Grid Search voor modelafstemming
Een modelhyperparameter is een eigenschap van een model die extern is aan het model en waarvan de waarde niet uit gegevens kan worden geschat. De waarde van de hyperparameter moet worden ingesteld voordat het leerproces begint. Bijvoorbeeld c in Support Vector Machines, k in k-Nearest Neighbors, het aantal verborgen lagen in Neurale Netwerken.
Een parameter daarentegen is een interne eigenschap van het model en de waarde ervan kan uit de gegevens worden geschat. Bijvoorbeeld bètacoëfficiënten van lineaire/logistische regressie of supportvectoren in Support Vector Machines.
Grid-search wordt gebruikt om de optimale hyperparameters van een model te vinden die de meest ‘accurate’ voorspellingen opleveren.
Laten we eens kijken naar Grid-Search door een classificatiemodel te bouwen op de dataset Borstkanker.
Importeer de dataset en bekijk de bovenste 10 rijen.
Uitvoer :

Elke rij in de dataset heeft één van de twee mogelijke klassen: goedaardig (weergegeven door 2) en kwaadaardig (weergegeven door 4). Ook zijn er 10 attributen in deze dataset (hierboven weergegeven) die zullen worden gebruikt voor voorspelling, behalve Sample Code Number, dat het id-nummer is.
Schoon de gegevens en hernoem de klassewaarden als 0/1 voor modelbouw (waarbij 1 staat voor een kwaadaardig geval). Laten we ook de verdeling van de klasse bekijken.
Uitvoer :

Er zijn 444 goedaardige en 239 kwaadaardige gevallen.
Uitvoer :
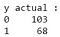
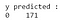
Uit de uitvoer kunnen we opmaken dat er 68 kwaadaardige en 103 goedaardige gevallen in de testdataset zijn. Onze classificator voorspelt echter alle gevallen als goedaardig (aangezien dit de meerderheidsklasse is).
Bereken de evaluatiemetriek van dit model.
Uitvoer :
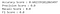

De nauwkeurigheid van het model is 60.2%, maar dit is een geval waarin nauwkeurigheid misschien niet de beste maatstaf is om het model te evalueren. Laten we dus eens kijken naar de andere evaluatiemetrieken.

De bovenstaande figuur is de verwarringsmatrix, met labels en kleuren toegevoegd voor een betere intuïtie (Code om dit te genereren vindt u hier). Om de verwarringsmatrix samen te vatten : WARE POSITIEVEN (TP)= 0, WARE NEGATIEVEN (TN)= 103, VALS POSITIEVEN (FP)= 0, VALS NEGATIEVEN (FN)= 68. De formules voor de evaluatiemetrieken zijn als volgt :

Omdat het model geen enkel kwaadaardig geval correct classificeert, zijn de recall- en precisiemetriek 0.
Nu we de basisnauwkeurigheid hebben, bouwen we een logistisch regressiemodel met standaardparameters en evalueren we het model.
Output :

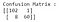
Door het logistische regressiemodel met de standaardparameters uit te voeren, hebben we een veel ‘beter’ model. De nauwkeurigheid is 94,7% en tegelijkertijd is de precisie een verbluffende 98,3%. Laten we nu eens kijken naar de verwarringsmatrix voor de resultaten van dit model :

Kijken we naar de verkeerd geclassificeerde gevallen, dan zien we dat 8 kwaadaardige gevallen ten onrechte als goedaardig zijn geclassificeerd (fout-negatieven). Ook is slechts één goedaardig geval als kwaadaardig geclassificeerd (vals-positief).
Een vals-negatief is ernstiger, aangezien een ziekte is genegeerd, wat tot de dood van de patiënt kan leiden. Tegelijkertijd zou een vals-positief leiden tot een onnodige behandeling – wat extra kosten met zich meebrengt.
Laten we proberen de vals-negatieven te minimaliseren door gebruik te maken van Grid Search om de optimale parameters te vinden. Grid search kan worden gebruikt om elke specifieke evaluatiemethode te verbeteren.
De methode waarop we ons moeten concentreren om fout-negatieve resultaten te beperken, is Recall.
Raster zoeken om Recall te maximaliseren
Uitvoer :


De hyperparameters die we hebben afgesteld zijn:
- Straf: l1 of l2 welke soort de norm gebruikt in de bestraffing.
- C: Inverse van de sterkte van de regularisatie – kleinere waarden van C geven een sterkere regularisatie aan.
Ook hebben we in de Grid-search-functie de scoringsparameter waar we de metriek kunnen opgeven waarop het model moet worden geëvalueerd (Wij hebben recall als metriek gekozen). Uit de onderstaande verwarringsmatrix blijkt dat het aantal fout-negatieven is gedaald, maar dat dit ten koste gaat van het aantal fout-positieven. De recall na rasterzoeken is van 88,2% naar 91,1% gesprongen, terwijl de precisie van 98,3% naar 87,3% is gedaald.

U kunt het model verder afstemmen om een evenwicht te vinden tussen precisie en recall door de ‘f1’-score als evaluatiemethode te gebruiken. Bekijk dit artikel voor een beter begrip van de evaluatiemetrieken.
Grid search bouwt een model voor elke combinatie van opgegeven hyperparameters en evalueert elk model. Een efficiëntere techniek voor het afstemmen van hyperparameters is de Randomized search – waarbij willekeurige combinaties van de hyperparameters worden gebruikt om de beste oplossing te vinden.
Leave a Reply