背景 Generative Modelとは?
Generative Adversarial Network という名前の「Generative」とはどういう意味でしょうか。
参考までに、
- Generative モデルは新しいデータインスタンスを生成することができます。
生成モデルは実際の動物に似た動物の新しい写真を生成することができ、識別モデルは犬と猫を見分けることができる。 より正式には、データインスタンス X のセットとラベル Y のセットがある場合、
- 生成モデルは結合確率 p(X, Y)、またはラベルがない場合は単に p(X) を捕捉するものです。
- 判別モデルは条件付き確率 p(Y | X) を捕らえる。
生成モデルはデータ自体の分布を含み、与えられた例がどの程度の可能性があるかを教えてくれる。 たとえば、一連の単語の次の単語を予測するモデルは、単語のシーケンスに確率を割り当てることができるので、一般的に生成モデル(通常は GAN よりはるかに単純)です。
識別モデルは、与えられたインスタンスが可能性が高いかどうかという問題を無視し、ラベルがそのインスタンスに適用される可能性についてだけ指示します。 生成モデルには多くの種類がある。 GAN は生成モデルの 1 つに過ぎません。
確率のモデル化
どちらの種類のモデルも、確率を表す数値を返す必要はありません。 例えば、決定木のような識別分類器は、そのラベルに確率を割り当てることなく、インスタンスをラベル付けすることができます。 同様に、生成モデルは、その分布から描かれるように見える説得力のある「偽」のデータを生成することによって、分布をモデル化することができます。
画像の生成モデルは、「ボートのように見えるものは、おそらく水のように見えるものの近くに現れるだろう」、「目は額に現れることはまずない」といった相関を捉えるかもしれない。 これらは非常に複雑な分布である。
対照的に、識別モデルは、いくつかの物語パターンを探すだけで、「ヨット」または「ヨットではない」の違いを学ぶことができるかもしれない。 判別モデルがデータ空間に境界を引こうとするのに対して、生成モデルはデータが空間全体にどのように配置されるかをモデル化しようとする。 たとえば、次の図は、手書き数字の識別モデルと生成モデルを示しています。
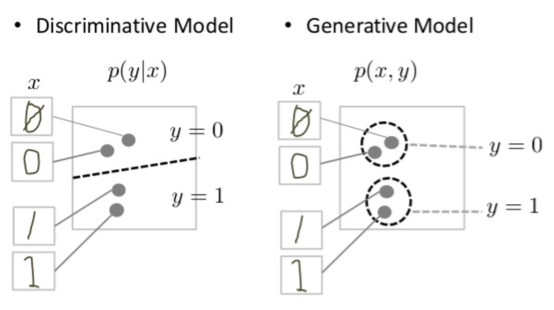
図1:手書き数字の識別モデルと生成モデル
識別モデルはデータ空間に線を引き、手書きの0と1の違いを識別しようとするもので、手書きの0と1、手書きの0と1、手書きの0と1の違いを識別する。 その線が正しければ、その線の両側のデータ空間に配置される実体を正確にモデル化することなく、0と1を区別できる。
対照的に、生成モデルはデータ空間における実際の対応物に近い数字を生成することによって説得力のある1と0を生成しようとする。
GANは、実際の分布に類似するような豊富なモデルを訓練する効果的な方法を提供する。 GAN の仕組みを理解するには、GAN の基本構造を理解する必要があります。
Check Your Understanding: Generative vs. Discriminative Models
- 6面サイコロを3つ振る。
- 出目に定数wを掛ける。
- これを100回繰り返し、すべての結果の平均を取る。
手順の結果が実際のIQスコアの平均に等しくなるまでwの値をいろいろ変えてみる。 あなたのモデルは生成モデルですか、それとも識別モデルですか?
Leave a Reply