Grid Search for model tuning
Un hiperparametru de model este o caracteristică a unui model care este externă modelului și a cărei valoare nu poate fi estimată din date. Valoarea hiperparametrului trebuie să fie stabilită înainte de începerea procesului de învățare. De exemplu, c în Support Vector Machines, k în k-Nearest Neighbors, numărul de straturi ascunse în rețelele neuronale.
În schimb, un parametru este o caracteristică internă a modelului și valoarea sa poate fi estimată din date. Exemplu, coeficienții beta ai regresiei liniare/logistice sau vectori de suport în Mașinile cu vectori de suport.
Grid-search este utilizat pentru a găsi hiperparametrii optimi ai unui model care duce la cele mai „precise” predicții.
Să analizăm Grid-Search prin construirea unui model de clasificare pe setul de date privind cancerul de sân.
Importați setul de date și vizualizați primele 10 rânduri.
Succes :

Care rând din setul de date are una dintre cele două clase posibile: benign (reprezentat prin 2) și malign (reprezentat prin 4). De asemenea, există 10 atribute în acest set de date (prezentat mai sus) care vor fi utilizate pentru predicție, cu excepția numărului de cod al probei, care este numărul de identificare.
Curățați datele și redenumiți valorile clasei ca fiind 0/1 pentru construirea modelului (unde 1 reprezintă un caz malign). De asemenea, haideți să observăm distribuția clasei.
Output :

Există 444 cazuri benigne și 239 cazuri maligne.
Succes :
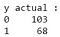
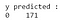
Din rezultatul obținut, putem observa că există 68 de cazuri maligne și 103 cazuri benigne în setul de date de testare. Cu toate acestea, clasificatorul nostru prezice toate cazurile ca fiind benigne (deoarece este clasa majoritară).
Calculați metricile de evaluare ale acestui model.
Succes :
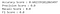

Precizia modelului este de 60.2%, dar acesta este un caz în care acuratețea poate să nu fie cea mai bună măsură pentru a evalua modelul. Așadar, să ne uităm la ceilalți parametri de evaluare.

Figura de mai sus este matricea de confuzie, cu etichete și culori adăugate pentru o mai bună intuiție (Codul pentru a o genera poate fi găsit aici). Pentru a rezuma matricea de confuzie : ADEVĂRAȚI POZITIVI (TP)= 0,ADEVĂRAȚI NEGATIVI (TN)= 103,FALȘI POZITIVI (FP)= 0, FALȘI NEGATIVI (FN)= 68. Formulele pentru metricile de evaluare sunt următoarele :

Din moment ce modelul nu clasifică corect niciun caz malign, metricile recall și precision sunt 0.
Acum că avem precizia de bază, să construim un model de regresie logistică cu parametri impliciți și să evaluăm modelul.
Output :

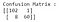
Prin ajustarea modelului de regresie logistică cu parametrii impliciți, avem un model mult mai „bun”. Acuratețea este de 94,7% și, în același timp, precizia este de un uimitor 98,3%. Acum, să ne uităm din nou la matricea de confuzie pentru rezultatele acestui model din nou :

Urmărind instanțele clasificate greșit, putem observa că 8 cazuri maligne au fost clasificate incorect ca fiind benigne (false negative). De asemenea, doar un singur caz benign a fost clasificat ca fiind malign (fals pozitiv).
Un fals negativ este mai grav, deoarece o boală a fost ignorată, ceea ce poate duce la decesul pacientului. În același timp, un fals pozitiv ar duce la un tratament inutil – generând costuri suplimentare.
Să încercăm să minimizăm falsurile negative folosind Grid Search pentru a găsi parametrii optimi. Grid search poate fi folosit pentru a îmbunătăți orice metrică de evaluare specifică.
Metrica pe care trebuie să ne concentrăm pentru a reduce falsurile negative este Recall.
Grid Search pentru a maximiza Recall
Output :


Hiperparametrii pe care i-am reglat sunt: :
- Penalizare: l1 sau l2 care specia norma utilizată în penalizare.
- C: Inversa puterii de regularizare – valori mai mici ale lui C specifică o regularizare mai puternică.
De asemenea, în funcția Grid-search, avem parametrul scoring unde putem specifica metrica pe care să evaluăm modelul (Noi am ales recall ca metrică). Din matricea de confuzie de mai jos, putem observa că numărul de falsuri negative s-a redus, însă cu prețul creșterii numărului de falsuri pozitive. Rechemare după căutarea în grilă a sărit de la 88,2 % la 91,1 %, în timp ce precizia a scăzut la 87,3 % de la 98,3 %.

Puteți regla în continuare modelul pentru a obține un echilibru între precizie și rechemare utilizând scorul „f1” ca metrică de evaluare. Consultați acest articol pentru o mai bună înțelegere a metricilor de evaluare.
Cercetarea în grilă construiește un model pentru fiecare combinație de hiperparametri specificată și evaluează fiecare model. O tehnică mai eficientă pentru reglarea hiperparametrilor este căutarea randomizată – în care se utilizează combinații aleatorii de hiperparametri pentru a găsi cea mai bună soluție.
.
Leave a Reply