Máquinas de Boltzmann restringidas – Simplificado
¿Qué son las máquinas de Boltzmann restringidas?
Las RBM son una red neuronal artificial de dos capas con capacidades generativas. Tienen la capacidad de aprender una distribución de probabilidad sobre su conjunto de entrada. Las RBM fueron inventadas por Geoffrey Hinton y pueden utilizarse para la reducción de la dimensionalidad, la clasificación, la regresión, el filtrado colaborativo, el aprendizaje de características y el modelado de temas.
Las RBM son una clase especial de máquinas de Boltzmann y están restringidas en cuanto a las conexiones entre las unidades visibles y las ocultas. Esto facilita su implementación en comparación con las máquinas de Boltzmann. Como ya se ha dicho, son una red neuronal de dos capas (una es la capa visible y la otra es la capa oculta) y estas dos capas están conectadas por un grafo totalmente bipartito. Esto significa que cada nodo de la capa visible está conectado a cada nodo de la capa oculta, pero no hay dos nodos del mismo grupo conectados entre sí. Esta restricción permite algoritmos de entrenamiento más eficientes que los disponibles para la clase general de máquinas de Boltzmann, en particular, el algoritmo de divergencia contrastiva basado en el gradiente.
Una máquina de Boltzmann restringida tiene el siguiente aspecto:
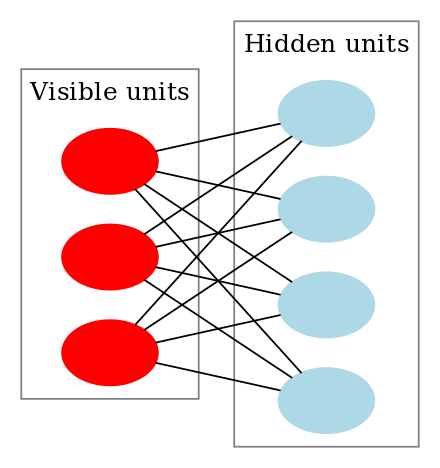
¿Cómo funcionan las máquinas de Boltzmann restringidas?
En una RBM, tenemos un grafo bipartito simétrico en el que no hay dos unidades dentro del mismo grupo conectadas. Las RBMs múltiples también pueden ser stacked y pueden ser afinadas a través del proceso de descenso de gradiente y retropropagación. Una red de este tipo se denomina red de creencia profunda. Aunque las RBMs se utilizan ocasionalmente, la mayoría de la gente en la comunidad de aprendizaje profundo ha comenzado a reemplazar su uso con Redes Adversariales Generales o Autocodificadores Variacionales.
RBM es una Red Neural Estocástica lo que significa que cada neurona tendrá algún comportamiento aleatorio cuando se active. Hay otras dos capas de unidades de sesgo (sesgo oculto y sesgo visible) en una RBM. Esto es lo que diferencia a las RBM de los autocodificadores. Los RBM de sesgo oculto producen la activación en el pase hacia adelante y el sesgo visible ayuda a los RBM a reconstruir la entrada durante un pase hacia atrás. La entrada reconstruida es siempre diferente de la entrada real, ya que no hay conexiones entre las unidades visibles y, por tanto, no hay forma de transferir información entre ellas.

La imagen anterior muestra el primer paso en el entrenamiento de un RBM con múltiples entradas. Las entradas se multiplican por los pesos y luego se añaden al sesgo. El resultado se pasa por una función de activación sigmoidea y la salida determina si el estado oculto se activa o no. Los pesos serán una matriz con el número de nodos de entrada como número de filas y el número de nodos ocultos como número de columnas. El primer nodo oculto recibirá la multiplicación vectorial de las entradas multiplicada por la primera columna de pesos antes de que se le añada el término de sesgo correspondiente.
Y si te preguntas qué es una función sigmoidea, aquí tienes la fórmula:

Entonces la ecuación que obtenemos en este paso sería,
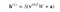
donde h(1) y v(0) son los vectores correspondientes (matrices de columnas) para las capas oculta y visible con el superíndice como iteración (v(0) significa la entrada que proporcionamos a la red) y a es el vector de sesgo de la capa oculta.
(Ten en cuenta que aquí estamos tratando con vectores y matrices y no con valores unidimensionales.)

Ahora esta imagen muestra la fase inversa o de reconstrucción. Es similar a la primera pasada pero en sentido contrario. La ecuación resulta ser:
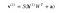
Leave a Reply