Grid Search for model tuning
Hiperparametr modelu jest cechą modelu, która jest zewnętrzna w stosunku do modelu i której wartość nie może być oszacowana na podstawie danych. Wartość hiperparametru musi być ustalona przed rozpoczęciem procesu uczenia. Na przykład, c w Support Vector Machines, k w k-Nearest Neighbors, liczba ukrytych warstw w Neural Networks.
W przeciwieństwie do tego, parametr jest wewnętrzną cechą modelu i jego wartość może być oszacowana na podstawie danych. Przykład, współczynniki beta regresji liniowej/logistycznej lub wektory wsparcia w maszynach wektorów wsparcia.
Grid-search jest używany do znalezienia optymalnych hiperparametrów modelu, co skutkuje najbardziej „dokładnymi” przewidywaniami.
Przyjrzyjrzyjmy się Grid-Search budując model klasyfikacji na zbiorze danych Breast Cancer.
Importujemy zbiór danych i przeglądamy 10 najlepszych wierszy.
Wyjście :

Każdy wiersz w zbiorze danych ma jedną z dwóch możliwych klas: łagodną (reprezentowaną przez 2) i złośliwą (reprezentowaną przez 4). Ponadto, istnieje 10 atrybutów w tym zbiorze danych (pokazanych powyżej), które będą używane do predykcji, z wyjątkiem Numeru kodu próbki, który jest numerem id.
Czyścimy dane i zmieniamy nazwy wartości klas jako 0/1 do budowy modelu (gdzie 1 reprezentuje przypadek złośliwy). Zaobserwujmy również rozkład klas.
Wyjście :

Istnieją 444 przypadki łagodne i 239 złośliwych.
Wyjście :
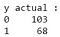
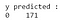
Z danych wyjściowych można zauważyć, że w testowym zbiorze danych jest 68 złośliwych i 103 łagodne przypadki. Jednak nasz klasyfikator przewiduje wszystkie przypadki jako łagodne (ponieważ jest to klasa większościowa).
Oblicz metryki oceny tego modelu.
Wyjście :

Dokładność modelu wynosi 60.2%, ale jest to przypadek, w którym dokładność może nie być najlepszą metryką do oceny modelu. Spójrzmy więc na inne metryki oceny.

Powyższy rysunek to macierz konfuzji, z dodanymi etykietami i kolorami dla lepszej intuicji (Kod do wygenerowania tego można znaleźć tutaj). Podsumowując macierz konfuzji : TRUE POSITIVES (TP)= 0,TRUE NEGATIVES (TN)= 103,FALSE POSITIVES (FP)= 0, FALSE NEGATIVES (FN)= 68. Wzory na metryki oceny są następujące :

Ponieważ model nie klasyfikuje poprawnie żadnego przypadku złośliwego, metryki recall i precision wynoszą 0.
Teraz, gdy mamy już bazową dokładność, zbudujmy model regresji logistycznej z domyślnymi parametrami i oceńmy model.
Wyjście :

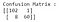
Dopasowując model regresji logistycznej z domyślnymi parametrami, mamy znacznie „lepszy” model. Dokładność wynosi 94,7%, a w tym samym czasie Precyzja jest oszałamiająca 98,3%. Przyjrzyjmy się teraz ponownie macierzy konfuzji dla wyników tego modelu :

Patrząc na błędnie sklasyfikowane przypadki, możemy zauważyć, że 8 złośliwych przypadków zostało błędnie sklasyfikowanych jako łagodne (False negatives). Również, tylko jeden przypadek łagodny został sklasyfikowany jako złośliwy (False positive).
Fałszywy negatyw jest poważniejszy, ponieważ choroba została zignorowana, co może prowadzić do śmierci pacjenta. W tym samym czasie, fałszywy wynik pozytywny doprowadziłby do niepotrzebnego leczenia – ponosząc dodatkowe koszty.
Postarajmy się zminimalizować fałszywe negatywy poprzez zastosowanie wyszukiwania siatkowego w celu znalezienia optymalnych parametrów. Przeszukiwanie siatki może być użyte do poprawy dowolnej metryki oceny.
Metryka, na której musimy się skupić, aby zmniejszyć liczbę fałszywych negatywów to Recall.
Grid Search to maximize Recall
Output :


Hiperparametry, które dostroiliśmy to:
- Kary: l1 lub l2, które określają gatunek normy użytej do penalizacji.
- C: Inverse of regularization strength- mniejsze wartości C określają silniejszą regularyzację.
Ponadto, w funkcji Grid-search, mamy parametr scoring, gdzie możemy określić metrykę do oceny modelu (Wybraliśmy recall jako metrykę). Z poniższej macierzy konfuzji widzimy, że liczba fałszywych negatywów zmniejszyła się, jednak stało się to kosztem zwiększenia liczby fałszywych pozytywów. Odwołanie po przeszukiwaniu siatki skoczyło z 88,2% do 91,1%, podczas gdy precyzja spadła do 87,3% z 98,3%.

Możesz dalej dostroić model, aby osiągnąć równowagę pomiędzy precyzją i odwołaniem, używając wyniku 'f1′ jako metryki oceny. Sprawdź ten artykuł, aby lepiej zrozumieć metryki oceny.
Wyszukiwanie w siatce buduje model dla każdej kombinacji hiperparametrów i ocenia każdy model. Bardziej efektywną techniką dostrajania hiperparametrów jest wyszukiwanie randomizowane – gdzie losowe kombinacje hiperparametrów są używane do znalezienia najlepszego rozwiązania.
Leave a Reply