Big Data aplicado: Spark vs Flink

Así como el término Inteligencia Artificial (IA) ha sido despreciado durante muchos años, justo en 2017 ‘Big Data’ empieza a ser algo que genera más rechazo que aceptación por el desgaste diario y el bombardeo. Todo es Big Data y todo se resuelve con Big Data. Pero entonces, ¿qué hacemos los que trabajamos en Big Data?
El Big Data se ha relacionado en los últimos años con grandes cantidades de datos estructurados o no estructurados producidos por sistemas u organizaciones. Su importancia no radica en los datos en sí, sino en lo que podemos hacer con esos datos. En cómo se pueden analizar los datos para tomar mejores decisiones. A menudo, gran parte del valor que puede extraerse de los datos proviene de nuestra capacidad para procesarlos a tiempo. De ahí que sea importante conocer muy bien tanto las fuentes de datos como el marco en el que vamos a procesarlos.
Uno de los objetivos iniciales en todo proyecto de Big Data es definir la arquitectura de procesamiento que mejor se adapte a un problema concreto. Esto incluye una inmensidad de posibilidades y alternativas:
- ¿Cuáles son las fuentes?
- ¿Cómo se almacenan los datos?
- ¿Existen restricciones computacionales? Y de tiempo?
- ¿Qué algoritmos debemos aplicar?
- ¿Qué precisión debemos alcanzar?
- ¿Cómo de crítico es el proceso?
Necesitamos conocer muy bien nuestro dominio para poder responder a estas preguntas y dar respuestas de calidad. A lo largo de este post, propondremos una simplificación de un caso de uso real y compararemos dos tecnologías de procesamiento de Big Data.
El caso de uso propuesto es la aplicación de la arquitectura Kappa para el procesamiento de trazas Netflow, utilizando diferentes motores de procesamiento.
Netflow es un protocolo de red para recoger información sobre el tráfico IP. Nos proporciona información como las fechas de inicio y fin de las conexiones, direcciones IP de origen y destino, puertos, protocolos, bytes de paquetes, etc. Actualmente es un estándar para la monitorización del tráfico de red y está soportado por diferentes plataformas de hardware y software.
Cada evento contenido en las trazas de netflow nos da información ampliada de una conexión establecida en la red monitorizada. Estos eventos son ingeridos a través de Apache Kafka para ser analizados por el motor de procesamiento -en este caso Apache Spark o Apache Flink-, realizando una operación sencilla como es el cálculo de la distancia euclidiana entre pares de eventos. Este tipo de cálculos son básicos en los algoritmos de detección de anomalías.
Sin embargo, para realizar este procesamiento es necesario agrupar los eventos, por ejemplo a través de ventanas temporales, ya que en un contexto puramente de streaming los datos carecen de un principio o un final.
Una vez agrupados los eventos de netflow, el cálculo de distancias entre pares produce una explosión combinatoria. Por ejemplo, en el caso de que recibamos 1000 eventos/s de una misma IP, y los agrupemos cada 5s, cada ventana requerirá un total de 12.497.500 cálculos.
La estrategia a aplicar es totalmente dependiente del motor de procesamiento. En el caso de Spark, la agrupación de eventos es sencilla ya que no trabaja en streaming sino que utiliza el micro-batching, por lo que la ventana de procesamiento siempre estará definida. En el caso de Flink, sin embargo, este parámetro no es obligatorio ya que es un motor puramente de streaming, por lo que es necesario definir la ventana de procesamiento deseada en el código.
El cálculo devolverá como resultado un nuevo flujo de datos que se publicará en otro tema de Kafka, como se muestra en la siguiente figura. De esta forma se consigue una gran flexibilidad en el diseño, pudiendo combinar este procesamiento con otros en pipelines de datos más complejos.

Arquitectura Kappa
La arquitectura Kappa es un patrón de arquitectura de software que utiliza flujos de datos o «streams» en lugar de utilizar datos ya almacenados y persistentes. Las fuentes de datos serán, por tanto, inmutables y continuas, como las entradas generadas en un registro. Estas fuentes de información contrastan con las tradicionales bases de datos utilizadas en los sistemas de análisis por lotes o batch.
Estos «streams» se envían a través de un sistema de procesamiento y se almacenan en sistemas auxiliares para la capa de servicio.
La arquitectura Kappa es una simplificación de la arquitectura Lambda, de la que se diferencia en los siguientes aspectos:
- Todo es un stream (el batch es un caso particular)
- Las fuentes de datos son inmutables (los datos brutos persisten)
- Hay un único marco analítico (beneficioso para el mantenimiento)
- Funcionalidad de reproducción, es decir, reprocesar todos los datos analizados hasta el momento (por ejemplo, al tener un nuevo algoritmo)
En resumen, se elimina la parte del lote, favoreciendo un sistema de procesamiento de datos en movimiento.
Mancharse las manos
Para entender mejor todos estos conceptos teóricos, nada mejor que profundizar en la implementación. Uno de los elementos que queremos poner en práctica con esta prueba de concepto es poder intercambiar entre diferentes motores de procesamiento de forma transparente. Es decir, que sea fácil cambiar entre Spark y Flink partiendo del mismo código Scala. Desgraciadamente, las cosas no son tan sencillas, aunque es posible llegar a una solución parcial común, como se puede ver en las siguientes secciones.
Eventos Netflow
Cada evento Netflow proporciona información sobre una conexión específica establecida en la red. Estos eventos se representan en formato JSON y se ingieren en Kafka. Por simplicidad, sólo se utilizarán conexiones IPv4.
Ejemplo de evento:
{
"eventid":995491697672682,
"dvc_version":"3.2",
"aproto":"failed",
"src_ip4":168099844,
"dst_ip4":4294967295,
"eventtime":1490024708,
"out_packets":1,
"type":"flow",
"dvc_time":1490024739,
"dst_ip":"255.255.255.255",
"src_ip":"10.5.0.4",
"duration":0,
"in_bytes":0,
"conn_state":"new",
"@version":"1",
"out_bytes":157,
"dvc_type":"suricata",
"in_packets":0,
"nproto":"UDP",
"src_port":42126,
"@timestamp":"2017-03-20T15:45:08.000Z",
"dst_port":40237,
"category":"informational"
}
Parte compartida
Como se ha mencionado anteriormente, uno de los objetivos de este artículo es utilizar de forma transparente diferentes entornos de procesamiento de Big Data , es decir, utilizar las mismas funciones de Scala para Spark, Flink o futuros frameworks. Lamentablemente, las peculiaridades de cada framework han hecho que sólo una parte del código Scala implementado pueda ser común para ambos.
El código común incluye los mecanismos para serializar y deserializar los eventos de netflow. Nos apoyamos en la librería json4s de Scala, y definimos una clase case con los campos de interés:
case class Flow_ip4(eventid: String,
dst_ip4: String,
dst_port: String,
duration: String,
in_bytes: String,
in_packets: String,
out_bytes: String,
out_packets: String,
src_ip4: String,
src_port: String) extends Serializable
Además, se define el objeto Flow que implementa esta serialización para poder trabajar cómodamente con diferentes motores de Big Data:
class Flow(trace: String) extends Serializable {implicit val formats =DefaultFormatsvar flow_case : Flow_ip4 = parse(trace).extractdef getFlow() : Flow_ip4 = flow_case}
Otro código compartido por ambos frameworks son las funciones para calcular la distancia euclidiana, obtener las combinaciones de una serie de objetos y generar el Json de resultados:
object utils { def euclideanDistance(xs: List, ys: List) = {
sqrt((xs zip ys).map { case (x,y)=> pow(y - x, 2) }.sum)
} def getCombinations(lists : Iterable) = {
lists.toList.combinations(2).map(x=> (x(0),x(1))).toList
} def getAllValuesFromString(flow_case : Flow_ip4) = flow_case.productIterator.drop(1)
.map(_.asInstanceOf.toDouble).toList def calculateDistances(input: Iterable): List = {
val combinations: List = getCombinations(input)
val distances = combinations.map{
case(f1,f2) => (f1.eventid,f2.eventid,euclideanDistance(getAllValuesFromString(f1),
getAllValuesFromString(f2)))}
distances.sortBy(_._3)
} def generateJson(x: (String, String, Double)): String = {
val obj = Map("eventid_1" -> x._1,
"eventid_2" -> x._2,
"distance" -> x._3,
"timestamp" -> System.currentTimeMillis())
val str_obj = scala.util.parsing.json.JSONObject(obj).toString()
str_obj
}
}
Parte específica de cada Framework
La aplicación de transformaciones y acciones es donde las particularidades de cada framework impiden que sea un código genérico.
Como se ha observado, Flink itera por cada evento, filtrando, serializando, agrupando por IP y tiempo y finalmente aplicando el cálculo de distancia para enviarlo a Kafka a través de un productor.
En Spark, en cambio, como los eventos ya están agrupados por tiempo, sólo tenemos que filtrar, serializar y agrupar por IP. Una vez hecho esto, se aplican las funciones de cálculo de distancia y se puede enviar el resultado a Kafka con las librerías adecuadas.
Para Flink:
val flow = stream
.filter(!_.contains("src_ip6"))
.map(trace =>{
new Flow(trace).getFlow()
})
.keyBy(_.src_ip4)
.timeWindow(Time.seconds(3))
.apply{(
key: String,
window: TimeWindow,
input: Iterable,
out: Collector]) => {
val distances: List = utils.calculateDistances(input)
out.collect(distances)
}
}
.flatMap(x => x)
flow.map( x=>{
val str_obj: String = utils.generateJson(x)
producer.send(new ProducerRecord(topic_out, str_obj))
})
Para Spark:
val flow = stream.map(_.value())
.filter(!_.contains("src_ip6"))
.map(record => {
implicit val formats = DefaultFormats
val flow = new Flow(record).getFlow()
(flow.src_ip4,flow)
})
.groupByKey()flow.foreachRDD(rdd => {
rdd.foreach{ case (key, input ) => {
val distances = utils.calculateDistances(input)
distances.map(x => {val str_obj: String = utils.generateJson(x)
producer.send(new ProducerRecord(topic_out, str_obj))
})
}}
})
En el tema de salida de Kafka se almacenan los IDs de cada evento, sus timestamps de ingesta, el resultado del cálculo de distancia y la hora a la que se completó el cálculo. A continuación se muestra un ejemplo de rastreo:
{
"eventid_1":151852746453199,
"ts_flow1":1495466510792,
"eventid_2":1039884491535740,
"ts_flow2":1495466511125,
"distance":12322.94295207115,
"ts_output":1495466520212
}
Resultados
Hemos realizado dos tipos diferentes de pruebas: múltiples eventos dentro de una misma ventana, y múltiples eventos en diferentes ventanas, donde un fenómeno hace que el algoritmo combinatorio sea aparentemente estocástico y ofrezca diferentes resultados. Esto ocurre debido a que los datos se ingieren de forma desordenada, a medida que llegan al sistema, sin tener en cuenta el tiempo del evento, y se hacen agrupaciones en base a él, lo que hará que existan diferentes combinaciones.
La siguiente presentación de Apache Beam explica con más detalle la diferencia entre el tiempo de procesamiento y el tiempo del evento: https://goo.gl/h5D1yR

Múltiples eventos en la misma ventana
Se ingieren alrededor de 10.000 eventos en la misma ventana que, aplicando las combinaciones para las mismas IP, requieren casi 2 millones de cálculos. El tiempo total de cálculo en cada marco (es decir, la diferencia entre la marca de tiempo de salida más alta y la más baja) con 8 núcleos de procesamiento es:
- Tiempo total de Spark: 41,50s
- Tiempo total Flink: 40,24s
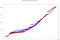
Las múltiples líneas del mismo color se deben al paralelismo, ya que hay cálculos que terminan a la vez.
Múltiples eventos en diferentes ventanas
Más de 50.000 eventos se insertan a lo largo de diferentes ventanas de tiempo de 3s. Aquí es donde surgen claramente las particularidades de cada motor. Si trazamos la misma gráfica de tiempos de procesamiento, ocurre lo siguiente:
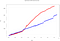
- Tiempo total de Spark: 614,1s
- Tiempo total Flink: 869,3s
Observamos un aumento del tiempo de procesamiento para Flink. Esto se debe a la forma en que ingiere los eventos:

Como se ve en la última figura, Flink no utiliza microlotes y paraleliza la ventana de eventos (a diferencia de Spark, utiliza ventanas deslizantes superpuestas). Esto provoca un mayor tiempo de cálculo, pero un menor tiempo de ingesta. Es una de las particularidades que debemos tener en cuenta a la hora de definir nuestra arquitectura de procesamiento de Big Data en streaming.
¿Y qué pasa con el cálculo?
La distancia euclidiana de 10.000 eventos tiene la siguiente distribución:

Se supone que los eventos anómalos están en la «cola larga» del histograma. Pero, ¿tiene realmente sentido? Analicémoslo.
En este caso, ciertos parámetros categóricos (IP, puerto) están siendo considerados como numéricos para el cálculo. Decidimos hacerlo así para aumentar la dimensionalidad y acercarnos a un problema real. Pero esto es lo que obtenemos cuando mostramos todos los valores reales de las distancias:

Es decir, ruido, ya que estos valores (IP, puerto, origen y destino) distorsionan el cálculo. Sin embargo, cuando eliminamos estos campos y procesamos todo de nuevo, manteniendo:
- duración
- in_bytes
- in_paquetes
- out_bytes
- out_paquetes
Obtenemos la siguiente distribución:

La cola larga ya no está tan poblada y hay algún pico al final. Si mostramos los valores del cálculo de la distancia, podemos ver dónde están los valores anómalos.

Gracias a este sencillo refinamiento facilitamos el trabajo del analista, ofreciéndole una potente herramienta, ahorrando tiempo y señalando dónde encontrar los problemas de una red.
Conclusiones
Aunque se podrían discutir infinidad de posibilidades y conclusiones, el conocimiento más destacable obtenido a lo largo de este pequeño desarrollo es:
- Marco de procesamiento. No es trivial pasar de un framework a otro, por lo que es importante desde el principio decidir qué framework se va a utilizar y conocer muy bien sus particularidades. Por ejemplo, si necesitamos procesar un evento de forma instantánea y esto es crítico para el negocio, debemos seleccionar un motor de procesamiento que cumpla con este requisito.
- Visión de conjunto. Para ciertas características, un motor destacará sobre otros, pero ¿qué está dispuesto a sacrificar para obtener tal o cual característica?
- Uso de recursos. Gestión de memoria, CPU, disco… Es importante aplicar pruebas de estrés, benchmarks, etc. al sistema para saber cómo se comportará en su conjunto e identificar posibles puntos débiles y cuellos de botella
- Características y contexto. Es fundamental tener siempre en cuenta el contexto específico y saber qué características hay que introducir en el sistema. Hemos utilizado parámetros como los puertos o las IPs en el cálculo de las distancias para intentar detectar anomalías en una red. Estas características, a pesar de ser numéricas, no tienen un sentido espacial entre ellas. Sin embargo, hay formas de aprovechar este tipo de datos, pero lo dejamos para un futuro post.
Este post fue publicado originalmente en https://www.gradiant.org/noticia/big-data-aplicado-spark-vs-flink/
Gracias a Adrián Portabales ( adrianp )
Leave a Reply