Ricerca a griglia per il tuning del modello
Un iperparametro del modello è una caratteristica di un modello che è esterna al modello e il cui valore non può essere stimato dai dati. Il valore dell’iperparametro deve essere impostato prima che il processo di apprendimento inizi. Per esempio, c nelle Support Vector Machines, k nei k-Nearest Neighbors, il numero di strati nascosti nelle reti neurali.
Al contrario, un parametro è una caratteristica interna del modello e il suo valore può essere stimato dai dati. Esempio, i coefficienti beta della regressione lineare/logistica o i vettori di supporto nelle Support Vector Machines.
Grid-search è usato per trovare gli iperparametri ottimali di un modello che risulta nelle previsioni più ‘accurate’.
Guardiamo il Grid-Search costruendo un modello di classificazione sul dataset del cancro al seno.
Importa il dataset e visualizza le prime 10 righe.
Output :

Ogni riga del dataset ha una delle due possibili classi: benigna (rappresentata da 2) e maligna (rappresentata da 4). Inoltre, ci sono 10 attributi in questo set di dati (mostrato sopra) che saranno utilizzati per la predizione, tranne il numero di codice del campione che è il numero id.
Puliamo i dati e rinominiamo i valori delle classi come 0/1 per la costruzione del modello (dove 1 rappresenta un caso maligno). Inoltre, osserviamo la distribuzione della classe.
Output :

Ci sono 444 casi benigni e 239 maligni.
Output :
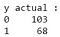
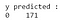
Dall’output, possiamo osservare che ci sono 68 casi maligni e 103 benigni nel dataset di test. Tuttavia, il nostro classificatore predice tutti i casi come benigni (in quanto è la classe di maggioranza).
Calcolare la metrica di valutazione di questo modello.
Output :

La precisione del modello è del 60.2%, ma questo è un caso in cui la precisione potrebbe non essere la migliore metrica per valutare il modello. Quindi, diamo un’occhiata alle altre metriche di valutazione.

La figura sopra è la matrice di confusione, con etichette e colori aggiunti per una migliore intuizione (il codice per generare questo può essere trovato qui). Per riassumere la matrice di confusione: VERI POSITIVI (TP)= 0,VERI NEGATIVI (TN)= 103,FALSI POSITIVI (FP)= 0, FALSI NEGATIVI (FN)= 68. Le formule per le metriche di valutazione sono le seguenti:

Poiché il modello non classifica correttamente nessun caso maligno, le metriche di richiamo e precisione sono 0.
Ora che abbiamo la precisione di base, costruiamo un modello di regressione logistica con parametri predefiniti e valutiamo il modello.
Output :

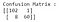
Applicando il modello di regressione logistica con i parametri di default, abbiamo un modello molto ‘migliore’. L’accuratezza è del 94,7% e allo stesso tempo, la precisione è uno sbalorditivo 98,3%. Ora, diamo un’occhiata di nuovo alla matrice di confusione per i risultati di questo modello :

Guardando le istanze mal classificate, possiamo osservare che 8 casi maligni sono stati classificati erroneamente come benigni (falsi negativi). Inoltre, un solo caso benigno è stato classificato come maligno (Falso positivo).
Un falso negativo è più grave perché una malattia è stata ignorata, il che può portare alla morte del paziente. Allo stesso tempo, un falso positivo porterebbe a un trattamento non necessario – sostenendo costi aggiuntivi.
Tentiamo di minimizzare i falsi negativi utilizzando la ricerca a griglia per trovare i parametri ottimali. La ricerca a griglia può essere usata per migliorare qualsiasi metrica di valutazione specifica.
La metrica su cui dobbiamo concentrarci per ridurre i falsi negativi è Recall.
Ricerca a griglia per massimizzare il Recall
Output :


Gli iperparametri che abbiamo accordato sono:
- Pena: l1 o l2 che è la norma usata nella penalizzazione.
- C: Inverso della forza di regolarizzazione – valori più piccoli di C specificano una regolarizzazione più forte.
Inoltre, nella funzione Grid-search, abbiamo il parametro scoring dove possiamo specificare la metrica su cui valutare il modello (abbiamo scelto recall come metrica). Dalla matrice di confusione qui sotto, possiamo vedere che il numero di falsi negativi si è ridotto, tuttavia, è al costo di un aumento dei falsi positivi. Il richiamo dopo la ricerca a griglia è balzato dall’88,2% al 91,1%, mentre la precisione è scesa all’87,3% dal 98,3%.

È possibile sintonizzare ulteriormente il modello per trovare un equilibrio tra precisione e richiamo utilizzando il punteggio ‘f1’ come metrica di valutazione. Controlla questo articolo per una migliore comprensione delle metriche di valutazione.
La ricerca a griglia costruisce un modello per ogni combinazione di iperparametri specificata e valuta ogni modello. Una tecnica più efficiente per la messa a punto degli iperparametri è la ricerca randomizzata – in cui vengono utilizzate combinazioni casuali degli iperparametri per trovare la soluzione migliore.
Cerca a griglia
Leave a Reply