Anscomben kvartetti
Olen aina uskonut siihen, että ”numeeriset laskutoimitukset ovat tarkkoja, mutta kuvaajat ovat karkeita”. Henkilönä, joka on juuri aloittanut data-analytiikan opiskelun, minun oli vaikea ymmärtää datan visualisoinnin merkitystä yhteenvetotilastojen ohella. Mutta kaikki muuttui osallistuttuani tähän Data Visualization Meetupiin, jolloin tutustuin Anscomben kvartettiin.
Anscomben kvartetin kehitti tilastotieteilijä Francis Anscombe. Se koostuu neljästä tietokokonaisuudesta, joista kukin sisältää yksitoista (x,y)-paria. Olennaista näissä tietokokonaisuuksissa on se, että niillä on samat kuvailevat tilastot. Asiat muuttuvat kuitenkin täysin, ja korostan TÄYDELLISESTI, kun ne esitetään graafisesti. Jokainen kuvaaja kertoo eri tarinan riippumatta niiden samankaltaisista yhteenvetotilastoista.
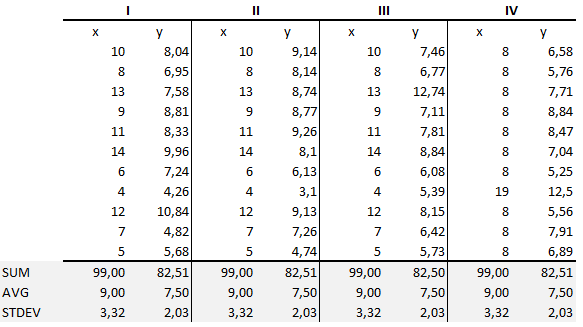
Yhteenvetotilastot osoittavat, että x:n ja y:n keskiarvot ja varianssit olivat ryhmissä identtiset :
- Keskiarvo x:llä on 9 ja keskiarvo y:llä 7.50 kummallakin aineistolla.
- Samoin x:n varianssi on 11 ja y:n varianssi on 4,13 kummallakin aineistolla
- Korrelaatiokerroin (kuinka vahva suhde on kahden muuttujan välillä) x:n ja y:n välillä on 0.816 kummallekin aineistolle
Kun piirretään nämä neljä aineistoa x/y-koordinaattitasolle, voidaan havaita, että niissä näkyvät myös samat regressiosuorat, mutta kukin aineisto kertoo eri tarinan :

- Datasetilla I näyttäisi olevan puhtaat ja hyvin sopivat lineaariset mallit.
- Dataset II ei jakaudu normaalisti.
- Datasetissa III jakauma on lineaarinen, mutta laskettua regressiota heittelee yksi outlier.
- Datasetista IV käy ilmi, että yksi outlier riittää tuottamaan korkean korrelaatiokertoimen.
Tämä kvartetti korostaa visualisoinnin merkitystä data-analyysissä. Datan tarkastelu paljastaa paljon datan rakenteesta ja antaa selkeän kuvan aineistosta.
Tietokoneen tulisi tehdä sekä laskelmia että kuvaaja. Molempia tulostetyyppejä tulisi tutkia; kumpikin edistää ymmärrystä.
Leave a Reply