artykuł techniczny
Ten artykuł został zaktualizowany w celu uwzględnienia oprogramowania GC Portal dla systemów Linux i Java Desktop System (JDS), dostępnego zarówno dla serwerów Sun Java System Application Server 7 (dawniej Sun ONE Application Server 7 (S1AS7)), jak i Tomcat. Pierwotnie było ono udostępnione tylko dla Solaris i Windows. Ta wersja oprogramowania GC Portal zawiera również VisualGC zintegrowany z GC Portal.
GC Portal umożliwia analizę i dostrajanie wydajności aplikacji Java z perspektywy zbierania śmieci (garbage collection, GC) poprzez eksplorację verbose:gc logów generowanych przez maszynę JVM. GC Portal jest pojedynczą stroną poświęconą zagadnieniom GC i zawiera obszerną kolekcję białych ksiąg, studiów przypadku i innych materiałów. Portal jest przeznaczony do użytku z HotSpot JVM firmy Sun Microsystems, dystrybuowaną jako część Java 2, Standard Edition (J2SE). Korzystanie z GC Portal umożliwia programistom modelowanie zachowań aplikacji i JVM z perspektywy GC. W tym artykule przedstawiono projekt i funkcje GC Portal, aby umożliwić programistom wykorzystanie go jako narzędzia do analizowania i dostrajania GC.
GC Portal wymaga użycia następujących przełączników przez maszynę JVM w celu wygenerowania verbose:gc logów, które są przetwarzane przez Portal w celu analizy.
-verbose:gc -XX:+PrintGCTimeStamps -XX:+PrintGCDetails Inne przełączniki JVM nie są wymagane do generowania odpowiednich dzienników dla portalu GC, ale można je dodać, jeśli uzna się to za odpowiednie do dostrojenia i dopasowania JVM i aplikacji. Uwaga: Przełączniki -XX są niestandardowe i mogą ulec zmianie bez powiadomienia w przyszłych wydaniach JVM.
Modelowanie aplikacji i dostrajanie wydajności z perspektywy GC
Modelowanie aplikacji Java umożliwia programistom usunięcie nieprzewidywalności przypisanej do częstotliwości i czasu trwania przerw na zbieranie śmieci. Te pauzy są bezpośrednio związane z:
- Liczbą i całkowitym rozmiarem obiektów utworzonych i żywych
- Średnim czasem życia tych obiektów
- Rozmiar sterty JVM
Bazując na analizie dostarczonej przez GC Portal dla określonego zestawu verbose:gc plików dziennika przekazanych do Portalu, programiści mogą zbudować model, który pomoże im lepiej zrozumieć zachowanie aplikacji i JVM.
Dzienniki verbose:gc zawierają cenne informacje o:
- Czasach wstrzymywania GC
- Częstotliwości GC
- Czasach uruchamiania aplikacji
- Rozmiarze tworzonych i niszczonych obiektów
- Rędkości tworzenia obiektów
- Pamięci odzyskiwanej przy każdym GC
Zachowanie aplikacji można wykreślić na wykresie i przeanalizować w celu określenia różnych zależności między czasem trwania wstrzymywania, częstotliwością pauz, szybkością tworzenia obiektów i uwolnioną pamięcią. Analiza tych informacji może umożliwić programistom dostrojenie wydajności aplikacji, optymalizując częstotliwość GC i czasy zbierania przez określenie najlepszych rozmiarów sterty, innych opcji JVM i alternatywnych algorytmów GC dla danej sytuacji.
Informacje pochodzące z logów verbose:gc do analizowania i modelowania zachowania GC
Tego rodzaju informacje mogą być używane do dostrajania wydajności procesu zbierania śmieci.
Średnie pauzy GC w młodym i starym pokoleniu
Średni czas zawieszenia aplikacji, gdy w JVM odbywa się zbieranie śmieci.
Średnia częstotliwość GC w młodym i starym pokoleniu
Częstotliwość, z jaką działa garbage collector w młodym i starym pokoleniu. Można to uzyskać, ponieważ instancja czasowa każdej aktywności GC jest rejestrowana.
Narzut sekwencyjny GC
Procent czasu systemowego, na który aplikacja jest zawieszona, aby mogło nastąpić zbieranie śmieci. Obliczany jako Avg. GC pauza * Avg. GC frequency * 100%
GC concurrent overhead
Procent czasu systemowego, w którym zbieranie śmieci odbywa się równolegle z aplikacją. Obliczony jako Avg. concurrent GC time (sweeping phase) * Avg. concurrent GC frequency / no. of CPUs
Pamięć przetworzona przez każdy GC w młodej i starej generacji
Całkowita ilość śmieci zebranych podczas każdego GC.
Szybkość alokacji
Szybkość, z jaką dane są alokowane przez aplikację w młodej generacji. Jeśli zajętość sterty młodego pokolenia_at_start_of_current_gc=x, zajętość_at_end_of_previous_gc = y, a częstotliwość GC wynosi 1 na sekundę, to szybkość alokacji wynosi w przybliżeniu x-y na sekundę.
Szybkość awansu
Szybkość, z jaką dane są awansowane do starego pokolenia.
Całkowite dane alokowane przez aplikację
Są to całkowite dane, które są alokowane przez aplikację na transakcję.
Dane całkowite można podzielić na dane krótkoterminowe i dane długoterminowe
Dane długoterminowe to te, które przetrwają cykle GC młodego pokolenia i są promowane do starego pokolenia.
Dane krótkoterminowe
Dane krótkoterminowe, które umierają bardzo szybko i są gromadzone w młodym pokoleniu. Można to obliczyć jako Całkowita ilość danych – Dane długoterminowe.
Całkowita ilość aktywnych danych
Jest to całkowita ilość danych żyjących w dowolnym momencie czasu. Jest to krytyczne dla budowania modelu dla wielkości sterty JVM. Na przykład, dla obciążenia 100 transakcji na sekundę, z długoterminowymi danymi 50K na transakcję trwającą minimum 40 sekund, minimalny ślad pamięciowy starej generacji musiałby być
50K*40s*100 = 200M
Wycieki pamięci
Można je wykryć, a błędy „poza pamięcią” można lepiej zrozumieć, monitorując śmieci zebrane przy każdym przemiataniu, jak pokazują te dzienniki.
Flagi i przełączniki do generowania logów GC
Istnieje wiele użytecznych informacji związanych z GC, które JVM może rejestrować w pliku. Te informacje są używane przez GC Portal do dostrajania i określania rozmiaru aplikacji i JVM z perspektywy GC. Logi zawierające szczegółowe informacje GC są generowane, gdy aplikacja Java jest uruchamiana z następującymi przełącznikami:
– verbose:gc Ta flaga włącza rejestrowanie informacji GC. Dostępna we wszystkich maszynach JVM.
-XX:+PrintGCTimeStamps Drukuje czasy, w których występują GC w stosunku do początku aplikacji. Dostępne tylko od J2SE1.4.0.
-XX:+PrintGCDetails Podaje szczegóły dotyczące GC, takie jak:
- Rozmiar młodego i starego pokolenia przed i po GC
- Rozmiar całkowitej sterty
- Czas potrzebny na GC w młodym i starym pokoleniu
- Rozmiar obiektów promowanych przy każdym GC
Dostępne tylko od JVM1.4.0.
Używanie portalu GC do modelowania aplikacji i dostrajania wydajności
Portal GC może być użyty do lepszego zrozumienia zachowania GC aplikacji, aby dostroić wydajność i rozmiar aplikacji, aby działały optymalnie w warunkach odchudzenia, szczytu i rozruchu. Obsługuje J2SE1.2.2, J2SE1.3, J2SE1.4 i J2SE1.4.1, włączając w to dwie nowe implementacje zbierania śmieci, Parallel Collector i Concurrent Collector. Pozwala programistom na przesyłanie plików dziennika GC i analizowanie zachowania aplikacji na podstawie tych plików dziennika. Uwzględnia również pewne informacje specyficzne dla aplikacji i środowiska, w tym:
-
Transaction Rate lub Server Load
Dotyczy to typowych aplikacji po stronie serwera działających w konfiguracji klient-serwer. W przypadku takich aplikacji jest to szybkość, z jaką klient może generować stałe obciążenie dla serwera do przetworzenia, i jest przydatna do analizy stanu ustalonego serwera. Analiza stanu ustalonego może obejmować kilka scenariuszy, takich jak najgorszy przypadek/szczyt/obciążenie lub sytuacja przeciętna. Informacje te nie są obowiązkowe. Jeśli nie są dostępne lub nie mają zastosowania, można je zignorować. W takim przypadku należy również zignorować niektóre informacje prezentowane przez portal, które obejmują:
- Przepustowość teoretyczna
- Dane krótkoterminowe
- Dane długoterminowe
-
Liczba procesorów na maszynie docelowej
Ta informacja jest używana do wykonywania pewnych obliczeń przez portal, takich jak narzut GC współbieżnego.
-
Wersja JVM używana przez aplikację (1.2.2_xx, 1.3.x, 1.4.0, 1.4.1)
Ponieważ format dziennika
verbose:gcnie jest standardowy i nastąpiły zmiany w JVM, ta informacja jest potrzebna portalowi GC.
GC Portal Design
GC Portal składa się z czterech silników:
- Analyzer and reporting engine
- Graphical engine
- Intelligence engine
- Session and storage engine
- VisualGC
Analyzer and Reporting Engine
- Wczytuje
verbose:gcpliki logów, kopie je i raportuje:- Pauzy GC w młodym i starym pokoleniu
- Częstotliwość GC w młodym i starym pokoleniu
- Szybkość alokacji obiektów
- Szybkość awansu obiektów z młodego do starego pokolenia
- Całkowity czas GC
- Całkowity czas aplikacji
- Rozmiary sterty początkowej i końcowej w młodym i starym pokoleniu
- Sekwencyjne GC overhead
- GC concurrent overhead
- Oblicza i przedstawia informacje związane z aplikacją
- Krótkoterminowe dane na transakcję
- Długoterminowe dane na transakcję
- Teoretyczna maksymalna przepustowość
- Wydajność CPU
Te informacje można zignorować w przypadku aplikacji, które nie są oparte na transakcjach, ale jest istotna dla aplikacji po stronie klienta lub tych, które mogą wykazywać ekstremalnie fazowe zachowanie.
- Prezentuje szczegółowe zachowanie aplikacji i JVM związane z GC w czasie
- Użytkownik może przeglądać dane GC, próbkowane w wybranych odstępach czasu dla całego przebiegu.
Te szczegółowe informacje GC próbkowane w wybranych odstępach czasu dla całego przebiegu są niezwykle przydatne, gdy aplikacje wykazują zróżnicowane zachowanie w czasie, takie jak aplikacje fazowe, cykliczne lub losowo reaktywne, a średnie informacje podsumowujące mogą być w rezultacie przekrzywione. Ta szczegółowa i próbkowana informacja może być użyta, aby zobaczyć zachowanie aplikacji i JVM jak zmienia się w czasie.
- Szczegółowe informacje o recyklingu pamięci w czasie w młodym i starym pokoleniu
- Pamięć przed GC
- Pamięć po GC
- Pamięć zwolniona przy każdym GC
- Informacje o starzeniu się obiektów w młodym pokoleniu
- Dostępne, jeśli przełącznik
-XX:+PrintTenuringDistributionjest używany do generowania dzienników.
- Dostępne, jeśli przełącznik
Rysunek 1 jest zrzutem przykładowego raportu prezentowanego przez silnik Analyzer portalu GC.
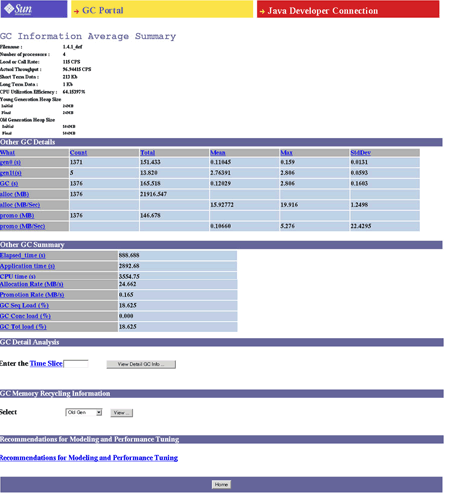
Rysunek 1. Snapshot of the Analysis Engine from the GC Portal
Graphical Engine
Większość informacji, które są prezentowane przez silnik Analizatora w formie tabelarycznej, może być wykreślona graficznie. Wiele wykresów może być umieszczonych na tym samym wykresie w celu ułatwienia porównań.
- Graficzna prezentacja szczegółowej analizy GC na osi czasu
- Graficzna prezentacja informacji o recyklingu pamięci przy każdym GC
- Graficzne porównanie informacji GC z różnych plików dziennika
- Graficzna prezentacja informacji o wieku obiektów dla każdego „wieku”
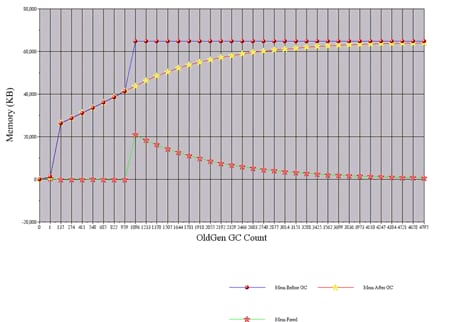
Rysunek 2. Zrzut z silnika graficznego Portalu GC
Silnik inteligencji
Silnik inteligencji składa się z:
-
Ogólne zalecenia
Ta sekcja zawiera dokumenty obejmujące ogólne informacje i zalecenia dotyczące dostrajania wydajności GC. Portal nie dostarcza dynamicznych zaleceń ani automatycznego dostrajania. Zalecenia zawierają ogólne informacje o tym, jak:
- Zmniejszyć przerwę i częstotliwość GC
- Zmniejszyć sekwencyjny narzut GC
- Rozmiar sterty młodej i starej generacji do obsługi danego obciążenia
- Wykrywanie wycieków pamięci
- Wybór kolektorów
- Wybór różnych opcji i przełączników JVM.
- Modelowanie empiryczne
Ranga działania aplikacji na podstawie danych analizowanych z wielu
verbose:gclogów. Użytkownik może wybrać pliki (spośród wszystkich, które zostały załadowane) do modelowania w oparciu o następujące wybory:- Transaction rate
- Liczba procesorów
- Rozmiar młodej generacji
- Rozmiar starej generacji
- Wersja JDK
- Rozmiary sterty
Użytkownik może uszeregować optymalne środowisko JVM w oparciu o następujące kryteria:
- GC pause
- GC sequential overhead
- GC frequency
- CPU efficiency
Użytkownik może również wyświetlić graficzne porównanie różnych przebiegów.
-
Prognozy rozmiaru i strojenia poprzez scenariusze „what-if”
Jak zachowanie GC może się zmienić wraz ze zmianą rozmiaru młodego pokolenia. Ta funkcjonalność jest obecnie ograniczona i działa tylko na J2SE1.4.1 i nowszych przy użyciu Concurrent Collector. Wynik projekcji pokazuje potencjalne zmiany w:
- Pauzie GC
- Częstotliwości GC
- Obciążeniu sekwencyjnym GC
- UżyciuCPU (%)
- Przyspieszeniu
- Stopniu alokacji
- Stopniu propagacji
- Rozmiarze Short-lived data
- Size of long-lived data
-
Studia przypadków
Kilka prawdziwych studiów przypadku, jak dostroić z perspektywy GC.
- Białe księgi
Odnośniki do niektórych białych ksiąg z dogłębnymi szczegółami na temat strojenia GC.
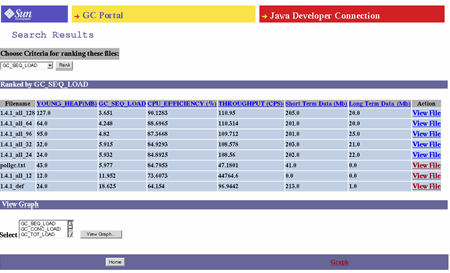
Rysunek 3. Migawka silnika Intelligence portalu GC Portal
Sesja i silnik pamięci masowej
- Zarządzanie sesjami użytkowników
- Zarządzanie i przechowywanie profili użytkowników
- Zarządzanie i bezpieczne przechowywanie danych/logów użytkowników
- Udostępnianie logów użytkowników/danych do przeglądania referencyjnego i modelowania empirycznego
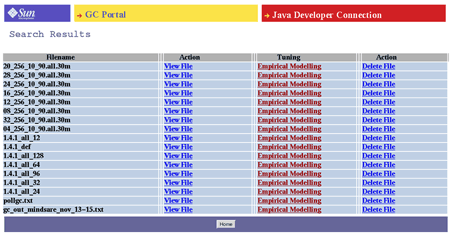
Rysunek 4. Snapshot of the Storage Engine of the GC Portal
VisualGC
Narzędzie visualgc podłącza się do oprzyrządowanej maszyny JVM HotSpot i zbiera oraz wyświetla graficznie dane dotyczące wydajności zbierania śmieci, programu ładującego klasy i kompilatora HotSpot. Jest ono włączone do GC Portal w celu zbierania informacji związanych z GC w czasie działania JVM. GC Portal używa narzędzia webstart do uruchamiania i wyświetlania informacji o GC w przeglądarce. Więcej szczegółów na temat tego narzędzia jest dostępnych na stronie CoolStuff – jvmstat. Plik ReadMe do uruchomienia VisualGC z poziomu GC Portal jest wbudowany w oprogramowanie GC Portal.
Podziękowania:
Autor chciałby podziękować Mayank Srivastava, Nagendra Nagarajayya, Nandula Narasimham i S.R.Venkatramanan za ich wkład w GC Portal. Autor chciałby również podziękować architektom Sun JVM garbage collection i ekspertom: John Coomes, David Detlefs, Steve Heller, Peter Kessler, Ross Knippel, Jon Masamitsu, James Mcilree i Y.S. Ramakrishna za ich pomoc i wskazówki dotyczące tej pracy. Autor chciałby również podziękować członkom zespołu ds. wydajności JVM firmy Sun, Timothy’emu Cramerowi i Brianowi Doherty’emu (autorowi narzędzi VisualGC i jvmstat) za ich pomoc w integracji VisualGC z GC Portal.
O autorze:
Alka Gupta jest członkiem personelu technicznego w Sun Microsystems. Jest odpowiedzialna za współpracę z firmami ISV i partnerami firmy Sun, aby pomóc im w szybkim i efektywnym wdrażaniu nowych technologii i platform Sun. Zajmuje się tuningiem wydajności na platformach Sun od prawie 7 lat, a z branżą związana jest od prawie 10 lat. Alka ukończyła Indian Institute of Technology (IIT) w Indiach.
Leave a Reply