Mascarea datelor
Ce este mascarea datelor?
Mascarea datelor este o modalitate de a crea o versiune falsă, dar realistă a datelor organizaționale. Scopul este de a proteja datele sensibile, oferind în același timp o alternativă funcțională atunci când datele reale nu sunt necesare – de exemplu, în instruirea utilizatorilor, demonstrațiile de vânzări sau testarea software-ului.
Procesele de mascare a datelor modifică valorile datelor, folosind în același timp același format. Scopul este de a crea o versiune care nu poate fi descifrată sau supusă ingineriei inverse. Există mai multe moduri de a modifica datele, inclusiv amestecarea caracterelor, înlocuirea cuvintelor sau a caracterelor și criptarea.
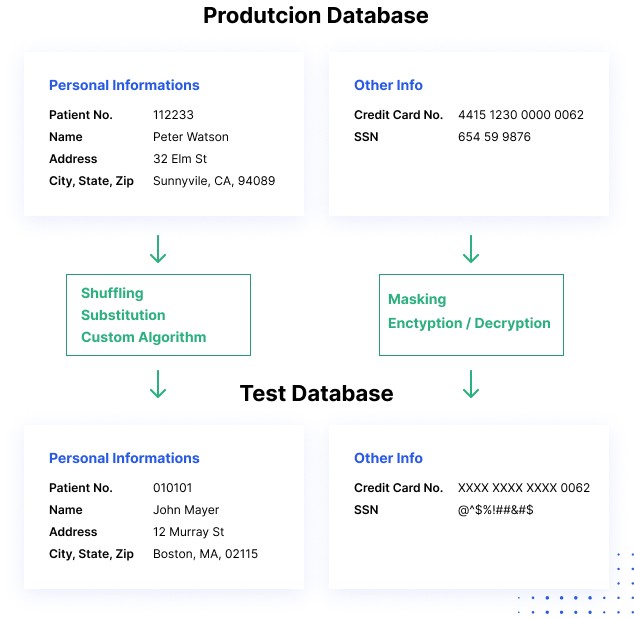
Cum funcționează mascarea datelor
De ce este importantă mascarea datelor?
Iată câteva motive pentru care mascarea datelor este esențială pentru multe organizații:
- Mascarea datelor rezolvă mai multe amenințări critice – pierderea de date, exfiltrarea datelor, amenințări din interior sau compromiterea conturilor și interfețe nesigure cu sisteme terțe.
- Reduce riscurile de date asociate cu adoptarea cloud.
- Face datele inutile pentru un atacator, păstrând în același timp multe dintre proprietățile funcționale inerente ale acestora.
- Permite partajarea datelor cu utilizatorii autorizați, cum ar fi testerii și dezvoltatorii, fără a expune datele de producție.
- Poate fi utilizat pentru asanarea datelor – ștergerea normală a fișierelor lasă încă urme de date în mediile de stocare, în timp ce asanarea înlocuiește vechile valori cu unele mascate.
Tipuri de mascare a datelor
Există mai multe tipuri de mascare a datelor utilizate în mod obișnuit pentru a securiza datele sensibile.
Mascare statică a datelor
Procesele de mascare statică a datelor vă pot ajuta să creați o copie igienizată a bazei de date. Procesul modifică toate datele sensibile până când o copie a bazei de date poate fi partajată în siguranță. De obicei, procesul implică crearea unei copii de rezervă a unei baze de date în producție, încărcarea acesteia într-un mediu separat, eliminarea tuturor datelor inutile și apoi mascarea datelor în timp ce se află în stază. Copia mascată poate fi apoi împinsă în locația țintă.
Mascarea deterministă a datelor
Implică cartografierea a două seturi de date care au același tip de date, în așa fel încât o valoare să fie întotdeauna înlocuită cu o altă valoare. De exemplu, numele „John Smith” este întotdeauna înlocuit cu „Jim Jameson”, oriunde apare într-o bază de date. Această metodă este convenabilă pentru multe scenarii, dar este în mod inerent mai puțin sigură.
Mascarea datelor din mers
Mascarea datelor în timp ce acestea sunt transferate de la sistemele de producție la sistemele de testare sau de dezvoltare, înainte ca datele să fie salvate pe disc. Organizațiile care implementează frecvent software nu pot crea o copie de rezervă a bazei de date sursă și să aplice mascarea – ele au nevoie de o modalitate de a transmite în mod continuu datele din producție către mai multe medii de testare.
În zbor, mascarea trimite subseturi mai mici de date mascate atunci când este necesar. Fiecare subansamblu de date mascate este stocat în mediul dev/test pentru a fi utilizat de către sistemul care nu este de producție.
Este important să se aplice mascarea din mers la orice flux de la un sistem de producție la un mediu de dezvoltare, chiar la începutul unui proiect de dezvoltare, pentru a preveni problemele de conformitate și de securitate.
Mascarea dinamică a datelor
Similar cu mascarea din mers, dar datele nu sunt niciodată stocate într-un depozit secundar de date în mediul dev/test. Mai degrabă, acestea sunt transmise direct din sistemul de producție și consumate de un alt sistem din mediul dev/test.
Tehnici de mascare a datelor
Să trecem în revistă câteva moduri obișnuite în care organizațiile aplică mascarea datelor sensibile. Atunci când protejează datele, profesioniștii IT pot utiliza o varietate de tehnici.
Criptarea datelor
Când datele sunt criptate, acestea devin inutile dacă cel care le vizualizează nu are cheia de decriptare. În esență, datele sunt mascate de algoritmul de criptare. Aceasta este cea mai sigură formă de mascare a datelor, dar este, de asemenea, complexă de implementat, deoarece necesită o tehnologie pentru a efectua o criptare continuă a datelor și mecanisme de gestionare și partajare a cheilor de criptare
Data Scrambling
Caracterele sunt reorganizate în ordine aleatorie, înlocuind conținutul original. De exemplu, un număr de identificare, cum ar fi 76498 într-o bază de date de producție, ar putea fi înlocuit cu 84967 într-o bază de date de testare. Această metodă este foarte simplu de implementat, dar poate fi aplicată numai la anumite tipuri de date și este mai puțin sigură.
Nulling Out
Datele apar lipsă sau „nule” atunci când sunt vizualizate de un utilizator neautorizat. Acest lucru face ca datele să fie mai puțin utile în scopuri de dezvoltare și testare.
Value Variance
Valorile inițiale ale datelor sunt înlocuite de o funcție, cum ar fi diferența dintre cea mai mică și cea mai mare valoare dintr-o serie. De exemplu, dacă un client a cumpărat mai multe produse, prețul de achiziție poate fi înlocuit cu un interval între cel mai mare și cel mai mic preț plătit. Acest lucru poate furniza date utile în multe scopuri, fără a dezvălui setul de date original.
Substituire de date
Valorile datelor sunt înlocuite cu valori alternative false, dar realiste. De exemplu, numele reale ale clienților sunt înlocuite cu o selecție aleatorie de nume dintr-o agendă telefonică.
Data Shuffling
Similar cu substituția, cu excepția faptului că valorile datelor sunt schimbate în cadrul aceluiași set de date. Datele sunt rearanjate în fiecare coloană folosind o secvență aleatorie; de exemplu, comutarea între numele reale ale clienților din mai multe înregistrări de clienți. Setul de ieșire arată ca datele reale, dar nu prezintă informațiile reale pentru fiecare individ sau înregistrare de date.
Pseudonimizarea
Conform Regulamentului general privind protecția datelor (GDPR) al UE, a fost introdus un nou termen pentru a acoperi procese precum mascarea datelor, criptarea și hashing-ul pentru a proteja datele cu caracter personal: pseudonimizarea.
Pseudonimizarea, așa cum este definită în GDPR, este orice metodă care asigură că datele nu pot fi utilizate pentru identificarea personală. Aceasta presupune eliminarea identificatorilor direcți și, de preferință, evitarea identificatorilor multipli care, atunci când sunt combinați, pot identifica o persoană.
În plus, cheile de criptare sau alte date care pot fi utilizate pentru a reveni la valorile originale ale datelor ar trebui să fie stocate separat și în siguranță.
Cele mai bune practici de mascare a datelor
Determinați domeniul de aplicare al proiectului
Pentru a realiza în mod eficient mascarea datelor, companiile ar trebui să știe ce informații trebuie protejate, cine este autorizat să le vadă, ce aplicații utilizează datele și unde se află acestea, atât în domeniul de producție, cât și în cel de non-producție. Deși acest lucru poate părea ușor pe hârtie, din cauza complexității operațiunilor și a multiplelor linii de afaceri, acest proces poate necesita un efort substanțial și trebuie planificat ca o etapă separată a proiectului.
Asigurarea integrității referențiale
Integritatea referențială înseamnă că fiecare „tip” de informație care provine dintr-o aplicație de afaceri trebuie să fie mascat folosind același algoritm.
În organizațiile mari, un singur instrument de mascare a datelor utilizat în întreaga întreprindere nu este fezabil. Fiecare linie de afaceri poate fi nevoită să implementeze propria mascare a datelor din cauza cerințelor bugetare/de afaceri, a practicilor diferite de administrare IT sau a cerințelor diferite de securitate/reglementare.
Asigurați-vă că diferitele instrumente și practici de mascare a datelor din întreaga organizație sunt sincronizate, atunci când tratează același tip de date. Acest lucru va preveni provocările ulterioare, atunci când datele trebuie să fie utilizate între liniile de afaceri.
Securizați algoritmii de mascare a datelor
Este esențial să luați în considerare modul în care să protejați algoritmii de realizare a datelor, precum și seturile de date alternative sau dicționarele utilizate pentru a bruia datele. Deoarece numai utilizatorii autorizați ar trebui să aibă acces la datele reale, acești algoritmi ar trebui să fie considerați extrem de sensibili. Dacă cineva află ce algoritmi de mascare repetabilă sunt utilizați, poate face inginerie inversă pentru blocuri mari de informații sensibile.
O bună practică de mascare a datelor, care este cerută în mod explicit de unele reglementări, este de a asigura separarea sarcinilor. De exemplu, personalul de securitate IT stabilește ce metode și algoritmi vor fi utilizați în general, dar setările specifice ale algoritmilor și listele de date ar trebui să fie accesibile numai proprietarilor de date din departamentul respectiv.
Mascarea datelor cu Imperva
Imperva este o soluție de securitate care oferă capacități de mascare și criptare a datelor, permițându-vă să ofuscați datele sensibile astfel încât acestea să fie inutile pentru un atacator, chiar dacă ar fi extrase cumva.
Pe lângă faptul că oferă mascarea datelor, soluția de securitate a datelor de la Imperva vă protejează datele oriunde s-ar afla – în spații proprii, în cloud și în medii hibride. De asemenea, oferă echipelor de securitate și IT o vizibilitate completă asupra modului în care datele sunt accesate, utilizate și mutate în cadrul organizației.
Abordarea noastră cuprinzătoare se bazează pe mai multe niveluri de protecție, inclusiv:
- Firewall pentru baze de date – blochează injecțiile SQL și alte amenințări, evaluând în același timp vulnerabilitățile cunoscute.
- Gestionarea drepturilor utilizatorilor-monitorizează accesul la date și activitățile utilizatorilor privilegiați pentru a identifica privilegiile excesive, necorespunzătoare și nefolosite.
- Prevenirea pierderilor de date (DLP)-inspectează datele în mișcare, în repaus pe servere, în stocarea în cloud sau pe dispozitivele endpoint.
- Analiză a comportamentului utilizatorului – stabilește linii de bază ale comportamentului de accesare a datelor, utilizează învățarea automată pentru a detecta și alerta cu privire la activități anormale și potențial riscante.
- Descoperirea și clasificarea datelor – dezvăluie locația, volumul și contextul datelor la fața locului și în cloud.
- Monitorizarea activității bazelor de date-monitorizează bazele de date relaționale, depozitele de date, big data și mainframe-urile pentru a genera alerte în timp real cu privire la încălcările politicilor.
- Stabilirea priorităților de alertă-Imperva folosește AI și tehnologia de învățare automată pentru a analiza întregul flux de evenimente de securitate și a le prioritiza pe cele care contează cel mai mult.
Leave a Reply