de traitement de manière transparente. En d’autres termes, est-il facile de passer de Spark à Flink à partir du même code Scala ? Malheureusement, les choses ne sont pas si simples, bien qu’il soit possible de parvenir à une solution partielle commune, comme vous pouvez le voir dans les sections suivantes.
Événements Netflow
Chaque événement Netflow fournit des informations sur une connexion spécifique établie dans le réseau. Ces événements sont représentés au format JSON et sont ingérés dans Kafka. Pour simplifier, seules les connexions IPv4 seront utilisées.
Exemple d’événement:
{
"eventid":995491697672682,
"dvc_version":"3.2",
"aproto":"failed",
"src_ip4":168099844,
"dst_ip4":4294967295,
"eventtime":1490024708,
"out_packets":1,
"type":"flow",
"dvc_time":1490024739,
"dst_ip":"255.255.255.255",
"src_ip":"10.5.0.4",
"duration":0,
"in_bytes":0,
"conn_state":"new",
"@version":"1",
"out_bytes":157,
"dvc_type":"suricata",
"in_packets":0,
"nproto":"UDP",
"src_port":42126,
"@timestamp":"2017-03-20T15:45:08.000Z",
"dst_port":40237,
"category":"informational"
}
Pièce partagée
Comme mentionné plus haut, l’un des objectifs de cet article est d’utiliser de manière transparente différents environnements de traitement des Big Data , c’est-à-dire d’utiliser les mêmes fonctions Scala pour Spark, Flink ou les futurs frameworks. Malheureusement, les particularités de chaque framework ont fait que seule une partie du code Scala implémenté peut être commune aux deux.
Le code commun comprend les mécanismes de sérialisation et de désérialisation des événements netflow. Nous nous appuyons sur la bibliothèque json4s de Scala, et définissons une classe de cas avec les champs d’intérêt :
case class Flow_ip4(eventid: String,
dst_ip4: String,
dst_port: String,
duration: String,
in_bytes: String,
in_packets: String,
out_bytes: String,
out_packets: String,
src_ip4: String,
src_port: String) extends Serializable
En outre, l’objet Flow qui implémente cette sérialisation est défini pour pouvoir travailler confortablement avec différents moteurs Big Data :
class Flow(trace: String) extends Serializable {implicit val formats =DefaultFormatsvar flow_case : Flow_ip4 = parse(trace).extractdef getFlow() : Flow_ip4 = flow_case}
Un autre code partagé par les deux frameworks sont les fonctions pour calculer la distance euclidienne, obtenir les combinaisons d’une série d’objets et générer le Json des résultats :
object utils { def euclideanDistance(xs: List, ys: List) = {
sqrt((xs zip ys).map { case (x,y)=> pow(y - x, 2) }.sum)
} def getCombinations(lists : Iterable) = {
lists.toList.combinations(2).map(x=> (x(0),x(1))).toList
} def getAllValuesFromString(flow_case : Flow_ip4) = flow_case.productIterator.drop(1)
.map(_.asInstanceOf.toDouble).toList def calculateDistances(input: Iterable): List = {
val combinations: List = getCombinations(input)
val distances = combinations.map{
case(f1,f2) => (f1.eventid,f2.eventid,euclideanDistance(getAllValuesFromString(f1),
getAllValuesFromString(f2)))}
distances.sortBy(_._3)
} def generateJson(x: (String, String, Double)): String = {
val obj = Map("eventid_1" -> x._1,
"eventid_2" -> x._2,
"distance" -> x._3,
"timestamp" -> System.currentTimeMillis())
val str_obj = scala.util.parsing.json.JSONObject(obj).toString()
str_obj
}
}
Partie spécifique de chaque Framework
L’application des transformations et des actions est là où les particularités de chaque framework l’empêchent d’être un code générique.
Comme on l’a observé, Flink itère par chaque événement, en le filtrant, en le sérialisant, en le regroupant par IP et par temps et enfin en appliquant le calcul de distance pour l’envoyer à Kafka par l’intermédiaire d’un producteur.
Dans Spark, en revanche, puisque les événements sont déjà regroupés par temps, il suffit de filtrer, sérialiser et regrouper par IP. Une fois cela fait, les fonctions de calcul de distance sont appliquées et le résultat peut être envoyé à Kafka avec les bibliothèques appropriées.
Pour Flink:
val flow = stream
.filter(!_.contains("src_ip6"))
.map(trace =>{
new Flow(trace).getFlow()
})
.keyBy(_.src_ip4)
.timeWindow(Time.seconds(3))
.apply{(
key: String,
window: TimeWindow,
input: Iterable,
out: Collector]) => {
val distances: List = utils.calculateDistances(input)
out.collect(distances)
}
}
.flatMap(x => x)
flow.map( x=>{
val str_obj: String = utils.generateJson(x)
producer.send(new ProducerRecord(topic_out, str_obj))
})
Pour Spark:
val flow = stream.map(_.value())
.filter(!_.contains("src_ip6"))
.map(record => {
implicit val formats = DefaultFormats
val flow = new Flow(record).getFlow()
(flow.src_ip4,flow)
})
.groupByKey()flow.foreachRDD(rdd => {
rdd.foreach{ case (key, input ) => {
val distances = utils.calculateDistances(input)
distances.map(x => {val str_obj: String = utils.generateJson(x)
producer.send(new ProducerRecord(topic_out, str_obj))
})
}}
})
Les identifiants de chaque événement, leurs horodatages d’ingestion, le résultat du calcul de distance et l’heure à laquelle le calcul a été effectué sont stockés dans le sujet de sortie Kafka. Voici un exemple de trace :
{
"eventid_1":151852746453199,
"ts_flow1":1495466510792,
"eventid_2":1039884491535740,
"ts_flow2":1495466511125,
"distance":12322.94295207115,
"ts_output":1495466520212
}
Résultats
Nous avons effectué deux types de tests différents : des événements multiples dans une même fenêtre, et des événements multiples dans des fenêtres différentes, où un phénomène rend l’algorithme combinatoire apparemment stochastique et offre des résultats différents. Cela se produit en raison du fait que les données sont ingérées de manière non ordonnée, au fur et à mesure de leur arrivée dans le système, sans tenir compte du temps de l’événement, et que des regroupements sont effectués en fonction de celui-ci, ce qui entraînera l’existence de différentes combinaisons.
La présentation suivante d’Apache Beam explique plus en détail la différence entre le temps de traitement et le temps de l’événement : https://goo.gl/h5D1yR

Multiples événements dans la même fenêtre
Environ 10 000 événements sont ingérés dans la même fenêtre, qui, en appliquant les combinaisons pour les mêmes IP, nécessitent près de 2 millions de calculs. Le temps de calcul total dans chaque cadre (c’est-à-dire la différence entre l’horodatage de sortie le plus élevé et le plus bas) avec 8 cœurs de traitement est :
- Temps total d’Étincelle : 41,50s
- Temps total Flink : 40,24s
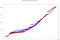
Les multiples lignes de même couleur sont dues au parallélisme, car il y a des calculs qui se terminent au même moment.
Multiples événements dans différentes fenêtres
Plus de 50 000 événements sont insérés le long de différentes fenêtres de temps de 3s. C’est ici que les particularités de chaque moteur apparaissent clairement. Lorsque nous traçons le même graphique des temps de traitement, on obtient ce qui suit :
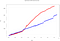
- Temps total d’Étincelle : 614,1s
- Temps total Flink : 869,3s
Nous observons une augmentation du temps de traitement pour Flink. Cela est dû à la façon dont il ingère les événements :

Comme on le voit dans la dernière figure, Flink n’utilise pas de micro-batches et parallélise le fenêtrage des événements (contrairement à Spark, il utilise des fenêtres glissantes qui se chevauchent). Cela entraîne un temps de calcul plus long, mais un temps d’ingestion plus court. C’est une des particularités à prendre en compte lors de la définition de notre architecture de traitement Big Data en streaming.
Et le calcul ?
La distance euclidienne de 10 000 événements a la distribution suivante :

On suppose que les événements anormaux se trouvent dans la « longue queue » de l’histogramme. Mais cela a-t-il vraiment un sens ? Analysons-le.
Dans ce cas, certains paramètres catégoriels (IP, port) sont considérés comme numériques pour le calcul. Nous avons décidé de le faire pour augmenter la dimensionnalité et se rapprocher d’un vrai problème. Mais voici ce que nous obtenons lorsque nous montrons toutes les valeurs réelles des distances:

C’est-à-dire du bruit, puisque ces valeurs (IP, port, source et destination) faussent le calcul. Cependant, lorsque nous éliminons ces champs et que nous traitons tout à nouveau, en conservant :
- durée
- in_bytes
- in_packets
- out_bytes
- out_packets
Nous obtenons la distribution suivante :

La longue queue n’est plus aussi peuplée et il y a un certain pic à la fin. Si nous montrons les valeurs du calcul de la distance, nous pouvons voir où se trouvent les valeurs anormales.

Grâce à ce simple raffinement, nous facilitons le travail de l’analyste, lui offrant un outil puissant, lui permettant de gagner du temps et lui indiquant où trouver les problèmes d’un réseau.
Conclusions
Bien qu’une infinité de possibilités et de conclusions pourraient être discutées, la connaissance la plus remarquable obtenue tout au long de ce petit développement est :
- Cadre de traitement. Il n’est pas trivial de passer d’un framework à un autre, il est donc important dès le départ de décider quel framework va être utilisé et de très bien connaître ses particularités. Par exemple, si nous devons traiter un événement instantanément et que cela est critique pour l’entreprise, nous devons choisir un moteur de traitement qui répond à cette exigence.
- Grande image. Pour certaines fonctionnalités, un moteur se démarquera des autres, mais qu’êtes-vous prêt à sacrifier pour obtenir telle ou telle fonctionnalité ?
- Utilisation des ressources. Gestion de la mémoire, CPU, disque… Il est important d’appliquer des tests de stress, des benchmarks, etc. au système pour savoir comment il va se comporter dans son ensemble et identifier les éventuels points faibles et goulots d’étranglement
- Caractéristiques et contexte. Il est essentiel de toujours prendre en compte le contexte spécifique et de savoir quelles caractéristiques doivent être introduites dans le système. Nous avons utilisé des paramètres tels que les ports ou les IP dans le calcul des distances pour essayer de détecter des anomalies dans un réseau. Ces caractéristiques, bien qu’elles soient numériques, n’ont pas de sens spatial entre elles. Cependant, il existe des moyens de tirer parti de ce type de données, mais nous laissons cela pour un prochain post.
Ce post a été initialement publié sur https://www.gradiant.org/noticia/big-data-aplicado-spark-vs-flink/
Merciements à Adrián Portabales ( adrianp )
.
Leave a Reply