Mascheramento dei dati
Che cos’è il mascheramento dei dati?
Il mascheramento dei dati è un modo per creare una versione falsa, ma realistica, dei vostri dati organizzativi. L’obiettivo è quello di proteggere i dati sensibili, fornendo allo stesso tempo un’alternativa funzionale quando i dati reali non sono necessari – per esempio, nella formazione degli utenti, nelle dimostrazioni di vendita o nei test del software.
I processi di mascheramento dei dati cambiano i valori dei dati pur utilizzando lo stesso formato. L’obiettivo è quello di creare una versione che non può essere decifrata o sottoposta a reverse engineering. Ci sono diversi modi per alterare i dati, incluso il rimescolamento dei caratteri, la sostituzione di parole o caratteri e la crittografia.
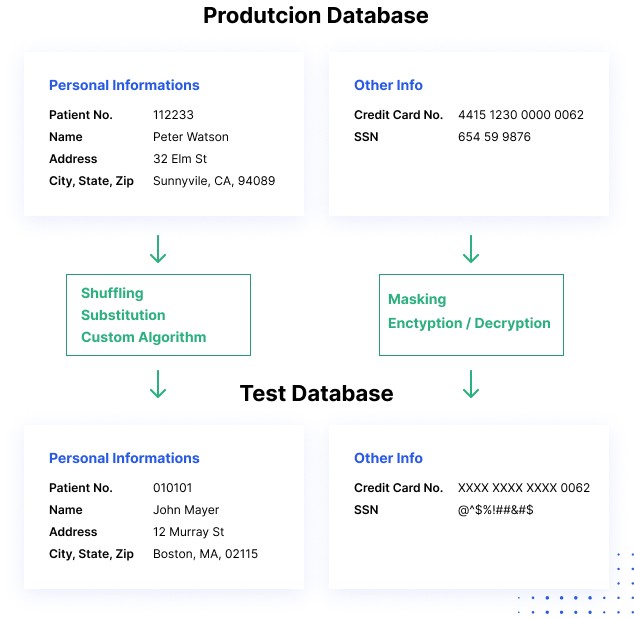
Come funziona il mascheramento dei dati
Perché il mascheramento dei dati è importante?
Qui ci sono diverse ragioni per cui il mascheramento dei dati è essenziale per molte organizzazioni:
- Il mascheramento dei dati risolve diverse minacce critiche – perdita di dati, esfiltrazione di dati, minacce interne o compromissione di account e interfacce insicure con sistemi di terze parti.
- Riduce i rischi di dati associati all’adozione del cloud.
- Rende i dati inutilizzabili per un attaccante, pur mantenendo molte delle sue proprietà funzionali intrinseche.
- Consente di condividere i dati con gli utenti autorizzati, come tester e sviluppatori, senza esporre i dati di produzione.
- Può essere utilizzato per la sanificazione dei dati – la normale eliminazione dei file lascia ancora tracce di dati nei supporti di archiviazione, mentre la sanificazione sostituisce i vecchi valori con quelli mascherati.
Tipi di mascheramento dei dati
Ci sono diversi tipi di mascheramento dei dati comunemente usati per proteggere i dati sensibili.
Mascheramento statico dei dati
I processi di mascheramento dei dati statici possono aiutarti a creare una copia sanificata del database. Il processo altera tutti i dati sensibili fino a quando una copia del database può essere condivisa in modo sicuro. Tipicamente, il processo comporta la creazione di una copia di backup di un database in produzione, il suo caricamento in un ambiente separato, l’eliminazione di tutti i dati non necessari, e poi il mascheramento dei dati mentre è in stasi. La copia mascherata può poi essere spinta nella posizione di destinazione.
Mascheramento deterministico dei dati
Si tratta di mappare due serie di dati che hanno lo stesso tipo di dati, in modo tale che un valore sia sempre sostituito da un altro valore. Per esempio, il nome “John Smith” è sempre sostituito con “Jim Jameson”, ovunque appaia in un database. Questo metodo è conveniente per molti scenari, ma è intrinsecamente meno sicuro.
Mascheramento dei dati al volo
Mascheramento dei dati mentre vengono trasferiti dai sistemi di produzione ai sistemi di test o sviluppo prima che i dati vengano salvati su disco. Le organizzazioni che distribuiscono frequentemente il software non possono creare una copia di backup del database di origine e applicare il mascheramento – hanno bisogno di un modo per trasferire continuamente i dati dalla produzione a più ambienti di test.
Al volo, il mascheramento invia piccoli sottoinsiemi di dati mascherati quando è richiesto. Ogni sottoinsieme di dati mascherati viene memorizzato nell’ambiente dev/test per essere utilizzato dal sistema non di produzione.
È importante applicare il mascheramento al volo a qualsiasi flusso da un sistema di produzione a un ambiente di sviluppo, proprio all’inizio di un progetto di sviluppo, per prevenire problemi di conformità e sicurezza.
Mascheramento dinamico dei dati
Simile al mascheramento al volo, ma i dati non vengono mai memorizzati in un archivio dati secondario nell’ambiente dev/test. Piuttosto, vengono trasmessi direttamente dal sistema di produzione e consumati da un altro sistema nell’ambiente dev/test.
Tecniche di mascheramento dei dati
Ripercorriamo alcuni modi comuni in cui le organizzazioni applicano il mascheramento ai dati sensibili. Quando si proteggono i dati, i professionisti IT possono usare una varietà di tecniche.
Crittografia dei dati
Quando i dati sono crittografati, diventano inutili a meno che l’utente non abbia la chiave di decrittazione. Essenzialmente, i dati sono mascherati dall’algoritmo di crittografia. Questa è la forma più sicura di mascheramento dei dati, ma è anche complessa da implementare perché richiede una tecnologia per eseguire la crittografia continua dei dati, e meccanismi per gestire e condividere le chiavi di crittografia
Data Scrambling
I caratteri sono riorganizzati in ordine casuale, sostituendo il contenuto originale. Per esempio, un numero ID come 76498 in un database di produzione, potrebbe essere sostituito da 84967 in un database di prova. Questo metodo è molto semplice da implementare, ma può essere applicato solo ad alcuni tipi di dati, ed è meno sicuro.
Nulling Out
I dati appaiono mancanti o “nulli” quando sono visti da un utente non autorizzato. Questo rende i dati meno utili per scopi di sviluppo e test.
Varianza del valore
I valori originali dei dati sono sostituiti da una funzione, come la differenza tra il valore più basso e quello più alto in una serie. Per esempio, se un cliente ha acquistato diversi prodotti, il prezzo di acquisto può essere sostituito con un intervallo tra il prezzo più alto e quello più basso pagato. Questo può fornire dati utili per molti scopi, senza rivelare la serie di dati originale.
Sostituzione dei dati
I valori dei dati vengono sostituiti con valori alternativi falsi, ma realistici. Per esempio, i nomi dei clienti reali sono sostituiti da una selezione casuale di nomi da un elenco telefonico.
Data Shuffling
Simile alla sostituzione, tranne che i valori dei dati sono scambiati all’interno dello stesso set di dati. I dati sono riordinati in ogni colonna usando una sequenza casuale; per esempio, cambiando i nomi dei clienti reali in più record di clienti. Il set di output assomiglia ai dati reali, ma non mostra le informazioni reali per ogni individuo o record di dati.
Pseudonimizzazione
Secondo il General Data Protection Regulation (GDPR) dell’UE, è stato introdotto un nuovo termine per coprire processi come il mascheramento dei dati, la crittografia e l’hashing per proteggere i dati personali: pseudonimizzazione.
La pseudonimizzazione, come definita nel GDPR, è qualsiasi metodo che garantisce che i dati non possano essere utilizzati per l’identificazione personale. Richiede la rimozione degli identificatori diretti e, preferibilmente, evitare identificatori multipli che, se combinati, possono identificare una persona.
Inoltre, le chiavi di crittografia, o altri dati che possono essere utilizzati per tornare ai valori originali dei dati, dovrebbero essere conservati separatamente e in modo sicuro.
Migliori pratiche di mascheramento dei dati
Determinare la portata del progetto
Per eseguire efficacemente il mascheramento dei dati, le aziende dovrebbero sapere quali informazioni devono essere protette, chi è autorizzato a vederle, quali applicazioni utilizzano i dati e dove risiedono, sia nei domini di produzione che in quelli non di produzione. Anche se questo può sembrare facile sulla carta, a causa della complessità delle operazioni e delle molteplici linee di business, questo processo può richiedere uno sforzo sostanziale e deve essere pianificato come una fase separata del progetto.
Assicurare l’integrità referenziale
Integrità referenziale significa che ogni “tipo” di informazione proveniente da un’applicazione aziendale deve essere mascherata utilizzando lo stesso algoritmo.
Nelle grandi organizzazioni, un singolo strumento di mascheramento dei dati utilizzato in tutta l’azienda non è fattibile. Ogni linea di business può essere obbligata a implementare il proprio mascheramento dei dati a causa di requisiti di budget/business, diverse pratiche di amministrazione IT o diversi requisiti di sicurezza/regolamentazione.
Assicuratevi che i diversi strumenti e pratiche di mascheramento dei dati nell’organizzazione siano sincronizzati, quando si tratta dello stesso tipo di dati. Questo eviterà problemi in seguito, quando i dati dovranno essere utilizzati tra le varie linee di business.
Proteggere gli algoritmi di mascheramento dei dati
È fondamentale considerare come proteggere gli algoritmi di creazione dei dati, così come i set di dati alternativi o i dizionari utilizzati per codificare i dati. Poiché solo gli utenti autorizzati dovrebbero avere accesso ai dati reali, questi algoritmi dovrebbero essere considerati estremamente sensibili. Se qualcuno viene a sapere quali algoritmi di mascheramento ripetibili vengono utilizzati, può eseguire il reverse engineering di grandi blocchi di informazioni sensibili.
Una buona pratica di mascheramento dei dati, che è esplicitamente richiesta da alcuni regolamenti, è quella di garantire la separazione dei compiti. Per esempio, il personale della sicurezza IT determina quali metodi e algoritmi saranno utilizzati in generale, ma le impostazioni specifiche dell’algoritmo e gli elenchi di dati dovrebbero essere accessibili solo ai proprietari dei dati nel dipartimento pertinente.
Mascheramento dei dati con Imperva
Imperva è una soluzione di sicurezza che fornisce funzionalità di mascheramento e crittografia dei dati, permettendoti di offuscare i dati sensibili in modo che siano inutili per un aggressore, anche se estratti in qualche modo.
Oltre a fornire il mascheramento dei dati, la soluzione di sicurezza dei dati di Imperva protegge i tuoi dati ovunque essi si trovino, in locale, nel cloud e in ambienti ibridi. Fornisce inoltre ai team di sicurezza e IT una visibilità completa su come i dati vengono acceduti, utilizzati e spostati all’interno dell’organizzazione.
Il nostro approccio completo si basa su più livelli di protezione, tra cui:
- Il firewall del database blocca l’iniezione SQL e altre minacce, mentre valuta le vulnerabilità note.
- Gestione dei diritti degli utenti: controlla l’accesso ai dati e le attività degli utenti privilegiati per identificare i privilegi eccessivi, inappropriati e inutilizzati.
- Prevenzione della perdita di dati (DLP): ispeziona i dati in movimento, a riposo sui server, nello storage in cloud o sui dispositivi endpoint.
- Analisi del comportamento degli utenti: stabilisce linee di base del comportamento di accesso ai dati, utilizza l’apprendimento automatico per rilevare e segnalare attività anomale e potenzialmente rischiose.
- Scoperta e classificazione dei dati: rivela la posizione, il volume e il contesto dei dati in sede e nel cloud.
- Monitoraggio dell’attività del database: monitora i database relazionali, i data warehouse, i big data e i mainframe per generare avvisi in tempo reale sulle violazioni delle policy.
- Priorità degli avvisi-Imperva utilizza la tecnologia AI e di apprendimento automatico per guardare attraverso il flusso di eventi di sicurezza e dare priorità a quelli più importanti.
Leave a Reply