Anscombe’s Quartet
Jeg har altid troet på, at “numeriske beregninger er nøjagtige, men grafer er grove”. Da jeg kommer fra en person, der lige er begyndt at lære Data Analytics, var det svært for mig at forstå vigtigheden af Data Visualization sammen med summarisk statistik. Men det hele ændrede sig efter at have deltaget i dette Data Visualization Meetup, hvor jeg blev introduceret til Anscombe’s Quartet.
Anscombe’s Quartet blev udviklet af statistiker Francis Anscombe. Den består af fire datasæt, der hver indeholder elleve (x,y)-par. Det vigtigste at bemærke om disse datasæt er, at de har de samme beskrivende statistikker. Men tingene ændrer sig fuldstændigt, og jeg må understrege FULDSTÆNDIGT, når de grafisk fremstilles. Hver graf fortæller en anden historie, uanset at deres sammenfattende statistikker er ens.
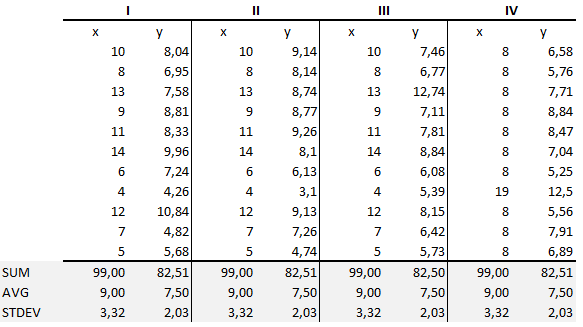
De sammenfattende statistikker viser, at middelværdierne og varianserne var identiske for x og y på tværs af grupperne :
- Middelværdien for x er 9 og middelværdien for y er 7.50 for hvert datasæt.
- Sådan er variansen for x 11 og variansen for y 4,13 for hvert datasæt
- Korrelationskoefficienten (hvor stærk en sammenhæng er mellem to variabler) mellem x og y er 0.816 for hvert datasæt
Når vi plotter disse fire datasæt på et x/y-koordinatplan, kan vi konstatere, at de også viser de samme regressionslinjer, men at hvert datasæt fortæller en anden historie :

- Datasæt I ser ud til at have rene og veltilpassede lineære modeller.
- Datasæt II er ikke normalt fordelt.
- I datasæt III er fordelingen lineær, men den beregnede regression er forstyrret af en outlier.
- Datasæt IV viser, at en outlier er nok til at give en høj korrelationskoefficient.
Denne kvartet understreger vigtigheden af visualisering i dataanalyse. Når man ser på dataene, afslører man meget af strukturen og får et klart billede af datasættet.
En computer skal lave både beregninger og graf. Begge slags output bør studeres; de vil hver især bidrage til forståelsen.
Leave a Reply