Restricted Boltzmann Machines – forenklet
Hvad er Restricted Boltzmann Machines?
RBM’er er et kunstig neuralt netværk i to lag med generative egenskaber. De har evnen til at lære en sandsynlighedsfordeling over sit sæt af input. RBM’er blev opfundet af Geoffrey Hinton og kan anvendes til dimensionalitetsreduktion, klassifikation, regression, kollaborativ filtrering, indlæring af funktioner og emne-modellering.
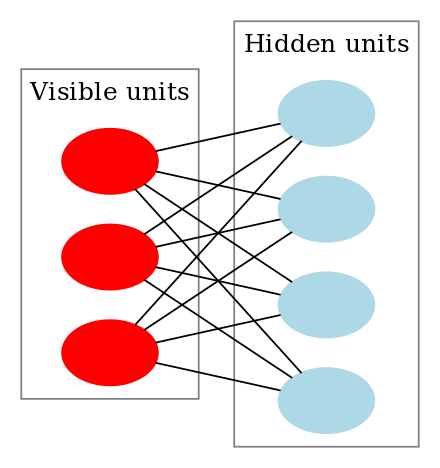
RBM’er er en særlig klasse af Boltzmann-maskiner, og de er begrænsede med hensyn til forbindelserne mellem de synlige og de skjulte enheder. Dette gør det let at implementere dem sammenlignet med Boltzmann-maskiner. Som tidligere nævnt er de et neuralt netværk med to lag (det ene er det synlige lag og det andet er det skjulte lag), og disse to lag er forbundet af en fuldt bipartite graf. Det betyder, at hver knude i det synlige lag er forbundet med hver knude i det skjulte lag, men at to knuder i samme gruppe ikke er forbundet med hinanden. Denne begrænsning giver mulighed for mere effektive træningsalgoritmer end dem, der er tilgængelige for den generelle klasse af Boltzmann-maskiner, navnlig den gradientbaserede kontrastdivergensalgoritme.
En Restricted Boltzmann Machine ser således ud:
Hvordan virker Restricted Boltzmann Machines?
I en RBM har vi en symmetrisk bipartite graf, hvor ingen to enheder inden for samme gruppe er forbundet. Flere RBM’er kan også stacked og kan finjusteres gennem processen med gradientafstigning og back-propagation. Et sådant netværk kaldes et Deep Belief Network. Selv om RBM’er lejlighedsvis anvendes, er de fleste i det dybe læringsfællesskab begyndt at erstatte brugen af dem med General Adversarial Networks eller Variational Autoencoders.
RBM er et stokastisk neuralt netværk, hvilket betyder, at hver neuron vil have en vis tilfældig adfærd, når den aktiveres. Der er to andre lag af bias-enheder (skjult bias og synlig bias) i et RBM. Det er dette, der gør RBM’er forskellige fra autoenkodere. Den skjulte bias RBM producerer aktiveringen i den fremadgående passage, og den synlige bias hjælper RBM med at rekonstruere input i en bagudgående passage. Det rekonstruerede input er altid forskelligt fra det faktiske input, da der ikke er nogen forbindelser mellem de synlige enheder og derfor ingen måde at overføre information indbyrdes.

Overstående billede viser det første trin i træningen af en RBM med flere inputs. Indgangene multipliceres med vægtene og lægges derefter til bias. Resultatet sendes derefter gennem en sigmoid aktiveringsfunktion, og outputtet bestemmer, om den skjulte tilstand bliver aktiveret eller ej. Vægtene vil være en matrix med antallet af indgangsknuder som antal rækker og antallet af skjulte knuder som antal kolonner. Den første skjulte knude vil modtage vektormultiplikationen af indgangene ganget med den første kolonne af vægte, før det tilsvarende bias-term tilføjes til den.
Og hvis du undrer dig over, hvad en sigmoidfunktion er, er her formlen:

Så den ligning, vi får i dette trin, ville være,
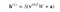
hvor h(1) og v(0) er de tilsvarende vektorer (kolonne matricer) for det skjulte og det synlige lag med overstregning som iteration (v(0) betyder det input, som vi giver netværket) og a er det skjulte lag bias-vektor.
(Bemærk, at vi har med vektorer og matricer at gøre her og ikke med endimensionale værdier.)

Nu viser dette billede den omvendte fase eller rekonstruktionsfasen. Den svarer til den første fase, men i den modsatte retning. Ligningen kommer ud til at være:
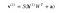
Leave a Reply