Data Masking
Wat is Data Masking?
Data Masking is een manier om een nep, maar een realistische versie van uw organisatorische data te creëren. Het doel is om gevoelige gegevens te beschermen en tegelijkertijd een functioneel alternatief te bieden wanneer de echte gegevens niet nodig zijn, bijvoorbeeld bij gebruikerstrainingen, verkoopdemo’s of het testen van software.
Data masking-processen veranderen de waarden van de gegevens terwijl hetzelfde formaat wordt gebruikt. Het doel is een versie te maken die niet kan worden ontcijferd of omgekeerd gemanipuleerd. Er zijn verschillende manieren om de gegevens te wijzigen, waaronder tekenherschikking, woord- of tekenvervanging en encryptie.
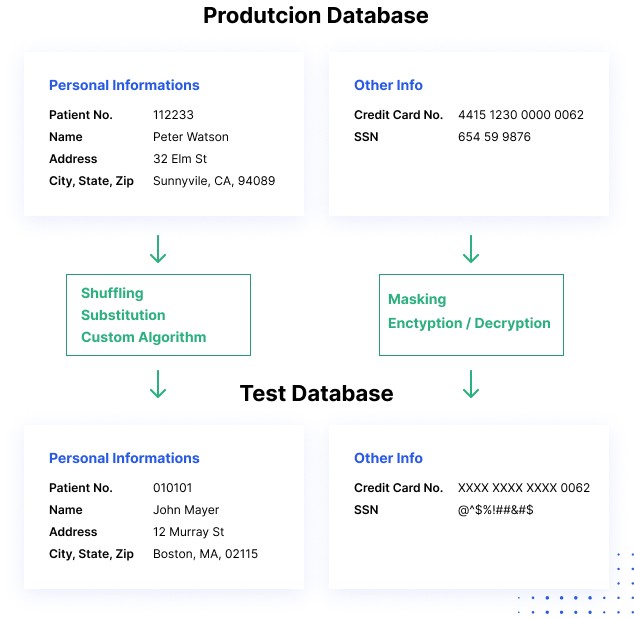
Hoe data masking werkt
Waarom is data masking belangrijk?
Er zijn verschillende redenen waarom gegevensafscherming voor veel organisaties essentieel is:
- Gegevensafscherming biedt een oplossing voor verschillende kritieke bedreigingen – verlies van gegevens, exfiltratie van gegevens, insiderbedreigingen of aantasting van accounts, en onveilige interfaces met systemen van derden.
- Vermindert de gegevensrisico’s die gepaard gaan met de overstap naar de cloud.
- Maakt gegevens onbruikbaar voor een aanvaller, met behoud van veel van de inherente functionele eigenschappen.
- Maakt het mogelijk gegevens te delen met geautoriseerde gebruikers, zoals testers en ontwikkelaars, zonder de productiegegevens bloot te stellen.
- Kan worden gebruikt voor gegevensopschoning – normale bestandsverwijdering laat nog steeds sporen van gegevens achter op opslagmedia, terwijl sanitization de oude waarden vervangt door gemaskeerde waarden.
Data Masking Types
Er zijn verschillende soorten data masking types die gewoonlijk worden gebruikt om gevoelige gegevens te beveiligen.
Static Data Masking
Static data masking processen kunnen u helpen een gezuiverde kopie van de database te maken. Het proces wijzigt alle gevoelige gegevens totdat een kopie van de database veilig kan worden gedeeld. Typisch bestaat het proces uit het maken van een reservekopie van een database in productie, het laden ervan naar een afzonderlijke omgeving, het elimineren van alle onnodige gegevens, en vervolgens het maskeren van gegevens terwijl het in stasis is. De gemaskeerde kopie kan dan naar de doellocatie worden geduwd.
Deterministic Data Masking
Het gaat om het in kaart brengen van twee reeksen gegevens met hetzelfde gegevenstype, zodanig dat de ene waarde altijd wordt vervangen door een andere waarde. Bijvoorbeeld, de naam “John Smith” wordt altijd vervangen door “Jim Jameson”, overal waar hij in een database voorkomt. Deze methode is handig voor veel scenario’s, maar is inherent minder veilig.
On-the-Fly Data Masking
Het afschermen van gegevens terwijl deze worden overgebracht van productiesystemen naar test- of ontwikkelingssystemen, voordat de gegevens op schijf worden opgeslagen. Organisaties die regelmatig software implementeren, kunnen geen reservekopie van de brondatabase maken en maskering toepassen – ze hebben een manier nodig om gegevens continu van productie naar meerdere testomgevingen te streamen.
On-the-fly, maskering stuurt kleinere subsets van afgeschermde gegevens wanneer deze nodig zijn. Elke subset van afgeschermde gegevens wordt opgeslagen in de dev/testomgeving voor gebruik door het niet-productiesysteem.
Het is belangrijk om on-the-fly maskering toe te passen op elke feed van een productiesysteem naar een ontwikkelomgeving, helemaal aan het begin van een ontwikkelingsproject, om compliance- en veiligheidsproblemen te voorkomen.
Dynamic Data Masking
Gelijk aan on-the-fly maskering, maar de gegevens worden nooit opgeslagen in een secundaire gegevensopslag in de dev/testomgeving. In plaats daarvan worden ze rechtstreeks vanuit het productiesysteem gestreamd en door een ander systeem in de dev-/testomgeving gebruikt.
Technieken voor data-afscherming
Laten we eens kijken naar een paar veelgebruikte manieren waarop organisaties afscherming toepassen op gevoelige gegevens. Bij het beschermen van gegevens kunnen IT-professionals verschillende technieken gebruiken.
Gegevensversleuteling
Wanneer gegevens worden versleuteld, worden ze onbruikbaar tenzij de kijker de ontsleutelingssleutel heeft. In wezen worden de gegevens gemaskeerd door het encryptie-algoritme. Dit is de veiligste vorm van data-afscherming, maar ook complex om te implementeren omdat het een technologie vereist om doorlopende data-encryptie uit te voeren, en mechanismen om encryptiesleutels te beheren en te delen
Data Scrambling
Carakters worden in willekeurige volgorde gereorganiseerd, waarbij de oorspronkelijke inhoud wordt vervangen. Bijvoorbeeld, een ID nummer zoals 76498 in een productie database, kan worden vervangen door 84967 in een test database. Deze methode is zeer eenvoudig te implementeren, maar kan slechts op enkele soorten gegevens worden toegepast, en is minder veilig.
Nulling Out
Gegevens lijken te ontbreken of “null” wanneer ze door een onbevoegde gebruiker worden bekeken. Dit maakt de gegevens minder bruikbaar voor ontwikkelings- en testdoeleinden.
Value Variance
Originele gegevenswaarden worden vervangen door een functie, zoals het verschil tussen de laagste en de hoogste waarde in een reeks. Als een klant bijvoorbeeld verschillende producten heeft gekocht, kan de aankoopprijs worden vervangen door een reeks tussen de hoogste en de laagste betaalde prijs. Dit kan nuttige gegevens opleveren voor vele doeleinden, zonder dat de oorspronkelijke dataset wordt onthuld.
Data Substitution
Gegevenswaarden worden gesubstitueerd door valse, maar realistische, alternatieve waarden. Bijvoorbeeld, echte klantnamen worden vervangen door een willekeurige selectie van namen uit een telefoonboek.
Data Shuffling
Gelijk aan substitutie, behalve dat gegevenswaarden binnen dezelfde dataset worden verwisseld. De gegevens worden in elke kolom opnieuw gerangschikt met behulp van een willekeurige volgorde; bijvoorbeeld het verwisselen van echte klantnamen in meerdere klantrecords. De outputset lijkt op echte gegevens, maar toont niet de echte informatie voor elk individu of gegevensrecord.
Pseudonimisering
Volgens de Algemene Verordening Gegevensbescherming (GDPR) van de EU is een nieuwe term geïntroduceerd voor processen zoals het afschermen van gegevens, versleuteling en hashing om persoonsgegevens te beschermen: pseudonimisering.
Pseudonimisering, zoals gedefinieerd in de GDPR, is elke methode die ervoor zorgt dat gegevens niet kunnen worden gebruikt voor persoonlijke identificatie. Het vereist het verwijderen van directe identificatoren, en, bij voorkeur, het vermijden van meerdere identificatoren die, wanneer gecombineerd, een persoon kunnen identificeren.
Daarnaast moeten encryptiesleutels, of andere gegevens die kunnen worden gebruikt om terug te keren naar de oorspronkelijke gegevenswaarden, afzonderlijk en veilig worden opgeslagen.
Data Masking Best Practices
Bepaal de Project Scope
Om data masking effectief te kunnen uitvoeren, moeten bedrijven weten welke informatie beschermd moet worden, wie geautoriseerd is om deze te zien, welke applicaties de gegevens gebruiken, en waar deze zich bevinden, zowel in productie- als niet-productiedomeinen. Hoewel dit op papier eenvoudig lijkt, kan dit proces door de complexiteit van de activiteiten en meerdere bedrijfsonderdelen een aanzienlijke inspanning vergen en moet het als een afzonderlijke fase van het project worden gepland.
Zorg voor referentiële integriteit
Referentiële integriteit betekent dat elk “type” informatie afkomstig van een bedrijfsapplicatie moet worden afgeschermd met behulp van hetzelfde algoritme.
In grote organisaties is een enkele tool voor gegevensafscherming die in de hele onderneming wordt gebruikt, niet haalbaar. Elk bedrijfsonderdeel kan worden verplicht zijn eigen gegevensafscherming te implementeren als gevolg van budget-/bedrijfsvereisten, verschillende IT-beheerpraktijken of verschillende veiligheids-/regelgevingsvereisten.
Zorg ervoor dat verschillende gegevensafschermingstools en -praktijken in de hele organisatie worden gesynchroniseerd, wanneer het gaat om hetzelfde type gegevens. Dit voorkomt problemen later wanneer gegevens moeten worden gebruikt over business lines heen.
Beveilig de data-afschermingsalgoritmen
Het is van cruciaal belang om te overwegen hoe de data-afschermingsalgoritmen moeten worden beschermd, evenals alternatieve datasets of woordenboeken die worden gebruikt om de data te versleutelen. Omdat alleen geautoriseerde gebruikers toegang mogen hebben tot de echte gegevens, moeten deze algoritmen als uiterst gevoelig worden beschouwd. Als iemand te weten komt welke herhaalbare maskeeralgoritmen worden gebruikt, kan hij grote blokken gevoelige informatie reverse-engineeren.
Een best practice voor het maskeren van gegevens, die door sommige voorschriften uitdrukkelijk wordt voorgeschreven, is het zorgen voor scheiding van taken. Het IT-beveiligingspersoneel bepaalt bijvoorbeeld welke methoden en algoritmen in het algemeen zullen worden gebruikt, maar specifieke algoritme-instellingen en datalijsten mogen alleen toegankelijk zijn voor de eigenaren van de gegevens op de desbetreffende afdeling.
Gegevensafscherming met Imperva
Imperva is een beveiligingsoplossing die mogelijkheden biedt voor gegevensafscherming en -versleuteling, waarmee u gevoelige gegevens kunt versluieren zodat deze onbruikbaar zijn voor een aanvaller, zelfs als ze op de een of andere manier worden onttrokken.
Naast gegevensafscherming beschermt Imperva’s oplossing voor gegevensbeveiliging uw gegevens, ongeacht waar deze zich bevinden: ter plaatse, in de cloud en in hybride omgevingen. Het biedt beveiligings- en IT-teams ook volledig inzicht in hoe de gegevens worden benaderd, gebruikt en verplaatst binnen de organisatie.
Onze uitgebreide aanpak berust op meerdere beschermingslagen, waaronder:
- Database firewall-blokkeert SQL-injectie en andere bedreigingen, terwijl het evalueert op bekende kwetsbaarheden.
- Gebruikersrechtenbeheer: bewaakt de gegevenstoegang en activiteiten van bevoorrechte gebruikers om buitensporige, ongepaste en ongebruikte rechten te identificeren.
- Gegevensverliespreventie (DLP)-inspecteert gegevens in beweging, in rust op servers, in cloud-opslag of op endpoint-apparaten.
- Analyse van gebruikersgedrag – stelt basislijnen vast voor het gedrag bij gegevenstoegang, maakt gebruik van machine learning om abnormale en potentieel riskante activiteiten te detecteren en hiervoor te waarschuwen.
- Gegevensontdekking en -classificatie – onthult de locatie, het volume en de context van gegevens op locatie en in de cloud.
- Monitoring van database-activiteiten-monitort relationele databases, datawarehouses, big data en mainframes om real-time waarschuwingen te genereren over schendingen van het beleid.
- Prioritering van waarschuwingen-Imperva gebruikt AI- en machine learning-technologie om door de stroom van beveiligingsgebeurtenissen te kijken en prioriteit te geven aan de gebeurtenissen die er het meest toe doen.
Leave a Reply