Adatmaszkolás
Mi az adatmaszkolás?
Az adatmaszkolás a szervezeti adatok hamis, de valósághű változatának létrehozása. A cél az érzékeny adatok védelme, miközben funkcionális alternatívát nyújt, amikor nincs szükség valódi adatokra – például felhasználói képzés, értékesítési demók vagy szoftvertesztelés során.
Az adatmaszkírozási folyamatok megváltoztatják az adatok értékeit, miközben ugyanazt a formátumot használják. A cél egy olyan változat létrehozása, amelyet nem lehet megfejteni vagy visszafejteni. Az adatok megváltoztatásának számos módja van, többek között a karakterek keverése, a szavak vagy karakterek helyettesítése és a titkosítás.
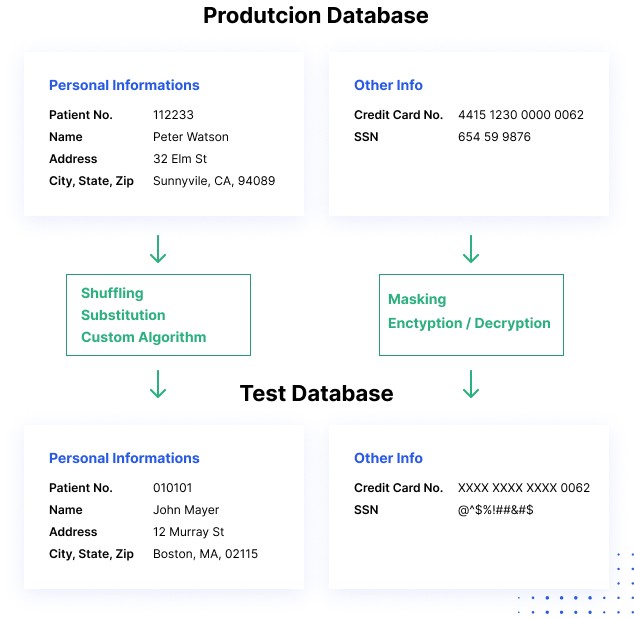
Hogyan működik az adatmaszkolás
Miért fontos az adatmaszkolás?
Az adatmaszkolás számos szervezet számára több okból is elengedhetetlen:
- Az adatmaszkolás számos kritikus fenyegetést old meg – adatvesztés, adatkiszivárgás, belső fenyegetések vagy fiókok kompromittálása, valamint a harmadik fél rendszereinek nem biztonságos interfészei.
- csökkenti a felhő bevezetésével járó adatkockázatokat.
- Az adatokat használhatatlanná teszi egy támadó számára, miközben számos eredendő funkcionális tulajdonságát megőrzi.
- Megosztja az adatokat a jogosult felhasználókkal, például tesztelőkkel és fejlesztőkkel, anélkül, hogy a termelési adatokat felfedné.
- Az adatok szanálására használható – a normál fájltörlés továbbra is hagy nyomokat az adatokról a tárolóeszközökön, míg a szanálás a régi értékeket maszkolt értékekkel helyettesíti.
Adatmaszkolás típusai
Az érzékeny adatok védelmére általánosan használt adatmaszkolás több típusa létezik.
Statikus adatmaszkolás
A statikus adatmaszkolási eljárások segítségével létrehozhatja az adatbázis szanált másolatát. A folyamat megváltoztatja az összes érzékeny adatot, amíg az adatbázis másolata biztonságosan megosztható. A folyamat jellemzően a termelésben lévő adatbázis biztonsági másolatának létrehozását, annak egy külön környezetbe való betöltését, a felesleges adatok eltávolítását, majd az adatok maszkolását foglalja magában, amíg azok stázisban vannak. A maszkolt másolat ezután a célhelyre tolható.
Determinisztikus adatmaszkolás
Két azonos típusú adathalmaz leképezését jelenti oly módon, hogy az egyik értéket mindig egy másik érték helyettesíti. Például a “John Smith” név helyébe mindig “Jim Jameson” lép, bárhol is jelenik meg az adatbázisban. Ez a módszer sok esetben kényelmes, de természeténél fogva kevésbé biztonságos.
Repülő adatmaszkolás
Az adatok maszkolása a termelési rendszerekből a teszt- vagy fejlesztőrendszerekbe történő átvitel során, mielőtt az adatokat lemezre mentik. Azok a szervezetek, amelyek gyakran telepítenek szoftvereket, nem tudnak biztonsági másolatot készíteni a forrásadatbázisról és alkalmazni a maszkolást – nekik módjuk van arra, hogy folyamatosan áramoltassák az adatokat a termelésből több tesztkörnyezetbe.
A maszkolás menet közben a maszkolt adatok kisebb részhalmazait küldi el, amikor szükség van rá. A maszkolt adatok minden egyes részhalmazát a fejlesztői/tesztkörnyezetben tárolják a nem termelési rendszer által történő felhasználásra.
A fejlesztési projekt legelején fontos, hogy a megfelelési és biztonsági problémák megelőzése érdekében menet közbeni maszkolást alkalmazzanak a termelési rendszerből a fejlesztési környezetbe történő minden adatátvitelre.
Dinamikus adatmaszkolás
A menet közbeni maszkoláshoz hasonló, de az adatokat soha nem tárolják a fejlesztési/tesztkörnyezet másodlagos adattárolójában. Inkább közvetlenül a termelési rendszerből áramolnak, és a dev/tesztkörnyezet egy másik rendszere fogyasztja őket.
Adatmaszkolási technikák
Tekintsünk át néhány gyakori módot, ahogyan a szervezetek az érzékeny adatok maszkolását alkalmazzák. Az adatok védelme során az informatikai szakemberek számos technikát alkalmazhatnak.
Adatok titkosítása
Amikor az adatokat titkosítják, azok használhatatlanná válnak, hacsak a megtekintő nem rendelkezik a visszafejtő kulccsal. Lényegében az adatokat a titkosítási algoritmus maszkolja. Ez az adatmaszkírozás legbiztonságosabb formája, de megvalósítása is bonyolult, mivel olyan technológiát igényel, amely folyamatos adattitkosítást végez, valamint mechanizmusokat a titkosítási kulcsok kezeléséhez és megosztásához
Adatok összekeverése
A karakterek véletlenszerű sorrendben átrendeződnek, és az eredeti tartalom helyébe lépnek. Például egy azonosítószám, például 76498 egy termelési adatbázisban, egy tesztadatbázisban 84967-re cserélhető. Ez a módszer nagyon egyszerűen megvalósítható, de csak bizonyos típusú adatokra alkalmazható, és kevésbé biztonságos.
Nulling Out
Az adat hiányzónak vagy “nullának” tűnik, ha egy illetéktelen felhasználó nézi. Ezáltal az adatok kevésbé használhatóak fejlesztési és tesztelési célokra.
Értékeltérés
Az eredeti adatértékek helyébe egy függvény lép, például egy sorozatban a legalacsonyabb és a legmagasabb érték közötti különbség. Ha például egy ügyfél több terméket vásárolt, a vételárat a legmagasabb és a legalacsonyabb kifizetett ár közötti tartományra lehet helyettesíteni. Ez számos célra hasznos adatokat szolgáltathat anélkül, hogy az eredeti adathalmaz nyilvánosságra kerülne.
Adatok helyettesítése
Az adatértékeket hamis, de reális alternatív értékekkel helyettesítjük. Például a valós vásárlói neveket egy telefonkönyvből véletlenszerűen kiválasztott nevekkel helyettesítik.
Adatok keverése
A helyettesítéshez hasonló, kivéve, hogy az adatértékeket ugyanazon az adathalmazon belül felcserélik. Az adatok átrendeződnek az egyes oszlopokban egy véletlenszerű sorrend alkalmazásával; például valódi vásárlói nevek közötti váltás több vásárlói rekordon keresztül. A kimeneti halmaz úgy néz ki, mint a valódi adatok, de nem mutatja az egyes személyek vagy adatrekordok valódi adatait.
Az álnevesítés
Az EU általános adatvédelmi rendelete (GDPR) szerint a személyes adatok védelme érdekében bevezetésre került egy új kifejezés, amely olyan folyamatokat takar, mint az adatmaszkolás, a titkosítás és a hashing: az álnevesítés.
A GDPR meghatározása szerint az álnevesítés minden olyan módszer, amely biztosítja, hogy az adatokat ne lehessen személyes azonosításra használni. Ehhez el kell távolítani a közvetlen azonosítókat, és lehetőleg el kell kerülni több olyan azonosítót, amelyek kombinálva azonosítani tudnak egy személyt.
A titkosítási kulcsokat vagy más olyan adatokat, amelyek felhasználhatók az eredeti adatértékek visszaállítására, külön és biztonságosan kell tárolni.
Az adatmaszkolás legjobb gyakorlatai
A projekt hatókörének meghatározása
Az adatmaszkolás hatékony elvégzéséhez a vállalatoknak tudniuk kell, hogy milyen információkat kell védeniük, kik jogosultak látni azokat, mely alkalmazások használják az adatokat, és hol találhatók a termelési és nem termelési tartományokban. Bár ez papíron könnyűnek tűnhet, a műveletek összetettsége és a több üzletág miatt ez a folyamat jelentős erőfeszítést igényelhet, és a projekt külön szakaszaként kell megtervezni.
Hivatkozási integritás biztosítása
A hivatkozási integritás azt jelenti, hogy az üzleti alkalmazásból érkező információk minden “típusát” ugyanazon algoritmus segítségével kell maszkolni.
A nagy szervezeteknél nem kivitelezhető egyetlen, az egész vállalatra kiterjedő adatmaszkoló eszköz használata. A költségvetés/üzleti követelmények, az eltérő informatikai adminisztrációs gyakorlatok vagy az eltérő biztonsági/szabályozási követelmények miatt minden üzletágnak saját adatmaszkolást kell végrehajtania.
Győződjön meg arról, hogy a különböző adatmaszkolási eszközök és gyakorlatok a szervezeten belül szinkronban vannak, amikor azonos típusú adatokkal foglalkoznak. Ez megelőzi a későbbi kihívásokat, amikor az adatokat az üzletágak között kell felhasználni.
Az adatmaszkoló algoritmusok védelme
Kritikusan fontos megfontolni, hogyan lehet megvédeni az adatokat készítő algoritmusokat, valamint az adatok titkosításához használt alternatív adatkészleteket vagy szótárakat. Mivel a valódi adatokhoz csak az arra jogosult felhasználóknak szabad hozzáférniük, ezeket az algoritmusokat rendkívül érzékenynek kell tekinteni. Ha valaki megtudja, hogy milyen megismételhető maszkoló algoritmusokat használnak, nagy mennyiségű érzékeny információtömböt tud visszafejteni.
Az adatmaszkolás legjobb gyakorlata, amelyet néhány szabályozás kifejezetten előír, a feladatok szétválasztásának biztosítása. Például az informatikai biztonsági személyzet határozza meg, hogy általában milyen módszereket és algoritmusokat használnak, de a konkrét algoritmusbeállításokhoz és adatlistákhoz csak az érintett részleg adattulajdonosai férhetnek hozzá.
Adatmaszkolás az Impervával
Az Imperva egy olyan biztonsági megoldás, amely adatmaszkolási és titkosítási képességeket biztosít, lehetővé téve az érzékeny adatok elhomályosítását, hogy azok egy támadó számára használhatatlanok legyenek, még akkor is, ha valahogyan kinyernék őket.
Az Imperva adatbiztonsági megoldása az adatmaszkolás mellett megvédi az adatokat, bárhol is legyenek azok – helyben, felhőben és hibrid környezetekben. Emellett a biztonsági és IT-csapatok számára teljes átláthatóságot biztosít arról, hogy az adatokat hogyan érik el, használják és mozgatják a szervezeten belül.
Az átfogó megközelítésünk a védelem több rétegére támaszkodik, többek között:
- Adatbázis tűzfal – blokkolja az SQL injekciót és más fenyegetéseket, miközben kiértékeli az ismert sebezhetőségeket.
- Felhasználói jogok kezelése – figyelemmel kíséri a kiváltságos felhasználók adathozzáférését és tevékenységeit a túlzott, nem megfelelő és nem használt jogosultságok azonosítása érdekében.
- Adatvesztés-megelőzés (DLP) – ellenőrzi a mozgásban lévő, a szervereken, a felhőalapú tárolókban vagy a végponti eszközökön nyugvó adatokat.
- Felhasználói viselkedéselemzés – létrehozza az adathozzáférési viselkedés alapvonalait, gépi tanulást használ a rendellenes és potenciálisan kockázatos tevékenységek észlelésére és riasztására.
- Adatok feltárása és osztályozása – feltárja az adatok helyét, mennyiségét és kontextusát helyben és a felhőben.
- Adatbázis-aktivitásfigyelés-ellenőrzi a relációs adatbázisokat, adattárházakat, big data-t és nagyszámítógépeket, hogy valós idejű riasztásokat generáljon a házirend megsértéséről.
- Riasztási prioritás-az Imperva AI és gépi tanulási technológiát használ a biztonsági események folyamának áttekintésére és a legfontosabbak priorizálására.
Leave a Reply