データ マスク
データ マスクとは何ですか
データ マスクとは、組織データの偽の、しかし現実的なバージョンを作成する方法です。 その目的は、機密データを保護する一方で、実際のデータが必要ない場合、たとえば、ユーザー トレーニング、販売デモ、ソフトウェア テストなどで、機能的な代替手段を提供することです。 その目的は、解読やリバースエンジニアリングが不可能なバージョンを作成することです。 データを変更するには、文字のシャッフル、単語または文字の置換、暗号化などいくつかの方法があります。
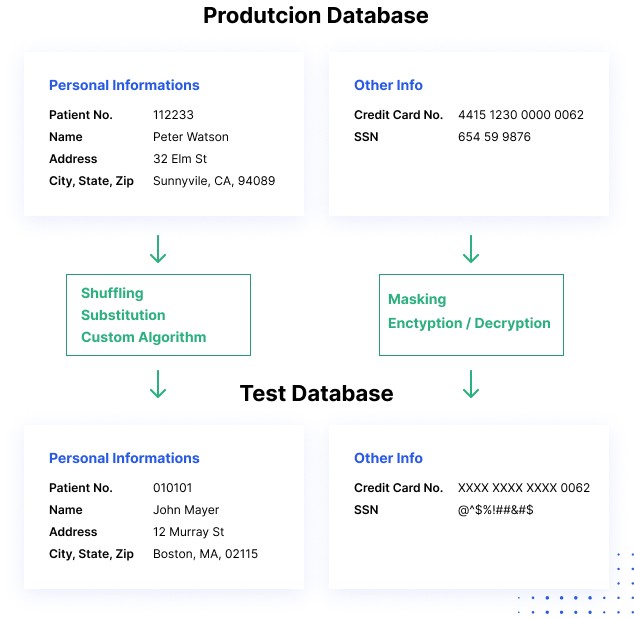
How data masking works
Why is Data Masking important?
- データマスキングは、データ損失、データ流出、内部脅威またはアカウントの侵害、サード パーティ製システムとの安全でないインターフェイスなど、いくつかの重要な脅威を解決します。
- 本番データを公開することなく、テスターや開発者などの正規ユーザーとのデータ共有を可能にします。
- データのサニタイズに使用できます。
Data Masking Types
一般的に機密データを保護するために使用されるデータマスキングのタイプはいくつかあります。
Static Data Masking
Static データマスキング処理により、データベースのサニタイズドコピーを作成することが可能です。 このプロセスでは、データベースのコピーを安全に共有できるようになるまで、すべての機密データを変更します。 通常、このプロセスでは、運用中のデータベースのバックアップ コピーを作成し、それを別の環境にロードして、不要なデータを削除し、静止している間にデータをマスキングします。
Deterministic Data Masking
1 つの値が常に別の値で置き換えられるように、同じタイプのデータを持つ 2 つのデータ セットをマッピングすることです。 たとえば、”John Smith” という名前は、データベース内のどの場所でも常に “Jim Jameson” に置き換えられます。 この方法は多くのシナリオで便利ですが、本質的に安全ではありません。
On-the-Fly Data Masking
データがディスクに保存される前に運用システムからテストまたは開発システムへ転送される間、データをマスキングすることです。 頻繁にソフトウェアを展開する組織では、ソース データベースのバックアップ コピーを作成してマスキングを適用することはできません。 マスキングされたデータの各サブセットは、非生産システムで使用するために開発/テスト環境に保存されます。
開発プロジェクトの最初の段階で、生産システムから開発環境へのすべてのフィードにオンザフライ マスキングを適用し、コンプライアンスおよびセキュリティ問題を防止することが重要です。
Data Masking Techniques
組織が機密データにマスキングを適用する一般的な方法をいくつか見ていきましょう。 データを保護する場合、IT プロフェッショナルはさまざまなテクニックを使用できます。
Data Encryption
データを暗号化すると、閲覧者が復号化キーを持っていない限り、データは役に立たなくなります。 本質的に、データは暗号化アルゴリズムによってマスクされます。 これは、データマスキングの最も安全な形式ですが、継続的にデータ暗号化を行う技術や、暗号化キーを管理および共有するメカニズムが必要なため、実装が複雑です
Data Scrambling
文字は、元のコンテンツに代わって、ランダムな順序で再編成されます。 例えば、本番用データベースでは76498のようなID番号でも、テスト用データベースでは84967に置き換えることができます。 この方法は実装が非常に簡単ですが、一部のタイプのデータにしか適用できず、安全性が低くなります。
Nulling Out
許可されていないユーザーが表示すると、データが欠けているか「null」であるように表示されます。
Value Variance
Original data values are replaced by a function, such as the difference between the lowest and highest values in a series.これは、開発およびテスト目的のためにデータをあまり有用でなくする。 たとえば、顧客が複数の製品を購入した場合、購入価格は、支払った最高値と最低値の間の範囲に置き換えることができます。
Data Substitution
Data values are substituted with fake, but realistic alternative values.これは、元のデータセットを開示することなく、多くの目的のために有用なデータを提供することができる。
データ・シャフリング
置換と似ているが、同じデータセット内でデータの値が入れ替わる。 例えば、複数の顧客レコードで実際の顧客名を入れ替えるなど、ランダムな順序でデータを各列で並べ替えます。
Pseudonymisation
EU 一般データ保護規則 (GDPR) によると、個人データを保護するためのデータマスキング、暗号化、ハッシュなどのプロセスをカバーする新しい用語として、仮名化が導入されました。 直接の識別子を削除し、できれば、組み合わせると個人を特定できる複数の識別子を避ける必要があります。
さらに、暗号化キー、または元のデータ値に戻すために使用できるその他のデータは、別途、安全に保管する必要があります。
データマスキングのベストプラクティス
プロジェクト範囲の決定
効果的にデータマスキングを行うために、企業は保護が必要な情報、それを見る権限がある人、どのアプリケーションがデータを使用するか、本番および非本番ドメインの両方においてどこにデータが存在するかを知っておく必要があります。
Ensure Referential Integrity
Referential Integrity とは、ビジネス アプリケーションから来る情報の各「タイプ」が、同じアルゴリズムを使用してマスクされる必要があることを意味します。 予算/ビジネス要件、異なるIT管理プラクティス、または異なるセキュリティ/規制要件により、各事業部門が独自のデータマスキングを実装する必要がある場合があります。
同じ種類のデータを扱う場合、組織全体で異なるデータマスキングツールとプラクティスを確実に同期させる。
Secure the Data Masking Algorithms
データ作成アルゴリズム、およびデータをスクランブルするために使用する代替データセットまたは辞書を保護する方法を検討することは非常に重要です。 許可されたユーザーのみが実際のデータにアクセスできる必要があるため、これらのアルゴリズムは非常に敏感であると考えるべきです。
Data Masking のベストプラクティスは、いくつかの規制で明示的に要求されていますが、職務の分離を確実にすることです。 たとえば、ITセキュリティ担当者はどのような方法とアルゴリズムを使用するかを一般的に決定しますが、特定のアルゴリズム設定とデータリストには、関連部署のデータ所有者だけがアクセスできるようにします。
Impervaによるデータマスキング
Imperva は、データマスキングと暗号化機能を提供するセキュリティソリューションで、機密データを難読化し、何らかの方法で抽出したとしても、攻撃者には無意味となるようにします。
当社の包括的なアプローチは、以下のような複数の保護レイヤーに依存しています。
Leave a Reply