Grid Search für die Modellabstimmung
Ein Modell-Hyperparameter ist eine Eigenschaft eines Modells, die außerhalb des Modells liegt und deren Wert nicht aus Daten geschätzt werden kann. Der Wert des Hyperparameters muss festgelegt werden, bevor der Lernprozess beginnt. Zum Beispiel c in Support Vector Machines, k in k-Nearest Neighbors, die Anzahl der versteckten Schichten in Neuronalen Netzen.
Im Gegensatz dazu ist ein Parameter ein internes Merkmal des Modells und sein Wert kann aus Daten geschätzt werden. Beispiel: Beta-Koeffizienten der linearen/logistischen Regression oder Support-Vektoren in Support Vector Machines.
Grid-Search wird verwendet, um die optimalen Hyperparameter eines Modells zu finden, die zu den „genauesten“ Vorhersagen führen.
Lassen Sie uns Grid-Search anhand der Erstellung eines Klassifizierungsmodells für den Brustkrebs-Datensatz untersuchen.
Importieren Sie den Datensatz und zeigen Sie die ersten 10 Zeilen an.
Ausgabe:

Jede Zeile im Datensatz hat eine von zwei möglichen Klassen: gutartig (dargestellt durch 2) und bösartig (dargestellt durch 4). Außerdem gibt es 10 Attribute in diesem Datensatz (siehe oben), die für die Vorhersage verwendet werden, mit Ausnahme der Probencode-Nummer, die die Identifikationsnummer ist.
Bereinigen Sie die Daten und benennen Sie die Klassenwerte für die Modellerstellung in 0/1 um (wobei 1 für einen bösartigen Fall steht). Betrachten wir auch die Verteilung der Klasse.
Ausgabe:

Es gibt 444 gutartige und 239 bösartige Fälle.
Ausgabe :
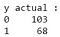
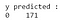
Aus der Ausgabe können wir erkennen, dass es 68 bösartige und 103 gutartige Fälle im Testdatensatz gibt. Unser Klassifikator sagt jedoch alle Fälle als gutartig voraus (da dies die Mehrheitsklasse ist).
Berechnen Sie die Bewertungsmetriken dieses Modells.
Ausgabe :
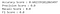

Die Genauigkeit des Modells beträgt 60.2 %, aber dies ist ein Fall, in dem die Genauigkeit möglicherweise nicht die beste Metrik zur Bewertung des Modells ist. Werfen wir also einen Blick auf die anderen Bewertungsmetriken.

Die obige Abbildung zeigt die Konfusionsmatrix, die zur besseren Veranschaulichung mit Beschriftungen und Farben versehen wurde (den Code zur Erstellung dieser Matrix finden Sie hier). Die Konfusionsmatrix lässt sich wie folgt zusammenfassen: WAHR-POSITIVE ERGEBNISSE (TP) = 0, WAHR-NEGATIVE ERGEBNISSE (TN) = 103, FALSCH-POSITIVE ERGEBNISSE (FP) = 0, FALSCH-NEGATIVE ERGEBNISSE (FN) = 68. Die Formeln für die Bewertungsmetriken lauten wie folgt:

Da das Modell keinen bösartigen Fall richtig klassifiziert, sind die Metriken für Recall und Precision 0.
Nun, da wir die Basisgenauigkeit haben, erstellen wir ein logistisches Regressionsmodell mit Standardparametern und bewerten das Modell.
Output :

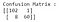
Durch die Anpassung des logistischen Regressionsmodells mit den Standardparametern haben wir ein viel „besseres“ Modell. Die Genauigkeit liegt bei 94,7 % und gleichzeitig beträgt die Präzision erstaunliche 98,3 %. Werfen wir nun einen Blick auf die Konfusionsmatrix für die Ergebnisse dieses Modells:

Bei der Betrachtung der falsch klassifizierten Instanzen können wir feststellen, dass 8 bösartige Fälle fälschlicherweise als gutartig klassifiziert wurden (falsch negativ). Außerdem wurde nur ein gutartiger Fall als bösartig eingestuft (falsch positiv).
Ein falsch negativer Fall ist schwerwiegender, da eine Krankheit übersehen wurde, was zum Tod des Patienten führen kann. Gleichzeitig würde ein falsches Positiv zu einer unnötigen Behandlung führen, die zusätzliche Kosten verursacht.
Versuchen wir, die falsch-negativen Ergebnisse zu minimieren, indem wir die Gittersuche verwenden, um die optimalen Parameter zu finden. Die Rastersuche kann verwendet werden, um eine bestimmte Bewertungskennzahl zu verbessern.
Die Kennzahl, auf die wir uns konzentrieren müssen, um falsch-negative Ergebnisse zu reduzieren, ist Recall.
Grid Search zur Maximierung des Recall
Output :


Die von uns abgestimmten Hyperparameter sind:
- Strafe: l1 oder l2, welche Art von Norm für die Bestrafung verwendet wird.
- C: Inverse der Regularisierungsstärke – kleinere Werte von C spezifizieren eine stärkere Regularisierung.
Auch in der Grid-Suchfunktion gibt es den Scoring-Parameter, mit dem wir die Metrik angeben können, nach der das Modell bewertet werden soll (wir haben Recall als Metrik gewählt). Aus der nachstehenden Konfusionsmatrix geht hervor, dass die Anzahl der falsch-negativen Ergebnisse gesunken ist, allerdings auf Kosten einer Zunahme der falsch-positiven Ergebnisse. Der Recall nach der Rastersuche ist von 88,2 % auf 91,1 % gestiegen, während die Präzision von 98,3 % auf 87,3 % gesunken ist.

Sie können das Modell weiter abstimmen, um ein Gleichgewicht zwischen Präzision und Recall zu erreichen, indem Sie den „f1“-Score als Bewertungsmetrik verwenden. In diesem Artikel finden Sie ein besseres Verständnis der Bewertungsmetriken.
Die Gittersuche erstellt ein Modell für jede angegebene Kombination von Hyperparametern und wertet jedes Modell aus. Eine effizientere Technik für die Abstimmung von Hyperparametern ist die randomisierte Suche, bei der zufällige Kombinationen von Hyperparametern verwendet werden, um die beste Lösung zu finden.
Leave a Reply