Máscara de dados
O que é mascaramento de dados?
Máscara de dados é uma forma de criar uma falsificação, mas uma versão realista dos seus dados organizacionais. O objetivo é proteger dados sensíveis, enquanto fornece uma alternativa funcional quando dados reais não são necessários – por exemplo, em treinamento de usuários, demonstrações de vendas ou testes de software.
Processos de mascaramento de dados alteram os valores dos dados enquanto usam o mesmo formato. O objetivo é criar uma versão que não possa ser decifrada ou projetada de forma reversa. Existem várias maneiras de alterar os dados, incluindo embaralhamento de caracteres, substituição de palavras ou caracteres e criptografia.
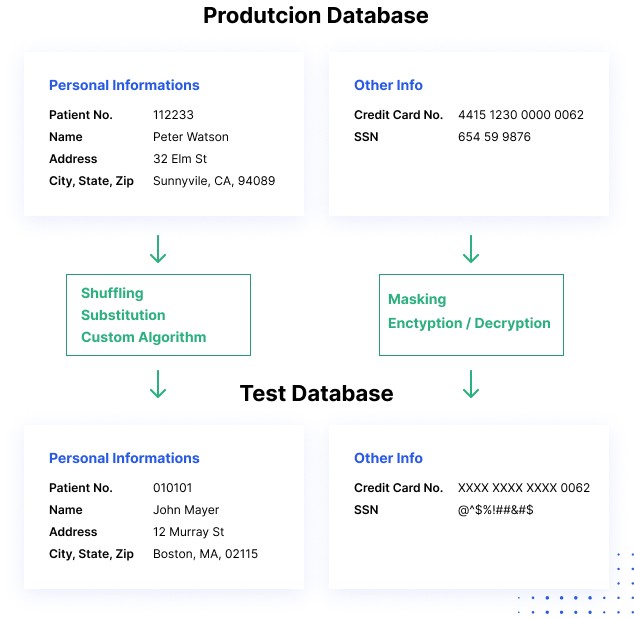
Como o mascaramento de dados funciona
Por que o mascaramento de dados é importante?
Aqui estão várias razões pelas quais o mascaramento de dados é essencial para muitas organizações:
- O mascaramento de dados resolve várias ameaças críticas – perda de dados, filtragem de dados, ameaças internas ou comprometimento de contas, e interfaces inseguras com sistemas de terceiros.
- Reduz os riscos de dados associados à adoção da nuvem.
- Faz com que os dados sejam inúteis para um atacante, mantendo muitas de suas propriedades funcionais inerentes.
- Permite compartilhar dados com usuários autorizados, como testadores e desenvolvedores, sem expor dados de produção.
- Pode ser usado para higienização de dados – a exclusão normal de arquivos ainda deixa vestígios de dados em mídias de armazenamento, enquanto a higienização substitui os valores antigos por valores mascarados.
Tipos de mascaramento de dados
Existem vários tipos de mascaramento de dados comumente usados para proteger dados sensíveis.
Máscara de dados estática
Processos de mascaramento de dados estáticos podem ajudá-lo a criar uma cópia higienizada do banco de dados. O processo altera todos os dados sensíveis até que uma cópia do banco de dados possa ser compartilhada com segurança. Normalmente, o processo envolve a criação de uma cópia de segurança de uma base de dados em produção, carregando-a em um ambiente separado, eliminando quaisquer dados desnecessários, e então mascarando os dados enquanto ela estiver em Stasis. A cópia mascarada pode então ser empurrada para o local de destino.
Deterministic Data Masking
Involve mapeando dois conjuntos de dados que têm o mesmo tipo de dados, de tal forma que um valor é sempre substituído por outro valor. Por exemplo, o nome “John Smith” é sempre substituído por “Jim Jameson”, em todos os lugares onde ele aparece em uma base de dados. Este método é conveniente para muitos cenários mas é inerentemente menos seguro.
Máscara de Dados On-the-Fly
Máscara de dados enquanto é transferido de sistemas de produção para sistemas de teste ou desenvolvimento antes dos dados serem salvos no disco. As organizações que implantam software frequentemente não podem criar uma cópia de backup do banco de dados de origem e aplicar mascaramento – elas precisam de uma maneira de transmitir continuamente dados da produção para múltiplos ambientes de teste.
Na mosca, o mascaramento envia subconjuntos menores de dados mascarados quando é necessário. Cada subconjunto de dados mascarados é armazenado no ambiente de desenvolvimento/teste para uso pelo sistema não produtivo.
É importante aplicar o mascaramento em tempo real a qualquer alimentação de um sistema de produção para um ambiente de desenvolvimento, logo no início de um projeto de desenvolvimento, para evitar problemas de conformidade e segurança.
Máscara de dados dinâmica
Semelhante ao mascaramento em tempo real, mas os dados nunca são armazenados em um armazenamento de dados secundário no ambiente de desenvolvimento/teste. Em vez disso, ele é transmitido diretamente do sistema de produção e consumido por outro sistema no ambiente de dev/teste.
Técnicas de Mascaramento de Dados
Vejamos algumas maneiras comuns de as organizações aplicarem o mascaramento a dados sensíveis. Ao proteger dados, profissionais de TI podem usar uma variedade de técnicas.
Criptação de dados
Quando os dados são criptografados, eles se tornam inúteis, a menos que o visualizador tenha a chave de decriptação. Essencialmente, os dados são mascarados pelo algoritmo de encriptação. Esta é a forma mais segura de encriptação de dados, mas também é complexa de implementar porque requer uma tecnologia para realizar a encriptação de dados em curso, e mecanismos para gerir e partilhar chaves de encriptação
Criptação de dados
Caracteres são reorganizados em ordem aleatória, substituindo o conteúdo original. Por exemplo, um número de identificação como 76498 em uma base de dados de produção, poderia ser substituído por 84967 em uma base de dados de teste. Este método é muito simples de implementar, mas só pode ser aplicado a alguns tipos de dados, e é menos seguro.
Nulling Out
Os dados aparecem em falta ou “nulos” quando vistos por um usuário não autorizado. Isto torna os dados menos úteis para fins de desenvolvimento e teste.
Value Variance
Os valores dos dados originais são substituídos por uma função, tal como a diferença entre o valor mais baixo e o mais alto de uma série. Por exemplo, se um cliente comprou vários produtos, o preço de compra pode ser substituído por um intervalo entre o preço mais alto e o mais baixo pago. Isso pode fornecer dados úteis para muitas finalidades, sem revelar o conjunto de dados original.
Substituição de dados
Valores de dados são substituídos por valores alternativos falsos, mas realistas. Por exemplo, nomes reais de clientes são substituídos por uma seleção aleatória de nomes de uma lista telefônica.
Embaralhar dados
Similiar à substituição, exceto que os valores de dados são trocados dentro do mesmo conjunto de dados. Os dados são rearranjados em cada coluna usando uma sequência aleatória; por exemplo, alternando entre nomes reais de clientes através de vários registos de clientes. O conjunto de saída se parece com dados reais, mas não mostra a informação real para cada indivíduo ou registro de dados.
Pseudonimização
De acordo com o Regulamento Geral de Proteção de Dados da UE (GDPR), um novo termo foi introduzido para cobrir processos como máscara de dados, criptografia e hashing para proteger dados pessoais: pseudonimização.
Pseudonimização, como definido no GDPR, é qualquer método que garante que os dados não podem ser usados para identificação pessoal. Ela requer a remoção de identificadores diretos e, de preferência, evitar múltiplos identificadores que, quando combinados, possam identificar uma pessoa.
Além disso, chaves de criptografia, ou outros dados que possam ser usados para reverter para os valores originais dos dados, devem ser armazenados separadamente e com segurança.
Melhores Práticas de Mascaramento de Dados
Determinar o Escopo do Projeto
A fim de realizar o mascaramento de dados de forma eficaz, as empresas devem saber quais informações precisam ser protegidas, quem está autorizado a vê-la, quais aplicações utilizam os dados e onde eles residem, tanto em domínios de produção como não-produção. Embora isso possa parecer fácil no papel, devido à complexidade das operações e múltiplas linhas de negócios, esse processo pode exigir um esforço substancial e deve ser planejado como uma etapa separada do projeto.
Integridade Referencial
Integridade Referencial significa que cada “tipo” de informação proveniente de uma aplicação de negócios deve ser mascarada usando o mesmo algoritmo.
Em grandes organizações, uma única ferramenta de mascaramento de dados usada em toda a empresa não é viável. Cada linha de negócio pode ser obrigada a implementar seu próprio mascaramento de dados devido a requisitos orçamentários/de negócio, diferentes práticas de administração de TI ou diferentes requisitos de segurança/regulamentação.
Assegure que diferentes ferramentas e práticas de mascaramento de dados em toda a organização sejam sincronizadas, quando lidando com o mesmo tipo de dados. Isso evitará desafios posteriores quando os dados precisarem ser usados entre linhas de negócios.
Segurar os Algoritmos de Mascaramento de Dados
É fundamental considerar como proteger os algoritmos de criação de dados, bem como conjuntos de dados ou dicionários alternativos usados para codificar os dados. Como apenas usuários autorizados devem ter acesso aos dados reais, estes algoritmos devem ser considerados extremamente sensíveis. Se alguém aprender quais algoritmos de mascaramento repetíveis estão sendo usados, pode fazer engenharia reversa de grandes blocos de informações sensíveis.
Uma melhor prática de mascaramento de dados, que é explicitamente exigida por alguns regulamentos, é garantir a separação de funções. Por exemplo, o pessoal de segurança TI determina que métodos e algoritmos serão usados em geral, mas configurações específicas de algoritmos e listas de dados devem ser acessíveis apenas pelos proprietários dos dados no departamento relevante.
Mascaramento de dados com Imperva
Imperva é uma solução de segurança que fornece capacidades de mascaramento e criptografia de dados, permitindo que você ofusque dados sensíveis para que sejam inúteis para um atacante, mesmo que de alguma forma extraídos.
Além de fornecer mascaramento de dados, a solução de segurança de dados da Imperva protege seus dados onde quer que eles vivam – nas instalações, na nuvem e em ambientes híbridos. Ela também fornece segurança e equipes de TI com total visibilidade de como os dados estão sendo acessados, usados e movidos na organização.
Nossa abordagem abrangente conta com várias camadas de proteção, incluindo:
- Firewall de banco de dados – bloqueia a injeção de SQL e outras ameaças, enquanto avalia as vulnerabilidades conhecidas.
- Gestão de direitos do usuário – monitoramento de acesso aos dados e atividades de usuários privilegiados para identificar privilégios excessivos, inadequados e não utilizados.
- Prevenção de perda de dados (DLP) – inspeciona dados em movimento, em repouso em servidores, em armazenamento em nuvem ou em dispositivos endpoint.
- Análise do comportamento do usuário – estabelece linhas de base do comportamento de acesso aos dados, usa o aprendizado da máquina para detectar e alertar sobre atividades anormais e potencialmente arriscadas.
- Descoberta e classificação dos dados – revela a localização, volume e contexto dos dados no local e na nuvem.
- Monitoramento da atividade do banco de dados – monitora bancos de dados relacionais, data warehouses, grandes dados e mainframes para gerar alertas em tempo real sobre violações de políticas.
- Priorização de alertas – a Imperva usa a IA e a tecnologia de aprendizado de máquinas para olhar através do fluxo de eventos de segurança e priorizar os mais importantes.
Leave a Reply