Pesquisa Grid para afinação do modelo
Um hiperparâmetro do modelo é uma característica de um modelo que é externo ao modelo e cujo valor não pode ser estimado a partir dos dados. O valor do hiperparâmetro tem de ser definido antes de se iniciar o processo de aprendizagem. Por exemplo, c em Support Vector Machines, k em k-Nearest Neighbors, o número de camadas ocultas em Redes Neurais.
Em contraste, um parâmetro é uma característica interna do modelo e seu valor pode ser estimado a partir dos dados. Exemplo, coeficientes beta de regressão linear/logística ou vetores de suporte em Support Vector Machines.
Procurar grade é usado para encontrar os hiperparâmetros ideais de um modelo que resulta nas previsões mais ‘precisas’.
Vejamos Grid-Search, construindo um modelo de classificação no conjunto de dados do Câncer de Mama.
Importar o conjunto de dados e ver as 10 primeiras linhas.
Eliminar :

Cada linha do conjunto de dados tem uma de duas classes possíveis: benigna (representada por 2) e maligna (representada por 4). Além disso, há 10 atributos neste conjunto de dados (mostrados acima) que serão usados para previsão, exceto o número de código da amostra que é o número de identificação.
Limpar os dados e renomear os valores da classe como 0/1 para construção do modelo (onde 1 representa um caso maligno). Observemos também a distribuição da classe.
Saída :

Existem 444 casos benignos e 239 casos malignos.
Saída :
>
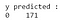
>
Da saída, podemos observar que existem 68 casos malignos e 103 casos benignos no conjunto de dados do teste. Entretanto, nosso classificador prevê todos os casos como benignos (pois é a classe majoritária).
Calcule as métricas de avaliação deste modelo.
Saída :
>
A precisão do modelo é de 60.2%, mas este é um caso em que a precisão pode não ser a melhor métrica para avaliar o modelo. Portanto, vamos dar uma olhada nas outras métricas de avaliação.

A figura acima é a matriz de confusão, com etiquetas e cores adicionadas para melhor intuição (Código para gerar isto pode ser encontrado aqui). Para resumir a matriz de confusão : VERDADEIROS POSITIVOS (TP)= 0,VERDADEIROS NEGATIVOS (TN)= 103,FALSOS POSITIVOS (FP)= 0, FALSOS NEGATIVOS (FN)= 68. As fórmulas para as métricas de avaliação são as seguintes:

Desde que o modelo não classifica correctamente nenhum caso maligno, as métricas de recolha e precisão são 0.
Agora que temos a precisão da linha de base, vamos construir um modelo de regressão logística com parâmetros padrão e avaliar o modelo.
Saída :
>
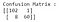
>
>
Ao ajustar o modelo de Regressão Logística com os parâmetros padrão, temos um modelo muito ‘melhor’. A precisão é de 94,7% e, ao mesmo tempo, a Precisão é de um impressionante 98,3%. Agora, vamos dar uma olhada novamente na matriz de confusão para os resultados deste modelo :

>
Vendo as instâncias malignas, podemos observar que 8 casos malignos foram classificados incorretamente como benignos (Falsos negativos). Também, apenas um caso benigno foi classificado como maligno (Falso positivo).
Um falso negativo é mais grave porque uma doença foi ignorada, o que pode levar à morte do paciente. Ao mesmo tempo, um falso positivo levaria a um tratamento desnecessário – incorrendo em custos adicionais.
Tentemos minimizar os falsos negativos usando a Grid Search para encontrar os parâmetros ideais. Grid search pode ser usado para melhorar qualquer métrica específica de avaliação.
A métrica que precisamos focar para reduzir os falsos negativos é Recall.
Pesquisa de Grade para maximizar a Recuperação
Saída :

>
>

>
Os hiperparâmetros que afinamos são:
- Penalty: l1 ou l2 que espécie a norma utilizada na penalização.
- C: Inverso da força de regularização – valores menores de C especificam regularização mais forte.
Também, na função Grid-search, temos o parâmetro de pontuação onde podemos especificar a métrica para avaliar o modelo em (Escolhemos recall como métrica). Da matriz de confusão abaixo, podemos ver que o número de falsos negativos reduziu, no entanto, é ao custo de aumentar os falsos positivos. A recordação após a busca na grade saltou de 88,2% para 91,1%, enquanto a precisão caiu para 87,3% de 98,3%.
>
 >
>>>
>
>
>
Você pode afinar ainda mais o modelo para obter um equilíbrio entre precisão e recordação usando a pontuação ‘f1’ como métrica de avaliação. Confira este artigo para uma melhor compreensão da métrica de avaliação.
Pesquisa Grid constrói um modelo para cada combinação de hiperparâmetros especificados e avalia cada modelo. Uma técnica mais eficiente para ajuste de hiperparâmetros é a busca aleatória – onde combinações aleatórias dos hiperparâmetros são usadas para encontrar a melhor solução.
Leave a Reply