Gaussian kernels
プライバシー & Cookies
このサイトではクッキーを使用しております。 続行することで、その使用に同意したことになります。 Cookieを制御する方法など、詳細はこちら
ガウスカーネルについてきちんと紹介するために、今週の記事はいつもより少し抽象的に始めるつもりです。 この抽象化のレベルは、ガウス カーネルの仕組みを理解するのに厳密には必要ではありませんが、抽象的な視点は、一般的な確率分布を理解しようとするときの直感の源として非常に役に立ちます。 これから徐々に抽象度を上げていきますが,もし絶望的に分からなくなったり,これ以上我慢できなくなったりしたら,太字で「実用編」と書いてある見出しまで読み飛ばしていただいて構いません。 また、まだ問題がある場合でも、あまり心配しないでください。このブログの後の記事のほとんどは、ガウス カーネルを理解する必要はありませんので、来週の記事を待ってください(あるいは、後でこれを読む場合はスキップしてください)。
カーネルとは、データ空間と高次元空間の超平面との交点がデータ空間のより複雑で曲線状の決定境界を決定できるよう、データ空間をより高次元のベクトル空間に置く方法であると思い起こしましょう。 主な例として、座標


今週は高次元ベクトル空間を越えて、無限次元ベクトル空間まで踏み込みましょう。 上の 9 次元カーネルが 5 次元カーネルの延長であることがわかると思いますが、基本的には最後に 4 次元を追加しただけです。 このように次元をどんどん増やしていくと、どんどん高次元のカーネルになっていきます。 これを「永遠に」続けると、無限に多くの次元を持つことになる。 ただし、これは抽象的な話である。 コンピュータは有限のものしか扱えないので、無限次元のベクトル空間に計算を保存したり処理したりすることはできないのだ。 しかし、ちょっとだけ、何が起こるか見るために、できるふりをすることにしよう。
この仮想の無限次元ベクトル空間では、通常のベクトルと同じように、対応する座標を足すだけでベクトルを足すことができる。 ただし、この場合は無限に座標を足さなければならない。 同様に、スカラーの乗算も、(無限にある)座標にそれぞれ与えられた数を掛けることで可能です。 各点




計算機の世界に戻るために、エントリの最初の5つ以外は忘れて、元の5次元カーネルを回復することができます。 実は、この無限次元空間の中に、元の5次元空間が含まれているのである。 (元の5次元カーネルとは、この5次元空間に無限多項式カーネルを射影して得られるものです。)
さて、深呼吸をしてください、これをもう一歩進めます。 ベクトルとは何か、ちょっと考えてみてください。 数学の線形代数の授業を受けたことがある人は覚えているかもしれませんが、ベクトルは公式には足し算と掛け算の性質で定義されています。 計算機の世界では、ベクトルは数字の羅列と考えるのが一般的です。 ここまで読まれた方は、そのリストが無限大になっても構わないと思っているかもしれません。 しかし、ベクトルとは、それぞれの数字が特定のものに割り当てられている数字の集まりだと考えて欲しいのです。 例えば、通常のベクトルでは、各数値は座標/特徴の1つに割り当てられています。 私たちの無限ベクトルの1つでは、各数値は私たちの無限に長いリストのスポットに割り当てられています。
しかし、これはどうでしょう。 もし、私たちの (有限次元の) データ空間の各ポイントに番号を割り当ててベクトルを定義したらどうなるのでしょうか。 このようなベクトルは、データ空間内の 1 つの点を選ぶのではなく、一度このベクトルを選ぶと、データ空間内の任意の点を指すと、ベクトルは数字を教えてくれるのです。 まあ、実はもう名前がついているんですけどね。 データ空間の各点に数値を割り当てるものを関数といいます。 実際、このブログでも、確率分布を定義する密度関数という形で、関数を何度も取り上げてきました。 しかし、ポイントは、これらの密度関数を無限次元のベクトル空間のベクトルと考えることができる点です。 さて、2つの関数は各点での値を足すだけで足し算ができます。 これは、先週の混合モデルの投稿で、分布を結合するための最初のスキームを説明したものです。 2つのベクトル(ガウスの塊)の密度関数と、それらを足した結果を下の図に示します。 同じように関数に数値を掛けると、全体の密度が薄くなったり濃くなったりします。 実は、この2つの操作は、代数学の授業や微積分でたくさん練習したはずのものです。 9186>

次のステップは、元のデータ空間からこの無限次元空間へのカーネルを定義することですが、ここで私たちは多くの選択肢を持っています。 最も一般的な選択肢の 1 つは、過去の投稿で何度か見てきたガウス blob 関数です。 このカーネルでは、ガウスブロブの標準サイズ、すなわち、偏差
有限次元のベクトルでは、投影を定義する最も一般的な方法は、ドットプロダクトを使用することです。 これは2つのベクトルの対応する座標を掛け合わせ、それらをすべて足した数です。 例えば、3次元ベクトル


関数の場合も同様に、データセット中の該当する点に取る値を掛け合わせれば良いのである。 (しかし、これらの数値は無限にあるので、すべてを足し合わせることはできない。 そこで、積分をとることになります。 (数学者の方には申し訳ないのですが……)。 ここで良いのは、2つのガウス関数を掛け合わせて積分すると、中心点間の距離のガウス関数と同じ数になることです。 (ただし、新しいガウス関数は偏差値が異なります。)
つまり、ガウスカーネルは無限次元空間の内積をデータ空間の点間距離のガウス関数に変換するのです。 データ空間の2点が近ければ、カーネル空間でそれらを表すベクトル間の角度は小さくなります。 データ空間の2点が近ければ、カーネル空間でそれらを表すベクトル間の角度は小さくなります。点が離れていれば、対応するベクトルは「垂直」に近くなります。 
このカーネルの働きをよりよく理解するために、超平面のデータ空間との交点がどのようなものか考えてみましょう。 (これはカーネルで最もよく行われることです。ここで 

これを解くのはまだ難しいので、値 
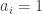

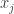




パラメータ
そのため、決定境界をより柔軟に選択できますが (あるいは、少なくとも異なる種類の柔軟性)、最終結果は選択する
このような点の集まりを見つけることは、このブログのこれまでの投稿で焦点を当ててきたものとは非常に異なる問題で、教師なし学習/記述的分析のカテゴリに属します。 (カーネルの文脈では、特徴選択/エンジニアリングと考えることもできます)。 次の記事では、ギアを切り替えて、この線に沿ってアイデアを探求し始めます。
Leave a Reply