Maskowanie danych
Co to jest maskowanie danych?
Maskowanie danych to sposób na stworzenie fałszywej, ale realistycznej wersji danych organizacyjnych. Celem jest ochrona wrażliwych danych, przy jednoczesnym zapewnieniu funkcjonalnej alternatywy, gdy prawdziwe dane nie są potrzebne – na przykład podczas szkolenia użytkowników, demonstracji sprzedaży lub testowania oprogramowania.
Procesy maskowania danych zmieniają wartości danych przy użyciu tego samego formatu. Celem jest stworzenie wersji, która nie może być rozszyfrowana lub poddana inżynierii wstecznej. Istnieje kilka sposobów zmiany danych, w tym tasowanie znaków, zastępowanie słów lub znaków oraz szyfrowanie.
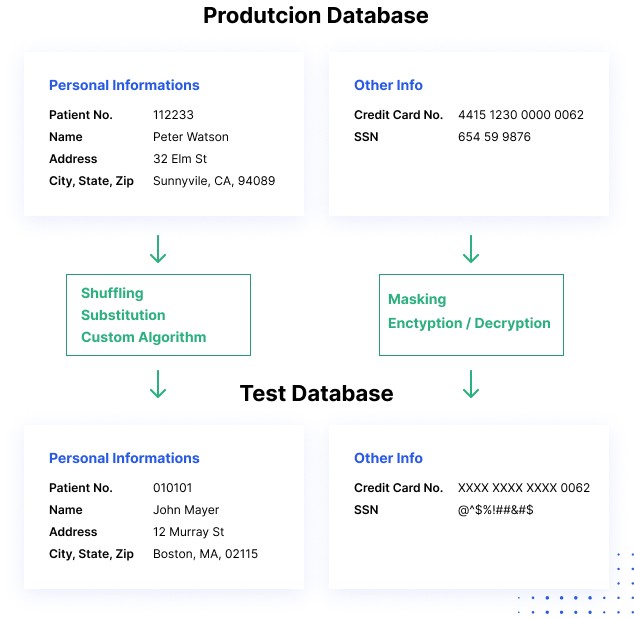
Jak działa maskowanie danych
Dlaczego maskowanie danych jest ważne?
Jest kilka powodów, dla których maskowanie danych jest niezbędne dla wielu organizacji:
- Maskowanie danych rozwiązuje kilka krytycznych zagrożeń – utratę danych, eksfiltrację danych, zagrożenia wewnętrzne lub kompromitację kont oraz niezabezpieczone interfejsy z systemami stron trzecich.
- Redukuje ryzyko związane z danymi związane z przyjęciem chmury.
- Uczynia dane bezużytecznymi dla atakującego, zachowując wiele z ich nieodłącznych właściwości funkcjonalnych.
- Pozwala na udostępnianie danych autoryzowanym użytkownikom, takim jak testerzy i programiści, bez narażania danych produkcyjnych.
- Może być używane do sanityzacji danych – normalne usuwanie plików nadal pozostawia ślady danych na nośnikach pamięci, podczas gdy sanityzacja zastępuje stare wartości zamaskowanymi.
Typy maskowania danych
Istnieje kilka typów maskowania danych powszechnie używanych do zabezpieczania danych wrażliwych.
Statyczne maskowanie danych
Statyczne procesy maskowania danych mogą pomóc w utworzeniu sanityzowanej kopii bazy danych. Proces ten zmienia wszystkie wrażliwe dane do czasu, gdy kopia bazy danych może być bezpiecznie udostępniona. Zazwyczaj proces ten polega na utworzeniu kopii zapasowej produkcyjnej bazy danych, załadowaniu jej do oddzielnego środowiska, wyeliminowaniu wszelkich zbędnych danych, a następnie zamaskowaniu danych, gdy znajdują się one w stanie stazy. Zamaskowana kopia może następnie zostać przepchnięta do lokalizacji docelowej.
Deterministyczne maskowanie danych
Zajmuje się mapowaniem dwóch zestawów danych, które mają ten sam typ danych, w taki sposób, że jedna wartość jest zawsze zastępowana przez inną wartość. Na przykład, nazwisko „John Smith” jest zawsze zastępowane przez „Jim Jameson”, gdziekolwiek pojawia się w bazie danych. Ta metoda jest wygodna dla wielu scenariuszy, ale z natury jest mniej bezpieczna.
Maskowanie danych w locie
Maskowanie danych podczas przenoszenia ich z systemów produkcyjnych do systemów testowych lub rozwojowych, zanim dane zostaną zapisane na dysku. Organizacje, które często wdrażają oprogramowanie, nie mogą utworzyć kopii zapasowej źródłowej bazy danych i zastosować maskowania – potrzebują sposobu na ciągłe przesyłanie danych z produkcji do wielu środowisk testowych.
Maskowanie w locie wysyła mniejsze podzbiory zamaskowanych danych, gdy są one wymagane. Każdy podzbiór zamaskowanych danych jest przechowywany w środowisku dev/test do wykorzystania przez system nieprodukcyjny.
Ważne jest zastosowanie maskowania w locie do każdego strumienia danych z systemu produkcyjnego do środowiska programistycznego, na samym początku projektu rozwojowego, aby zapobiec problemom związanym ze zgodnością i bezpieczeństwem.
Dynamiczne maskowanie danych
Podobne do maskowania w locie, ale dane nigdy nie są przechowywane we wtórnym magazynie danych w środowisku dev/test. Są one raczej przesyłane strumieniowo bezpośrednio z systemu produkcyjnego i konsumowane przez inny system w środowisku dev/test.
Techniki maskowania danych
Przeanalizujmy kilka powszechnych sposobów, w jakie organizacje stosują maskowanie danych wrażliwych. Podczas ochrony danych specjaliści IT mogą stosować różne techniki.
Szyfrowanie danych
Gdy dane są zaszyfrowane, stają się bezużyteczne, chyba że osoba przeglądająca je posiada klucz deszyfrujący. Zasadniczo, dane są maskowane przez algorytm szyfrowania. Jest to najbezpieczniejsza forma maskowania danych, ale jest również złożona do wdrożenia, ponieważ wymaga technologii do wykonywania ciągłego szyfrowania danych oraz mechanizmów zarządzania i udostępniania kluczy szyfrujących
Skrobanie danych
Znaki są reorganizowane w przypadkowej kolejności, zastępując oryginalną treść. Na przykład numer ID, taki jak 76498 w produkcyjnej bazie danych, może zostać zastąpiony przez 84967 w testowej bazie danych. Ta metoda jest bardzo prosta w implementacji, ale może być stosowana tylko do niektórych typów danych i jest mniej bezpieczna.
Nulling Out
Dane wydają się brakujące lub „zerowe”, gdy są przeglądane przez nieautoryzowanego użytkownika. Sprawia to, że dane są mniej przydatne do celów rozwoju i testowania.
Wariantność wartości
Oryginalne wartości danych są zastępowane przez funkcję, taką jak różnica między najniższą i najwyższą wartością w serii. Na przykład, jeśli klient zakupił kilka produktów, cena zakupu może zostać zastąpiona zakresem pomiędzy najwyższą i najniższą zapłaconą ceną. Może to dostarczyć użytecznych danych do wielu celów, bez ujawniania oryginalnego zbioru danych.
Zastępowanie danych
Wartości danych są zastępowane fałszywymi, ale realistycznymi, wartościami alternatywnymi. Na przykład prawdziwe nazwiska klientów są zastępowane losowym wyborem nazwisk z książki telefonicznej.
Tasowanie danych
Podobne do zastępowania, z wyjątkiem tego, że wartości danych są zamieniane w obrębie tego samego zbioru danych. Dane są przestawiane w każdej kolumnie przy użyciu losowej sekwencji; na przykład, przełączanie między prawdziwymi nazwiskami klientów w wielu rekordach klientów. Zbiór wyjściowy wygląda jak prawdziwe dane, ale nie pokazuje prawdziwych informacji dla każdej osoby lub rekordu danych.
Pseudonimizacja
Zgodnie z ogólnym rozporządzeniem UE o ochronie danych (GDPR) wprowadzono nowy termin obejmujący procesy takie jak maskowanie danych, szyfrowanie i haszowanie w celu ochrony danych osobowych: pseudonimizacja.
Pseudonimizacja, zgodnie z definicją zawartą w GDPR, to dowolna metoda, która zapewnia, że dane nie mogą być używane do identyfikacji osób. Wymaga ona usunięcia bezpośrednich identyfikatorów, a najlepiej unikania wielu identyfikatorów, które po połączeniu mogą zidentyfikować osobę.
Dodatkowo klucze szyfrujące lub inne dane, które mogą być użyte do przywrócenia oryginalnych wartości danych, powinny być przechowywane oddzielnie i bezpiecznie.
Data Masking Best Practices
Determine the Project Scope
Aby skutecznie przeprowadzić maskowanie danych, firmy powinny wiedzieć, jakie informacje muszą być chronione, kto jest upoważniony do ich oglądania, jakie aplikacje korzystają z danych i gdzie one rezydują, zarówno w domenach produkcyjnych, jak i nieprodukcyjnych. Chociaż na papierze może się to wydawać łatwe, ze względu na złożoność operacji i wiele linii biznesowych, proces ten może wymagać znacznego wysiłku i musi być zaplanowany jako oddzielny etap projektu.
Zapewnienie integralności referencyjnej
Integralność referencyjna oznacza, że każdy „typ” informacji pochodzący z aplikacji biznesowej musi być maskowany przy użyciu tego samego algorytmu.
W dużych organizacjach jedno narzędzie do maskowania danych używane w całym przedsiębiorstwie nie jest wykonalne. Każda linia biznesowa może być zobowiązana do wdrożenia własnego maskowania danych ze względu na wymagania budżetowe/biznesowe, różne praktyki administracji IT lub różne wymagania bezpieczeństwa/regulacyjne.
Upewnij się, że różne narzędzia i praktyki maskowania danych w całej organizacji są zsynchronizowane, gdy mają do czynienia z tym samym typem danych. Zapobiegnie to późniejszym problemom, gdy dane będą musiały być używane na różnych liniach biznesowych.
Zabezpieczenie algorytmów maskowania danych
Krytyczne jest rozważenie sposobu ochrony algorytmów tworzenia danych, jak również alternatywnych zestawów danych lub słowników używanych do zakodowania danych. Ponieważ tylko uprawnieni użytkownicy powinni mieć dostęp do prawdziwych danych, algorytmy te powinny być uważane za niezwykle wrażliwe. Jeśli ktoś dowie się, które powtarzalne algorytmy maskowania są używane, może odtworzyć duże bloki wrażliwych informacji.
Najlepszą praktyką maskowania danych, która jest wyraźnie wymagana przez niektóre przepisy, jest zapewnienie rozdziału obowiązków. Na przykład, personel bezpieczeństwa IT określa, jakie metody i algorytmy będą ogólnie stosowane, ale konkretne ustawienia algorytmów i listy danych powinny być dostępne tylko dla właścicieli danych w odpowiednim dziale.
Maskowanie danych z Impervą
Imperva to rozwiązanie bezpieczeństwa, które zapewnia maskowanie i szyfrowanie danych, pozwalając na ukrycie wrażliwych danych tak, aby były bezużyteczne dla atakującego, nawet jeśli zostaną w jakiś sposób wydobyte.
Oprócz maskowania danych, rozwiązanie bezpieczeństwa danych Imperva chroni dane bez względu na to, gdzie się znajdują – w siedzibie, w chmurze i w środowiskach hybrydowych. Zapewnia ono również zespołom ds. bezpieczeństwa i IT pełny wgląd w to, w jaki sposób dane są udostępniane, wykorzystywane i przenoszone w obrębie organizacji.
Nasze kompleksowe podejście opiera się na wielu warstwach ochrony, w tym:
- Zapora ogniowa bazy danych-blokuje wstrzykiwanie kodu SQL i inne zagrożenia, jednocześnie analizując znane luki w zabezpieczeniach.
- Zarządzanie prawami użytkownika – monitoruje dostęp do danych i działania uprzywilejowanych użytkowników w celu identyfikacji nadmiernych, niewłaściwych i niewykorzystywanych uprawnień.
- Zapobieganie utracie danych (DLP)- bada dane w ruchu, w spoczynku na serwerach, w pamięci masowej w chmurze lub na urządzeniach punktów końcowych.
- Analityka zachowań użytkowników – tworzy linie bazowe zachowań związanych z dostępem do danych, wykorzystuje uczenie maszynowe do wykrywania i ostrzegania o nietypowych i potencjalnie ryzykownych działaniach.
- Odkrywanie i klasyfikacja danych – ujawnia lokalizację, objętość i kontekst danych w siedzibie firmy i w chmurze.
- Monitorowanie aktywności baz danych-monitoruje relacyjne bazy danych, hurtownie danych, big data i komputery mainframe, aby generować w czasie rzeczywistym alerty o naruszeniach zasad.
- Priorytetyzacja alertów-Imperva wykorzystuje sztuczną inteligencję i technologię uczenia maszynowego, aby przejrzeć strumień zdarzeń związanych z bezpieczeństwem i nadać priorytety tym, które mają największe znaczenie.
.
Leave a Reply