RL – DQN Deep Q-network

¿Pueden los ordenadores jugar a videojuegos como un humano? En 2015, DQN superó a los expertos humanos en muchos juegos de Atari. Pero una vez que se trata de complejos juegos de estrategia bélica, a la IA no le va bien. En 2017, un equipo profesional venció a un programa de IA de DeepMind en Starcraft 2 con facilidad.
Como se cita en el documento de DeepMind:
Es un problema multiagente con múltiples jugadores interactuando; hay información imperfecta debido a un mapa parcialmente observado; tiene un gran espacio de acción que implica la selección y el control de cientos de unidades; tiene un gran espacio de estado que debe ser observado únicamente a partir de planos de características de entrada en bruto; y ha retrasado la asignación de créditos que requiere estrategias a largo plazo durante miles de pasos.
Reiniciemos nuestro viaje de vuelta a la Deep Q-Network DQN. En el juego Seaquest de abajo, DQN aprende a leer las puntuaciones, disparar al enemigo y rescatar a los buzos de las imágenes en bruto, todo por sí mismo. También descubre conocimientos que podemos denominar como estrategia, como por ejemplo, cuándo llevar el submarino a la superficie para obtener oxígeno.

El aprendizaje Q aprende la función de valor de acción Q(s, a): lo bueno que es tomar una acción en un estado particular. Por ejemplo, para la posición del tablero de abajo, lo bueno que es mover el peón dos pasos hacia adelante. Literalmente, asignamos un valor escalar sobre el beneficio de realizar dicho movimiento.
Q se denomina función acción-valor (o función valor Q en este artículo).

En el aprendizaje Q, construimos una tabla de memoria Q para almacenar los valores Q para todas las posibles combinaciones de s y a. Si eres un jugador de ajedrez, es la hoja de trucos para la mejor jugada. En el ejemplo anterior, podemos darnos cuenta de que mover el peón 2 pasos adelante tiene los valores Q más altos sobre todos los demás. (El consumo de memoria será demasiado alto para el juego de ajedrez. Pero sigamos con este enfoque un poco más.)
Hablando técnicamente, muestreamos una acción del estado actual. Averiguamos la recompensa R (si la hay) y el nuevo estado s’ (la nueva posición del tablero). A partir de la tabla de memoria, determinamos la siguiente acción a’ que tiene el máximo Q(s’, a’).
En un videojuego, ganamos puntos (recompensas) derribando al enemigo. En una partida de ajedrez, la recompensa es +1 cuando ganamos o -1 si perdemos. Así que sólo se da una recompensa y se tarda en conseguirla.
El aprendizaje Q consiste en crear la hoja de trucos Q.

Podemos tomar un solo movimiento a y ver qué recompensa R podemos obtener. Esto crea una mirada de un paso adelante. R + Q(s’, a’) se convierte en el objetivo que queremos que sea Q(s, a). Por ejemplo, digamos que ahora todos los valores de Q son iguales a uno. Si movemos el joystick hacia la derecha y anotamos 2 puntos, queremos acercar Q(s, a) a 3 (es decir, 2 + 1).

A medida que seguimos jugando, mantenemos una media continua para Q. Los valores irán mejorando y con algunos trucos, los valores de Q convergerán.
Algoritmo de aprendizaje de Q
El siguiente es el algoritmo para ajustar Q con las recompensas muestreadas. Si γ (factor de descuento) es menor que uno, hay muchas posibilidades de que Q converja.

Sin embargo, si las combinaciones de estados y acciones son demasiado grandes, la memoria y el requisito de cálculo para Q serán demasiado altos. Para solucionar esto, cambiamos a una red profunda Q (DQN) para aproximar Q(s, a). El algoritmo de aprendizaje se denomina Deep Q-learning. Con el nuevo enfoque, generalizamos la aproximación de la función de valor Q en lugar de recordar las soluciones.
¿Qué desafíos enfrenta la RL en comparación con la DL?
En el aprendizaje supervisado, queremos que la entrada sea i.i.d. (independiente e idénticamente distribuida), es decir,
- Las muestras son aleatorias entre los lotes y, por lo tanto, cada lote tiene la misma (o similar) distribución de datos.
- Las muestras son independientes entre sí en el mismo lote.
Si no es así, el modelo puede estar sobreajustado para alguna clase (o grupos) de muestras en diferentes momentos y la solución no será generalizada.
Además, para la misma entrada, su etiqueta no cambia con el tiempo. Este tipo de condición estable para la entrada y la salida proporciona la condición para que el aprendizaje supervisado funcione bien.
En el aprendizaje por refuerzo, tanto la entrada como el objetivo cambian constantemente durante el proceso y hacen que el entrenamiento sea inestable.
Objetivo inestable: Construimos una red profunda para aprender los valores de Q pero sus valores objetivo van cambiando a medida que conocemos mejor las cosas. Como se muestra a continuación, los valores objetivo de Q dependen del propio Q, estamos persiguiendo un objetivo no estacionario.

i.i.d.: Hay otro problema relacionado con las correlaciones dentro de una trayectoria. Dentro de una iteración de entrenamiento, actualizamos los parámetros del modelo para mover Q(s, a) más cerca de la verdad del terreno. Estas actualizaciones afectarán a otras estimaciones. Cuando subimos los valores Q en la red profunda, los valores Q en los estados circundantes se subirán también como una red.

Digamos que acabamos de obtener una recompensa y ajustamos la red Q para reflejarla. A continuación, hacemos otro movimiento. El nuevo estado se parecerá al último, en particular si utilizamos imágenes en bruto para representar los estados. El nuevo Q(s’, a’) será mayor y nuestro nuevo objetivo para Q se moverá más alto también, independientemente del mérito de la nueva acción. Si actualizamos la red con una secuencia de acciones en la misma trayectoria, se magnifica el efecto más allá de nuestra intención. Esto desestabiliza el proceso de aprendizaje y parece que los perros se persiguen la cola.
¿Cuál es el reto fundamental en el entrenamiento de RL? En RL, a menudo dependemos de la política o de las funciones de valor para muestrear las acciones. Sin embargo, esto cambia con frecuencia a medida que sabemos mejor qué explorar. A medida que jugamos, conocemos mejor los valores reales de los estados y las acciones. Así que nuestros objetivos de salida también cambian. Ahora, tratamos de aprender un mapa f para una entrada y una salida que cambian constantemente. Así que si ralentizamos los cambios tanto en la entrada como en la salida lo suficiente, podemos tener una oportunidad de modelar f mientras le permitimos evolucionar.
Soluciones
Repetición de la experiencia: Por ejemplo, ponemos el último millón de transiciones (o fotogramas de vídeo) en un buffer y muestreamos un mini lote de muestras de tamaño 32 de este buffer para entrenar la red profunda. Esto forma un conjunto de datos de entrada lo suficientemente estable para el entrenamiento. Como muestreamos aleatoriamente del búfer de repetición, los datos son más independientes entre sí y se acercan más al i.i.d.
Red objetivo: Creamos dos redes profundas θ- y θ. Utilizamos la primera para recuperar los valores de Q mientras que la segunda incluye todas las actualizaciones en el entrenamiento. Después de, digamos, 100.000 actualizaciones, sincronizamos θ- con θ. El propósito es fijar los objetivos de valores Q temporalmente para que no tengamos un objetivo móvil que perseguir. Además, los cambios en los parámetros no tienen un impacto inmediato en θ- y, por tanto, aunque la entrada no sea 100% i.i.d, no magnificará incorrectamente su efecto como se mencionó antes.

Con la repetición de la experiencia y la red objetivo, tenemos una entrada y una salida más estables para entrenar la red y se comporta más como un entrenamiento supervisado.
La repetición de la experiencia tiene la mayor mejora de rendimiento en DQN. La mejora de la red objetivo es significativa pero no tan crítica como la repetición. Pero se vuelve más importante cuando la capacidad de la red es pequeña.
Aprendizaje Q profundo con repetición de experiencia
Aquí está el algoritmo:

donde ϕ preprocesan los últimos 4 fotogramas de imagen para representar el estado. Para capturar el movimiento, utilizamos cuatro fotogramas para representar un estado.
Detalles de la implementación
Función de pérdida
Vamos a repasar algunos detalles más de la implementación para mejorar el rendimiento. DQN utiliza la pérdida de Huber (curva verde) donde la pérdida es cuadrática para valores pequeños de a, y lineal para valores grandes.


La introducción de la pérdida de Huber permite cambios menos drásticos que suelen perjudicar a RL.
Optimización
El entrenamiento de RL es sensible a los métodos de optimización. La programación de la tasa de aprendizaje simple no es lo suficientemente dinámica para manejar los cambios en la entrada durante el entrenamiento. Muchos entrenamientos de RL utilizan RMSProp o el optimizador Adam. DQN se entrena con RMSProp. El uso del método de optimización avanzada en los métodos de Gradiente de Política también está muy estudiado.
ϵ-greedy
DQN utiliza ϵ-greedy para seleccionar la primera acción.
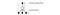
Para mejorar el entrenamiento, ϵ comienza en 1 y se recrea en 0.1 o 0,05 durante el primer millón de fotogramas utilizando la siguiente política.

donde m es el número de acciones posibles. Al principio del entrenamiento, seleccionamos uniformemente las acciones posibles, pero a medida que avanza el entrenamiento, seleccionamos la acción óptima a* con más frecuencia. Esto permite la máxima exploración al principio que eventualmente cambia a la explotación.
Pero incluso durante las pruebas, podemos mantener ϵ a un valor pequeño como 0,05. Una política determinista puede atascarse en un óptimo local. Una política no determinista nos permite salir para tener una oportunidad de alcanzar un óptimo mejor.

Arquitectura
Aquí está la arquitectura DQN. Tomamos los últimos 4 fotogramas de vídeo anteriores y los introducimos en capas convolucionales seguidas de capas totalmente conectadas para calcular los valores Q de cada acción.

En el ejemplo siguiente, si no movemos la pala hacia arriba en el fotograma 3, perderemos la pelota. Como se espera del DQN, el valor Q de mover la paleta hacia arriba es mucho mayor en comparación con otras acciones.


Mejoras al DQN
Se han hecho muchas mejoras al DQN. En esta sección, mostraremos algunos métodos que demuestran mejoras significativas.
Doble DQN
En el aprendizaje Q, utilizamos la siguiente fórmula para el valor objetivo de Q.

Sin embargo, la operación max crea un sesgo positivo hacia las estimaciones de Q.

Del ejemplo anterior, vemos que max Q(s, a) es mayor que el valor convergente 1.0. Es decir, la operación max sobreestima Q. Según la teoría y los experimentos, el rendimiento de DQN mejora si utilizamos la red en línea θ para seleccionar la acción de forma codiciosa y la red objetivo θ- para estimar el valor de Q.

Repetición de experiencia priorizada
DQN muestrea las transiciones del buffer de repetición uniformemente. Sin embargo, deberíamos prestar menos atención a las muestras que ya están cerca del objetivo. Deberíamos muestrear las transiciones que tienen una gran brecha en el objetivo:

Por lo tanto, podemos seleccionar las transiciones de la memoria intermedia
- basándonos en el valor de error anterior (elegir las transiciones con mayor error con más frecuencia), o
- clasificarlas según el valor de error y seleccionarlas por rango (elegir la de mayor rango con más frecuencia).
Para más detalles sobre las ecuaciones de los datos de muestreo, consulte el documento Prioritized Experience Replay.
Duelo DQN
En el Duelo DQN, Q se calcula con una fórmula diferente a continuación con la función de valor V y una función de ventaja de acción dependiente del estado A a continuación:

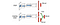
En lugar de aprender Q, utilizamos dos cabezas separadas para calcular V y A. Los experimentos empíricos muestran que el rendimiento mejora. DQN actualiza la función de valor Q de un estado sólo para una acción específica. Dueling DQN actualiza V que otras actualizaciones de Q(s, a’) pueden aprovechar también. Así que cada iteración de entrenamiento de Dueling DQN se cree que tiene un mayor impacto.
Noisy Nets for Exploration
DQN utiliza ϵ-greedy para seleccionar acciones. Alternativamente, NoisyNet lo sustituye añadiendo ruido paramétrico a la capa lineal para ayudar a la exploración. En NoisyNet, no se utiliza ε-greedy. Utiliza un método codicioso para seleccionar acciones a partir de la función de valor Q. Pero para las capas totalmente conectadas del aproximador Q, añadimos ruido parametrizado entrenable a continuación para explorar las acciones. Añadir ruido a una red profunda es a menudo equivalente o mejor que añadir ruido a una acción como la del método ϵ-greedy.

Más pensamientos
DQN pertenece a una clase importante de RL, a saber, el aprendizaje de valores. En la práctica, a menudo combinamos gradientes de política con métodos de aprendizaje de valores para resolver problemas de la vida real.
Leave a Reply