Grid Search for model tuning
モデルの超変数とは、モデルの外部にあってデータからその値を推定することができない特性である。 ハイパーパラメータの値は、学習プロセスを開始する前に設定されなければならない。 例えば、サポートベクターマシンの c、k-Nearest Neighbors の k、Neural Networks の隠れ層の数など。
これに対して、パラメータはモデルの内部特性で、その値はデータから推定することができる。 例:線形/ロジスティック回帰のベータ係数、サポートベクターマシンのサポートベクター。
Grid-search is used to find the optimal hyperparameters of a model which results in the most ‘accurate’ predictions.
データセットをインポートして、上位10行を表示します。
Output :
![]()
データセット内の各行には、良性(2で表現)と悪性(4で表現)という、考えられる2クラスのいずれかが存在します。 また、このデータセットには、ID番号であるサンプルコード番号を除いて、予測に使用される10の属性があります(上図)。
データをきれいにして、モデル構築のためにクラス値を0/1にリネームします(ここで1は悪性ケースを表します)。
Output :
![]()
良性444件、悪性239件であることがわかる。
アウトプット:
![]()
![]()
出力から、テストデータセットでは68悪性と103良性のケースがあることが観察されました。 しかし、我々の分類器はすべてのケースを良性と予測します(それが大多数のクラスであるため)。
このモデルの評価指標を計算します。
Output :
![]()
![]()
モデルの精度は60.となりました。2%ですが、これは精度がモデルを評価するのに最適な指標でない可能性があるケースです。
![]()
上の図は混乱行列で、より直感的にわかるようにラベルと色を付けてあります(これを生成するコードはこちらでご覧になれます)。 混同行列を要約すると 真陽性(tp)= 0,true negatives (tn)= 103,false positives (fp)= 0,false negatives (fn)= 68.である。 評価指標の式は以下の通り:
![]()
モデルは悪性ケースを正しく分類しないため、再現率と精度指標は0である。
ベースラインの精度がわかったので、デフォルトのパラメータでロジスティック回帰モデルを構築し、モデルを評価しましょう。
Output :
![]()
![]()
Logistic Regression モデルとデフォルト・パラメーターをフィットすると、ずっと「よい」モデルになったことが確認できます。 精度は 94.7% で、同時に精度も 98.3% という驚異的な数値になっています。
![]()
誤分類したインスタンスを見てみると、8件の悪性ケースが良性として誤って分類されたことがわかります (False negatives). また、わずか 1 つの良性ケースが悪性に分類されました (偽陽性)。
偽陰性は、疾患が無視されたためより深刻であり、患者の死亡につながる可能性があります。 同時に、偽陽性は不必要な治療、つまり追加費用の発生につながります。
グリッドサーチを使用して最適なパラメータを見つけることにより、偽陰性を最小限にすることを試みます。 グリッド検索は、特定の評価指標を改善するために使用できます。
偽陰性を減らすために注目すべき評価指標は、再現率です。
Grid Search to maximize Recall
Output :
![]()
![]()
チューニングした超パラメインターは、以下の通りです。
- Penalty: l1 or l2 which species the norm used in the penalization.これは、ペナルティーに使われるノルムの種類です。
- C: 正則化の強さの逆数で、Cの値が小さいほど強い正則化になります。
また、Grid-search関数では、モデルを評価する指標を指定できるscoreパラメータを持っています(指標はrecallとしました)。 以下の混同行列から、偽陰性の数は減少していることがわかりますが、その代償として偽陽性が増加しています。 グリッド検索後のリコールは 88.2% から 91.1% に跳ね上がり、一方、精度は 98.3% から 87.3% に下がっています。
![]()
さらにモデルを調整して精度とリコールのバランスを取るためには、「f1」スコアを評価指標として使用すれば良いのです。 評価メトリックのより良い理解については、この記事をチェックしてください。
グリッド検索は、指定されたハイパーパラメータのすべての組み合わせについてモデルを構築し、各モデルを評価する。 ハイパーパラメーター調整のより効率的な手法はランダム化探索で、ハイパーパラメーターのランダムな組み合わせを使用して最適な解を見つけます。


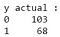
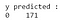




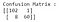




Leave a Reply