RL – DQN Deep Q-network

Mohou počítače hrát videohry jako člověk? V roce 2015 porazil DQN lidské experty v mnoha hrách Atari. Jakmile však dojde na složité válečné strategické hry, AI si nevede dobře. V roce 2017 profesionální tým snadno porazil program umělé inteligence DeepMind ve hře Starcraft 2.
Citujeme z článku společnosti DeepMind:
Jedná se o multi-agentní problém s interakcí více hráčů; existuje nedokonalá informace kvůli částečně pozorované mapě; má velký akční prostor zahrnující výběr a řízení stovek jednotek; má velký stavový prostor, který musí být pozorován výhradně ze surových rovin vstupních funkcí; a má zpožděné přidělování kreditů vyžadující dlouhodobé strategie v tisících krocích.
Znovu začneme naši cestu zpět k hluboké Q-síti DQN. V níže uvedené hře Seaquest se síť DQN sama učí číst skóre, střílet na nepřítele a zachraňovat potápěče ze surových snímků. Zjišťuje také znalosti, které můžeme označit jako strategii, například kdy vynést ponorku na hladinu pro kyslík.

Q-learning se učí funkci hodnoty akce Q(s, a): jak dobře provést akci v určitém stavu. Například pro níže uvedenou pozici na šachovnici, jak je dobré posunout pěšce o dva kroky vpřed. Doslova přiřadíme skalární hodnotu nad výhodnost provedení takového tahu.
Q se nazývá funkce hodnoty akce (nebo v tomto článku funkce hodnoty Q).

Při učení Q sestavujeme paměťovou tabulku Q, do které ukládáme hodnoty Q pro všechny možné kombinace s a. Pokud jste šachista, je to tahová tabulka pro nejlepší tah. Ve výše uvedeném příkladu si můžeme uvědomit, že přesun pěšce o 2 kroky dopředu má nejvyšší hodnoty Q oproti všem ostatním. (Spotřeba paměti bude pro šachovou hru příliš vysoká. Ale zůstaňme u tohoto přístupu ještě chvíli.“
Technicky řečeno, z aktuálního stavu vybíráme vzorek akce. Zjistíme odměnu R (pokud existuje) a nový stav s‘ (novou pozici na šachovnici). Z paměťové tabulky určíme další akci a‘, která má maximální Q(s‘, a‘).
V počítačové hře získáváme body (odměny) sestřelením nepřítele. V šachové hře je odměna +1, když vyhrajeme, nebo -1, když prohrajeme. Je tedy dána pouze jedna odměna a chvíli trvá, než ji získáme.
Q-learning je o vytvoření šachového listu Q.

Můžeme vzít jeden tah a a zjistit, jakou odměnu R můžeme získat. Tím vytvoříme pohled o jeden krok dopředu. R + Q(s‘, a‘) se stane cílem, který chceme, aby byl Q(s, a). Řekněme například, že všechny hodnoty Q jsou nyní rovny jedné. Pokud posuneme joystick doprava a získáme 2 body, chceme posunout Q(s, a) blíže ke 3 (tj. 2 + 1).

Při dalším hraní udržujeme průběžný průměr pro Q. Hodnoty se budou zlepšovat a s určitými triky budou hodnoty Q konvergovat.
Algoritmus učení Q
Následující algoritmus je algoritmem pro přizpůsobení Q vzorkovaným odměnám. Pokud je γ (diskontní faktor) menší než jedna, je velká šance, že Q konverguje.

Pokud jsou však kombinace stavů a akcí příliš velké, paměť a výpočetní nároky pro Q budou příliš vysoké. Abychom to vyřešili, přejdeme na hlubokou síť Q (DQN), která aproximuje Q(s, a). Algoritmus učení se nazývá Deep Q-learning. S novým přístupem zobecníme aproximaci funkce Q-hodnoty místo toho, abychom si pamatovali řešení.
Jakým problémům čelí RL ve srovnání s DL?
Při učení pod dohledem chceme, aby vstupy byly i.i.d. (nezávisle a identicky rozdělené), tj.
- Vzorky jsou mezi dávkami náhodné, a proto má každá dávka stejné (nebo podobné) rozdělení dat.
- Vzorky v téže dávce jsou na sobě nezávislé.
Pokud tomu tak není, model může být pro některou třídu (nebo skupinu) vzorků v různém čase nadhodnocen a řešení nebude zobecněno.
Pro stejný vstup se navíc jeho označení v čase nemění. Tento druh stabilní podmínky pro vstup a výstup poskytuje podmínku pro to, aby učení pod dohledem fungovalo dobře.
Při učení s posilováním se vstup i cíl v průběhu procesu neustále mění a způsobují nestabilitu učení.
Cíl nestabilní: Vytváříme hlubokou síť, která se učí hodnoty Q, ale její cílové hodnoty se mění s tím, jak věci lépe poznáváme. Jak je uvedeno níže, cílové hodnoty pro Q závisí na samotném Q, honíme nestacionární cíl.

i.i.d.: Existuje další problém související s korelacemi uvnitř trajektorie. V rámci tréninkové iterace aktualizujeme parametry modelu, abychom posunuli Q(s, a) blíže k základní pravdě. Tyto aktualizace ovlivní další odhady. Když vytáhneme hodnoty Q v hluboké síti, hodnoty Q v okolních stavech se vytáhnou také jako síť.

Řekněme, že jsme právě získali odměnu a upravili síť Q tak, aby ji odrážela. Dále provedeme další tah. Nový stav bude vypadat podobně jako ten předchozí, zejména pokud k reprezentaci stavů použijeme surové obrázky. Nově získané Q(s‘, a‘) bude vyšší a náš nový cíl pro Q se také posune výše bez ohledu na zásluhy nové akce. Pokud síť aktualizujeme sekvencí akcí ve stejné trajektorii, zesílí se efekt nad rámec našeho záměru. To destabilizuje proces učení a zní to, jako když se psi honí za ocasem.
Jaký je základní problém při trénování RL? V RL jsme při vzorkování akcí často závislí na politice nebo hodnotových funkcích. To se však často mění, protože lépe víme, co zkoumat. Jak hrajeme hru, známe lépe základní pravdivé hodnoty stavů a akcí. Mění se tedy i naše cílové výstupy. Nyní se snažíme naučit mapování f pro neustále se měnící vstup a výstup!“
Naštěstí vstup i výstup mohou konvergovat. Pokud tedy dostatečně zpomalíme změny vstupu i výstupu, můžeme mít šanci modelovat f a zároveň mu umožnit vyvíjet se.
Řešení
Přehrávání zkušeností: Například vložíme poslední milion přechodů (nebo snímků videa) do vyrovnávací paměti a z této vyrovnávací paměti odebereme minidávku vzorků o velikosti 32 pro trénování hluboké sítě. Tím se vytvoří vstupní soubor dat, který je dostatečně stabilní pro trénování. Vzhledem k tomu, že náhodně vzorkujeme z vyrovnávací paměti pro přehrávání, jsou data navzájem nezávislejší a blíží se i.i.d.
Cílová síť: Vytvoříme dvě hluboké sítě θ- a θ. První z nich použijeme k získání hodnot Q, zatímco druhá zahrnuje všechny aktualizace při trénování. Po řekněme 100 000 aktualizacích synchronizujeme θ- s θ. Účelem je dočasně zafixovat cílové hodnoty Q, abychom nemuseli honit pohyblivý cíl. Navíc změny parametrů nemají okamžitý dopad na θ-, a proto ani vstup nemusí být 100% i.i.d., nebude nesprávně zvětšovat svůj vliv, jak bylo zmíněno dříve.

Při přehrávání zkušeností i cílové síti máme stabilnější vstup a výstup pro trénování sítě a chová se více jako trénování pod dohledem.
Přehrávání zkušeností má největší zlepšení výkonu v DQN. Zlepšení cílové sítě je významné, ale ne tak kritické jako u přehrávání. Nabývá však na významu, když je kapacita sítě malá.
Hluboké učení Q s přehráváním zkušeností
Tady je algoritmus:

kde ϕ předzpracovává poslední 4 snímky obrazu, které představují stav. Pro zachycení pohybu používáme čtyři snímky, které reprezentují stav.
Podrobnosti implementace
Funkce ztráty
Pro zlepšení výkonu projdeme ještě několik implementačních detailů. DQN používá Huberovu ztrátu (zelená křivka), kde je ztráta kvadratická pro malé hodnoty a a lineární pro velké hodnoty.


Zavedení Huberovy ztráty umožňuje méně dramatické změny, které často poškozují RL.
Optimalizace
Trénování RL je citlivé na optimalizační metody. Jednoduchý plán rychlosti učení není dostatečně dynamický, aby zvládl změny vstupů v průběhu trénování. Mnoho tréninků RL používá optimalizátor RMSProp nebo Adam. DQN se trénuje pomocí RMSProp. Použití metody předběžné optimalizace v metodách Policy Gradient je také intenzivně studováno.
ϵ-greedy
DQN používá ϵ-greedy pro výběr první akce.
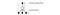
Pro zlepšení trénování začíná ϵ na hodnotě 1 a žíhá na hodnotu 0.1 nebo 0,05 během prvního milionu snímků pomocí následující politiky.

kde m je počet možných akcí. Na začátku trénování vybíráme možné akce rovnoměrně, ale s postupem trénování vybíráme optimální akci a* častěji. To umožňuje maximální prozkoumání na začátku, které nakonec přejde ve využívání.
Ale i během testování můžeme udržovat ϵ na malé hodnotě, například 0,05. Deterministická politika se může zaseknout v lokálním optimu. Nedeterministická politika nám umožňuje vymanit se kvůli možnosti dosáhnout lepšího optima.

Architektura
Tady je architektura DQN. Vezmeme poslední 4 předchozí snímky videa a vložíme je do konvolučních vrstev, po nichž následují plně propojené vrstvy pro výpočet hodnot Q pro každou akci.

V níže uvedeném příkladu, pokud nepohneme pádlem nahoru na snímku 3, míč mineme. Jak se dalo očekávat z DQN, hodnota Q při pohybu pádlem nahoru je ve srovnání s ostatními akcemi mnohem vyšší.


Vylepšení DQN
V DQN je provedeno mnoho vylepšení. V této části si ukážeme některé metody, které demonstrují významná vylepšení.
Dvojitá DQN
Při učení Q používáme pro cílovou hodnotu Q následující vzorec.

Operace max však vytváří pozitivní zkreslení směrem k odhadům hodnoty Q.

Z výše uvedeného příkladu vidíme, že max Q(s, a) je větší než konvergovaná hodnota 1.0. Tj. operace max nadhodnocuje hodnotu Q. Podle teorie a experimentů se výkonnost DQN zlepší, pokud použijeme online síť θ k chamtivému výběru akce a cílovou síť θ- k odhadu hodnoty Q. V případě, že se jedná o síť, která se používá k chamtivému výběru akce, je výkonnost DQN vyšší.

Prioritní přehrávání zkušeností
DQN vzorkuje přechody z vyrovnávací paměti rovnoměrně. Menší pozornost bychom však měli věnovat vzorkům, které se již blíží cíli. Měli bychom vzorkovat přechody, které mají velkou cílovou mezeru:

Můžeme tedy vybírat přechody z vyrovnávací paměti
- podle výše uvedené hodnoty chyby (častěji vybírat přechody s vyšší chybou), nebo
- je seřadit podle hodnoty chyby a vybírat je podle pořadí (častěji vybírat ten s vyšším pořadím).
Podrobnosti o rovnicích pro výběr dat naleznete v dokumentu Prioritized Experience Replay.
Soubojová DQN
V soubojové DQN se Q počítá podle jiného vzorce níže s hodnotovou funkcí V a stavově závislou funkcí akční výhody A níže:

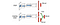
Místo učení Q používáme k výpočtu V a A dvě samostatné hlavy. Empirické experimenty ukazují, že dochází ke zlepšení výkonu. DQN aktualizuje funkci hodnoty Q stavu pouze pro konkrétní akci. Duální DQN aktualizuje V, což mohou využít i další aktualizace Q(s, a‘). Předpokládá se tedy, že každá iterace trénování Dueling DQN má větší dopad.
Hlučné sítě pro průzkum
DQN používá k výběru akcí ϵ-greedy. Alternativně ji nahrazuje NoisyNet přidáním parametrického šumu do lineární vrstvy, který napomáhá průzkumu. V NoisyNetu se ε-greedy nepoužívá. Používá chamtivou metodu výběru akcí z funkce Q-hodnoty. Ale pro plně propojené vrstvy aproximátoru Q přidáváme níže trénovatelný parametrizovaný šum k prozkoumání akcí. Přidání šumu do hluboké sítě je často ekvivalentní nebo lepší než přidání šumu k akci, jako je tomu u metody ϵ-greedy.

Další myšlenky
DQN patří do jedné důležité třídy RL, a to učení hodnot. V praxi při řešení reálných problémů často kombinujeme gradienty politiky s metodami učení hodnot
.
Leave a Reply