Big Data angewendet: Spark vs Flink

So wie der Begriff Künstliche Intelligenz (KI) seit vielen Jahren verachtet wird, beginnt im Jahr 2017 „Big Data“ etwas, das durch den täglichen Verschleiß mehr Ablehnung als Akzeptanz erzeugt. Alles ist Big Data und alles wird mit Big Data gelöst. Aber was machen dann diejenigen, die sich mit Big Data beschäftigen?
Big Data wurde in den letzten Jahren auf große Mengen strukturierter oder unstrukturierter Daten bezogen, die von Systemen oder Organisationen produziert werden. Ihre Bedeutung liegt nicht in den Daten selbst, sondern in dem, was wir mit diesen Daten tun können. Es geht darum, wie die Daten analysiert werden können, um bessere Entscheidungen zu treffen. Ein Großteil des Wertes, der aus Daten gewonnen werden kann, ergibt sich häufig aus unserer Fähigkeit, sie rechtzeitig zu verarbeiten. Daher ist es wichtig, sowohl die Datenquellen als auch den Rahmen, in dem sie verarbeitet werden sollen, sehr gut zu kennen.
Eines der ersten Ziele bei allen Big-Data-Projekten ist die Definition der Verarbeitungsarchitektur, die sich am besten an ein bestimmtes Problem anpasst. Dies beinhaltet eine Unzahl von Möglichkeiten und Alternativen:
- Welche Quellen gibt es?
- Wie werden die Daten gespeichert?
- Gibt es irgendwelche Rechenbeschränkungen?
- Welche Algorithmen sollten wir anwenden?
- Welche Genauigkeit sollten wir erreichen?
- Wie kritisch ist der Prozess?
Wir müssen unseren Bereich sehr gut kennen, um diese Fragen beantworten und qualitativ hochwertige Antworten geben zu können. In diesem Beitrag werden wir eine Vereinfachung eines realen Anwendungsfalls vorschlagen und zwei Big-Data-Verarbeitungstechnologien vergleichen.
Der vorgeschlagene Anwendungsfall ist die Anwendung der Kappa-Architektur für die Verarbeitung von Netflow-Spuren unter Verwendung verschiedener Verarbeitungs-Engines.
Netflow ist ein Netzwerkprotokoll zur Erfassung von Informationen über den IP-Verkehr. Es liefert uns Informationen wie das Start- und Enddatum von Verbindungen, Quell- und Ziel-IP-Adressen, Ports, Protokolle, Paketbytes usw. Es ist derzeit ein Standard für die Überwachung des Netzwerkverkehrs und wird von verschiedenen Hardware- und Softwareplattformen unterstützt.
Jedes in den Netflow-Traces enthaltene Ereignis liefert uns erweiterte Informationen über eine im überwachten Netzwerk aufgebaute Verbindung. Diese Ereignisse werden über Apache Kafka aufgenommen, um von der Verarbeitungs-Engine – in diesem Fall Apache Spark oder Apache Flink – analysiert zu werden, wobei eine einfache Operation wie die Berechnung des euklidischen Abstands zwischen Ereignispaaren durchgeführt wird. Diese Art von Berechnungen sind grundlegend für Algorithmen zur Erkennung von Anomalien.
Um diese Verarbeitung durchzuführen, müssen die Ereignisse jedoch gruppiert werden, beispielsweise durch temporäre Fenster, da die Daten in einem reinen Streaming-Kontext weder einen Anfang noch ein Ende haben.
Sobald die Netflow-Ereignisse gruppiert sind, führt die Berechnung der Abstände zwischen Paaren zu einer kombinatorischen Explosion. Wenn wir zum Beispiel 1000 Ereignisse / s von derselben IP erhalten und sie alle 5s gruppieren, erfordert jedes Fenster insgesamt 12.497.500 Berechnungen.
Die anzuwendende Strategie hängt vollständig von der Verarbeitungsmaschine ab. Im Falle von Spark ist die Gruppierung von Ereignissen einfach, da es nicht mit Streaming arbeitet, sondern stattdessen Micro-Batching verwendet, so dass das Verarbeitungsfenster immer definiert ist. Bei Flink hingegen ist dieser Parameter nicht zwingend erforderlich, da es sich um eine reine Streaming-Engine handelt, so dass das gewünschte Verarbeitungsfenster im Code definiert werden muss.
Die Berechnung liefert als Ergebnis einen neuen Datenstrom, der in einem anderen Kafka-Topic veröffentlicht wird, wie in der folgenden Abbildung dargestellt. Auf diese Weise wird eine große Flexibilität im Design erreicht, da diese Verarbeitung mit anderen in komplexeren Datenpipelines kombiniert werden kann.

Kappa-Architektur
Die Kappa-Architektur ist ein Software-Architekturmuster, das Datenströme oder „Streams“ verwendet, anstatt bereits gespeicherte und persistierte Daten zu nutzen. Die Datenquellen sind also unveränderlich und kontinuierlich, wie z.B. die Einträge in einem Protokoll. Diese Informationsquellen stehen im Gegensatz zu den traditionellen Datenbanken, die in Batch- oder Stapelanalysesystemen verwendet werden.
Diese „Ströme“ werden durch ein Verarbeitungssystem geschickt und in Hilfssystemen für die Dienstschicht gespeichert.
Die Kappa-Architektur ist eine Vereinfachung der Lambda-Architektur, von der sie sich in den folgenden Aspekten unterscheidet:
- Alles ist ein Stream (Batch ist ein Sonderfall)
- Datenquellen sind unveränderlich (Rohdaten bleiben bestehen)
- Es gibt einen einzigen analytischen Rahmen (vorteilhaft für die Wartung)
- Wiedergabefunktionalität, d.h. die erneute Verarbeitung aller bisher analysierten Daten (z.B. bei einem neuen Algorithmus)
Zusammenfassend lässt sich sagen, dass der Stapelverarbeitungsanteil entfällt, was ein System zur laufenden Datenverarbeitung begünstigt.
Machen wir uns die Hände schmutzig
Um all diese theoretischen Konzepte besser zu verstehen, gibt es nichts Besseres, als die Implementierung zu vertiefen. Eines der Elemente, die wir mit diesem Proof of Concept in die Praxis umsetzen wollen, ist die Möglichkeit, auf transparente Art und Weise zwischen verschiedenen Verarbeitungsmaschinen zu wechseln. Mit anderen Worten: Wie einfach ist der Wechsel zwischen Spark und Flink auf der Grundlage desselben Scala-Codes? Leider sind die Dinge nicht so einfach, obwohl es möglich ist, eine gemeinsame Teillösung zu erreichen, wie Sie in den folgenden Abschnitten sehen können.
Netflow-Ereignisse
Jedes Netflow-Ereignis liefert Informationen über eine bestimmte im Netzwerk hergestellte Verbindung. Diese Ereignisse sind im JSON-Format dargestellt und werden in Kafka aufgenommen. Der Einfachheit halber werden nur IPv4-Verbindungen verwendet.
Beispiel für ein Ereignis:
{
"eventid":995491697672682,
"dvc_version":"3.2",
"aproto":"failed",
"src_ip4":168099844,
"dst_ip4":4294967295,
"eventtime":1490024708,
"out_packets":1,
"type":"flow",
"dvc_time":1490024739,
"dst_ip":"255.255.255.255",
"src_ip":"10.5.0.4",
"duration":0,
"in_bytes":0,
"conn_state":"new",
"@version":"1",
"out_bytes":157,
"dvc_type":"suricata",
"in_packets":0,
"nproto":"UDP",
"src_port":42126,
"@timestamp":"2017-03-20T15:45:08.000Z",
"dst_port":40237,
"category":"informational"
}
Gemeinsamer Teil
Wie bereits erwähnt, besteht eines der Ziele dieses Artikels darin, verschiedene Big-Data-Verarbeitungsumgebungen transparent zu nutzen, d. h. dieselben Scala-Funktionen für Spark, Flink oder zukünftige Frameworks zu verwenden. Leider haben die Eigenheiten der einzelnen Frameworks dazu geführt, dass nur ein Teil des implementierten Scala-Codes für beide gemeinsam sein kann.
Der gemeinsame Code umfasst die Mechanismen zur Serialisierung und Deserialisierung von Netflow-Events. Wir greifen auf die json4s-Bibliothek von Scala zurück und definieren eine Case-Klasse mit den Feldern, die von Interesse sind:
case class Flow_ip4(eventid: String,
dst_ip4: String,
dst_port: String,
duration: String,
in_bytes: String,
in_packets: String,
out_bytes: String,
out_packets: String,
src_ip4: String,
src_port: String) extends Serializable
Außerdem wird das Flow-Objekt, das diese Serialisierung implementiert, so definiert, dass es bequem mit verschiedenen Big-Data-Engines arbeiten kann:
class Flow(trace: String) extends Serializable {implicit val formats =DefaultFormatsvar flow_case : Flow_ip4 = parse(trace).extractdef getFlow() : Flow_ip4 = flow_case}
Ein weiterer von beiden Frameworks gemeinsam genutzter Code sind die Funktionen zur Berechnung der euklidischen Distanz, zum Erhalt der Kombinationen einer Reihe von Objekten und zur Generierung der Json-Ergebnisse:
object utils { def euclideanDistance(xs: List, ys: List) = {
sqrt((xs zip ys).map { case (x,y)=> pow(y - x, 2) }.sum)
} def getCombinations(lists : Iterable) = {
lists.toList.combinations(2).map(x=> (x(0),x(1))).toList
} def getAllValuesFromString(flow_case : Flow_ip4) = flow_case.productIterator.drop(1)
.map(_.asInstanceOf.toDouble).toList def calculateDistances(input: Iterable): List = {
val combinations: List = getCombinations(input)
val distances = combinations.map{
case(f1,f2) => (f1.eventid,f2.eventid,euclideanDistance(getAllValuesFromString(f1),
getAllValuesFromString(f2)))}
distances.sortBy(_._3)
} def generateJson(x: (String, String, Double)): String = {
val obj = Map("eventid_1" -> x._1,
"eventid_2" -> x._2,
"distance" -> x._3,
"timestamp" -> System.currentTimeMillis())
val str_obj = scala.util.parsing.json.JSONObject(obj).toString()
str_obj
}
}
Spezifischer Teil jedes Frameworks
Die Anwendung von Transformationen und Aktionen ist der Bereich, in dem die Besonderheiten jedes Frameworks verhindern, dass es sich um einen generischen Code handelt.
Wie beobachtet, iteriert Flink jedes Ereignis, filtert, serialisiert, gruppiert nach IP und Zeit und wendet schließlich eine Abstandsberechnung an, um es über einen Producer an Kafka zu senden.
In Spark hingegen müssen wir, da die Ereignisse bereits nach Zeit gruppiert sind, nur noch filtern, serialisieren und nach IP gruppieren. Sobald dies geschehen ist, werden die Entfernungsberechnungsfunktionen angewendet und das Ergebnis kann mit den entsprechenden Bibliotheken an Kafka gesendet werden.
Für Flink:
val flow = stream
.filter(!_.contains("src_ip6"))
.map(trace =>{
new Flow(trace).getFlow()
})
.keyBy(_.src_ip4)
.timeWindow(Time.seconds(3))
.apply{(
key: String,
window: TimeWindow,
input: Iterable,
out: Collector]) => {
val distances: List = utils.calculateDistances(input)
out.collect(distances)
}
}
.flatMap(x => x)
flow.map( x=>{
val str_obj: String = utils.generateJson(x)
producer.send(new ProducerRecord(topic_out, str_obj))
})
Für Spark:
val flow = stream.map(_.value())
.filter(!_.contains("src_ip6"))
.map(record => {
implicit val formats = DefaultFormats
val flow = new Flow(record).getFlow()
(flow.src_ip4,flow)
})
.groupByKey()flow.foreachRDD(rdd => {
rdd.foreach{ case (key, input ) => {
val distances = utils.calculateDistances(input)
distances.map(x => {val str_obj: String = utils.generateJson(x)
producer.send(new ProducerRecord(topic_out, str_obj))
})
}}
})
Die IDs der einzelnen Ereignisse, ihre Ingestion-Zeitstempel, das Ergebnis der Entfernungsberechnung und die Zeit, zu der die Berechnung abgeschlossen wurde, werden im Kafka-Ausgabethema gespeichert. Hier ein Beispiel für eine Ablaufverfolgung:
{
"eventid_1":151852746453199,
"ts_flow1":1495466510792,
"eventid_2":1039884491535740,
"ts_flow2":1495466511125,
"distance":12322.94295207115,
"ts_output":1495466520212
}
Ergebnisse
Wir haben zwei verschiedene Arten von Tests durchgeführt: mehrere Ereignisse in einem einzigen Fenster und mehrere Ereignisse in verschiedenen Fenstern, wobei ein Phänomen den kombinatorischen Algorithmus scheinbar stochastisch macht und unterschiedliche Ergebnisse liefert. Dies liegt daran, dass die Daten ungeordnet aufgenommen werden, sobald sie im System ankommen, ohne die Ereigniszeit zu berücksichtigen, und dass auf dieser Grundlage Gruppierungen vorgenommen werden, die zu unterschiedlichen Kombinationen führen.
Die folgende Präsentation von Apache Beam erläutert den Unterschied zwischen Verarbeitungszeit und Ereigniszeit genauer: https://goo.gl/h5D1yR

Mehrere Ereignisse im selben Fenster
Im selben Fenster werden etwa 10.000 Ereignisse aufgenommen, die bei Anwendung der Kombinationen für dieselben IPs fast 2 Millionen Berechnungen erfordern. Die Gesamtberechnungszeit in jedem Rahmen (d. h. die Differenz zwischen dem höchsten und dem niedrigsten Ausgabezeitstempel) mit 8 Rechenkernen beträgt:
- Spark-Gesamtzeit: 41,50s
- Gesamtzeit Flink: 40,24s
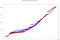
Mehrere Zeilen gleicher Farbe sind auf Parallelität zurückzuführen, da es Berechnungen gibt, die zur gleichen Zeit enden.
Mehrere Ereignisse in verschiedenen Fenstern
Mehr als 50.000 Ereignisse werden entlang verschiedener Zeitfenster von 3s eingefügt. Hier werden die Besonderheiten der einzelnen Maschinen deutlich. Wenn wir denselben Graphen der Verarbeitungszeiten aufzeichnen, ergibt sich folgendes Bild:
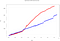
- Gesamtzeit Park: 614.1s
- Gesamtzeit Flink: 869.3s
Wir beobachten einen Anstieg der Verarbeitungszeit für Flink. Dies ist auf die Art und Weise zurückzuführen, wie Ereignisse aufgenommen werden:

Wie in der letzten Abbildung zu sehen ist, verwendet Flink keine Mikrobatches und parallelisiert die Ereignisfenster (im Gegensatz zu Spark verwendet es überlappende Schiebefenster). Dies führt zu einer längeren Berechnungszeit, aber zu einer kürzeren Ingestion-Zeit. Dies ist eine der Besonderheiten, die wir bei der Definition unserer Streaming-Big-Data-Verarbeitungsarchitektur berücksichtigen müssen.
Und was ist mit der Berechnung?
Der euklidische Abstand von 10.000 Ereignissen hat folgende Verteilung:

Es wird angenommen, dass anomale Ereignisse im „langen Schwanz“ des Histogramms liegen. Aber macht das wirklich Sinn? Lassen Sie uns das analysieren.
In diesem Fall werden bestimmte kategorische Parameter (IP, Port) bei der Berechnung als numerisch betrachtet. Wir haben uns dafür entschieden, um die Dimensionalität zu erhöhen und einem echten Problem näher zu kommen. Wenn wir jedoch alle realen Werte der Entfernungen anzeigen, erhalten wir folgendes Ergebnis:

Das bedeutet Rauschen, da diese Werte (IP, Port, Quelle und Ziel) die Berechnung verzerren. Wenn wir jedoch diese Felder eliminieren und alles neu verarbeiten, behalten wir:
- Dauer
- in_bytes
- in_packets
- out_bytes
- out_packets
Wir erhalten die folgende Verteilung:

Der lange Schwanz ist nicht mehr so bevölkert und es gibt eine Spitze am Ende. Wenn wir die Werte der Abstandsberechnung anzeigen, können wir sehen, wo die anomalen Werte liegen.

Dank dieser einfachen Verfeinerung erleichtern wir die Arbeit des Analysten, indem wir ihm/ihr ein leistungsfähiges Werkzeug an die Hand geben, das Zeit spart und aufzeigt, wo die Probleme eines Netzwerks zu finden sind.
Schlussfolgerungen
Obwohl unendlich viele Möglichkeiten und Schlussfolgerungen erörtert werden könnten, ist die bemerkenswerteste Erkenntnis, die in dieser kleinen Entwicklung gewonnen wurde:
- Verarbeitungsrahmen. Es ist nicht trivial, von einem Framework auf ein anderes umzusteigen, daher ist es wichtig, von Anfang an zu entscheiden, welches Framework verwendet werden soll, und dessen Besonderheiten sehr gut zu kennen. Wenn wir zum Beispiel ein Ereignis sofort verarbeiten müssen und dies für das Unternehmen von entscheidender Bedeutung ist, müssen wir eine Verarbeitungs-Engine auswählen, die diese Anforderung erfüllt.
- Big Picture. Bei bestimmten Funktionen ist eine Engine besser als andere, aber was sind Sie bereit zu opfern, um diese oder jene Funktion zu erhalten?
- Nutzung von Ressourcen. Speicherverwaltung, CPU, Festplatte … Es ist wichtig, Stresstests, Benchmarks usw. auf das System anzuwenden, um zu wissen, wie es sich als Ganzes verhält, und um mögliche Schwachstellen und Engpässe zu ermitteln
- Merkmale und Kontext. Es ist wichtig, immer den spezifischen Kontext zu berücksichtigen und zu wissen, welche Merkmale in das System eingebracht werden sollen. Wir haben Parameter wie Ports oder IPs bei der Berechnung von Entfernungen verwendet, um zu versuchen, Anomalien in einem Netz zu erkennen. Diese Merkmale haben, obwohl sie numerisch sind, keinen räumlichen Bezug zueinander. Es gibt jedoch Möglichkeiten, diese Art von Daten zu nutzen, aber das lassen wir für einen zukünftigen Beitrag stehen.
Dieser Beitrag wurde ursprünglich veröffentlicht unter https://www.gradiant.org/noticia/big-data-aplicado-spark-vs-flink/
Dank an Adrián Portabales ( adrianp )
Leave a Reply