Datamaskning
Vad är datamaskning?
Datamaskning är ett sätt att skapa en falsk, men realistisk version av dina organisationsdata. Målet är att skydda känsliga data och samtidigt tillhandahålla ett funktionellt alternativ när riktiga data inte behövs – till exempel vid användarutbildning, säljdemonstrationer eller programvarutestning.
Processer för datamaskering ändrar datavärden samtidigt som samma format används. Målet är att skapa en version som inte kan dechiffreras eller omvändas. Det finns flera sätt att ändra data, bland annat genom att blanda tecken, byta ut ord eller tecken och kryptera.
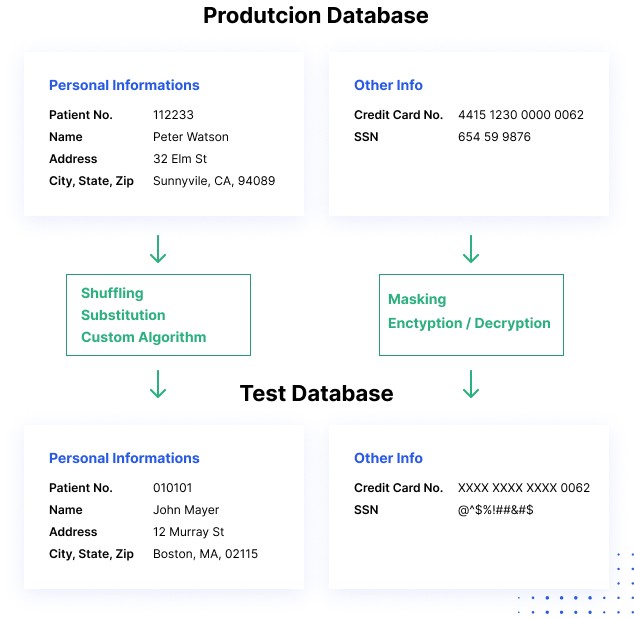
Hur datamaskning fungerar
Varför är datamaskning viktigt?
Det finns flera anledningar till att datamaskering är viktigt för många organisationer:
- Datamaskering löser flera kritiska hot – dataförlust, dataexfiltrering, insiderhot eller kontokompromiss och osäkra gränssnitt mot system från tredje part.
- Reducerar datarisker i samband med införande av moln.
- Gör data värdelösa för en angripare, samtidigt som många av dess inneboende funktionella egenskaper bibehålls.
- Gör det möjligt att dela data med auktoriserade användare, t.ex. testare och utvecklare, utan att exponera produktionsdata.
- Kan användas för datasanering – normal radering av filer lämnar fortfarande spår av data i lagringsmedier, medan sanering ersätter de gamla värdena med maskerade värden.
Datamaskningstyper
Det finns flera typer av datamaskningstyper som vanligen används för att säkra känsliga data.
Statisk datamaskning
Statiska datamaskningsprocesser kan hjälpa dig att skapa en sanerad kopia av databasen. Processen ändrar alla känsliga data tills en kopia av databasen kan delas på ett säkert sätt. Vanligtvis innebär processen att man skapar en säkerhetskopia av en databas i produktion, laddar den till en separat miljö, eliminerar alla onödiga data och maskerar sedan data medan den är i stasis. Den maskerade kopian kan sedan skjutas till målplatsen.
Deterministisk datamaskning
Involverar mappning av två uppsättningar data som har samma typ av data, på ett sådant sätt att ett värde alltid ersätts med ett annat värde. Exempelvis ersätts namnet ”John Smith” alltid med ”Jim Jameson”, överallt där det förekommer i en databas. Denna metod är praktisk för många scenarier men är till sin natur mindre säker.
Maskering av data i farten
Maskering av data medan de överförs från produktionssystem till test- eller utvecklingssystem innan data sparas på disk. Organisationer som distribuerar programvara ofta kan inte skapa en säkerhetskopia av källdatabasen och tillämpa maskering – de behöver ett sätt att kontinuerligt strömma data från produktion till flera testmiljöer.
Maskering i farten skickar mindre delmängder av maskerade data när det behövs. Varje delmängd maskerad data lagras i dev/testmiljön för att användas av det icke-produktionsbaserade systemet.
Det är viktigt att tillämpa on-the-fly maskering på alla flöden från ett produktionssystem till en utvecklingsmiljö, i början av ett utvecklingsprojekt, för att förhindra efterlevnads- och säkerhetsproblem.
Dynamisk datamaskning
Liknande som on-the-fly maskering, men data lagras aldrig i ett sekundärt datalager i dev/testmiljön. Snarare strömmar den direkt från produktionssystemet och konsumeras av ett annat system i dev/test-miljön.
Tekniker för datamaskning
Låt oss gå igenom några vanliga sätt som organisationer tillämpar maskning på känsliga data. När IT-personal skyddar data kan de använda en mängd olika tekniker.
Datakryptering
När data krypteras blir de värdelösa om inte betraktaren har dekrypteringsnyckeln. I huvudsak maskeras data av krypteringsalgoritmen. Detta är den säkraste formen av datamaskning, men den är också komplex att genomföra eftersom den kräver en teknik för att utföra löpande datakryptering och mekanismer för att hantera och dela krypteringsnycklar
Data Scrambling
Tecknen omorganiseras i slumpmässig ordning och ersätter det ursprungliga innehållet. Exempelvis kan ett ID-nummer som 76498 i en produktionsdatabas ersättas med 84967 i en testdatabas. Denna metod är mycket enkel att genomföra, men kan endast tillämpas på vissa typer av data och är mindre säker.
Nulling Out
Data verkar saknas eller vara ”noll” när de visas av en obehörig användare. Detta gör uppgifterna mindre användbara för utvecklings- och teständamål.
Värdevarians
Originella datavärden ersätts med en funktion, t.ex. skillnaden mellan det lägsta och högsta värdet i en serie. Om en kund till exempel har köpt flera produkter kan inköpspriset ersättas med ett intervall mellan det högsta och lägsta betalda priset. Detta kan ge användbara data för många ändamål, utan att den ursprungliga datamängden avslöjas.
Datasubstitution
Datavärden ersätts med falska, men realistiska, alternativa värden. Till exempel ersätts riktiga kundnamn med ett slumpmässigt urval av namn från en telefonbok.
Data Shuffling
Samma sak som substitution, förutom att datavärden byts ut inom samma dataset. Uppgifterna omorganiseras i varje kolumn med hjälp av en slumpmässig sekvens; t.ex. byte mellan riktiga kundnamn i flera kundregister. Utdatamängden ser ut som riktiga data, men visar inte den verkliga informationen för varje individ eller datapost.
Pseudonymisering
Enligt EU:s allmänna dataskyddsförordning (GDPR) har en ny term införts för att täcka processer som datamaskning, kryptering och hashning för att skydda personuppgifter: pseudonymisering.
Pseudonymisering, enligt definitionen i GDPR, är en metod som säkerställer att data inte kan användas för personlig identifiering. Det kräver att man tar bort direkta identifierare, och helst undviker flera identifierare som, när de kombineras, kan identifiera en person.
Det krävs dessutom att krypteringsnycklar, eller andra uppgifter som kan användas för att återgå till de ursprungliga datavärdena, lagras separat och säkert.
Bästa metoder för datamaskning
Detektera projektets omfattning
För att effektivt kunna utföra datamaskning bör företagen veta vilken information som behöver skyddas, vem som är behörig att se den, vilka program som använder informationen och var den finns, både i produktions- och icke-produktionsdomäner. Även om detta kan verka enkelt på pappret, kan denna process på grund av verksamhetens komplexitet och flera affärsområden kräva en betydande insats och måste planeras som ett separat steg i projektet.
Säkerställa referentiell integritet
Referentiell integritet innebär att varje ”typ” av information som kommer från en affärsapplikation måste maskeras med hjälp av samma algoritm.
I stora organisationer är det inte genomförbart att ha ett enda verktyg för datamaskning som används i hela företaget. Varje verksamhetsgren kan vara tvungen att implementera sin egen datamaskning på grund av budget/affärskrav, olika metoder för IT-administration eller olika krav på säkerhet/reglering.
Säkerställ att olika verktyg och metoder för datamaskning i hela organisationen är synkroniserade när de hanterar samma typ av data. Detta kommer att förhindra utmaningar senare när data måste användas på flera affärsområden.
Säkra datamaskningsalgoritmerna
Det är viktigt att tänka på hur man skyddar algoritmerna för dataframställning, liksom alternativa datamängder eller ordböcker som används för att förvränga data. Eftersom endast auktoriserade användare bör ha tillgång till de verkliga uppgifterna bör dessa algoritmer betraktas som extremt känsliga. Om någon får reda på vilka upprepningsbara maskeringsalgoritmer som används kan den personen omvända stora block av känslig information.
En bästa praxis för datamaskning, som uttryckligen krävs i vissa förordningar, är att säkerställa åtskillnad av arbetsuppgifter. Till exempel bestämmer IT-säkerhetspersonalen vilka metoder och algoritmer som ska användas i allmänhet, men specifika algoritminställningar och datalistor bör endast vara tillgängliga för dataägarna på den berörda avdelningen.
Datamaskning med Imperva
Imperva är en säkerhetslösning som tillhandahåller datamasknings- och krypteringsfunktioner, så att du kan fördunkla känsliga data så att de blir värdelösa för en angripare, även om de på något sätt extraheras.
Inom att tillhandahålla datamaskning skyddar Impervas datasäkerhetslösning dina data oavsett var de befinner sig – i lokalerna, i molnet och i hybridmiljöer. Den ger också säkerhets- och IT-team full insyn i hur data nås, används och flyttas runt i organisationen.
Vår heltäckande strategi bygger på flera skyddslager, inklusive:
- Databasbrandvägg – blockerar SQL-injektion och andra hot, samtidigt som den utvärderar för kända sårbarheter.
- Hantering av användarrättigheter – övervakar dataåtkomst och aktiviteter för privilegierade användare för att identifiera överdrivna, olämpliga och oanvända privilegier.
- Förebyggande av dataförluster (DLP) – inspekterar data i rörelse, i vila på servrar, i molnlagring eller på slutpunktsenheter.
- Analyser av användarbeteende – upprättar baslinjer för dataåtkomstbeteende, använder maskininlärning för att upptäcka och varna för onormal och potentiellt riskfylld aktivitet.
- Upptäckt och klassificering av data – avslöjar var, volymen och sammanhanget för data på plats och i molnet.
- Övervakning av databasaktivitet – övervakar relationsdatabaser, datalager, stora datamängder och stordatorer för att generera varningar i realtid om policyöverträdelser.
- Prioritering av varningar – Imperva använder AI- och maskininlärningsteknik för att se över strömmen av säkerhetshändelser och prioritera de som är viktigast.
Leave a Reply