Masquage de données
Qu’est-ce que le masquage de données ?
Le masquage de données est un moyen de créer une version fausse, mais réaliste, de vos données organisationnelles. L’objectif est de protéger les données sensibles, tout en fournissant une alternative fonctionnelle lorsque les données réelles ne sont pas nécessaires – par exemple, dans la formation des utilisateurs, les démonstrations de vente ou les tests de logiciels.
Les processus de masquage des données modifient les valeurs des données tout en utilisant le même format. L’objectif est de créer une version qui ne peut pas être déchiffrée ou faire l’objet d’une ingénierie inverse. Il existe plusieurs façons de modifier les données, notamment le mélange de caractères, la substitution de mots ou de caractères et le cryptage.
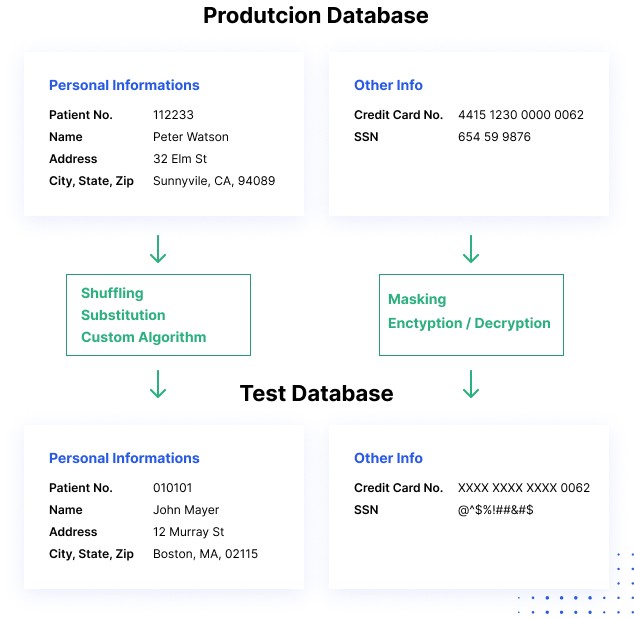
Comment fonctionne le masquage des données
Pourquoi le masquage des données est-il important ?
Voici plusieurs raisons pour lesquelles le masquage des données est essentiel pour de nombreuses organisations :
- Le masquage des données résout plusieurs menaces critiques – perte de données, exfiltration de données, menaces d’initiés ou compromission de comptes, et interfaces non sécurisées avec des systèmes tiers.
- Réduit les risques de données associés à l’adoption du cloud.
- Rend les données inutiles pour un attaquant, tout en conservant bon nombre de leurs propriétés fonctionnelles inhérentes.
- Permet de partager des données avec des utilisateurs autorisés, tels que des testeurs et des développeurs, sans exposer les données de production.
- Peut être utilisé pour la désinfection des données – la suppression normale des fichiers laisse encore des traces de données sur les supports de stockage, tandis que la désinfection remplace les anciennes valeurs par des valeurs masquées.
Types de masquage des données
Il existe plusieurs types de masquage des données couramment utilisés pour sécuriser les données sensibles.
Masquage statique des données
Les processus de masquage statique des données peuvent vous aider à créer une copie aseptisée de la base de données. Le processus modifie toutes les données sensibles jusqu’à ce qu’une copie de la base de données puisse être partagée en toute sécurité. En général, le processus consiste à créer une copie de sauvegarde d’une base de données en production, à la charger dans un environnement séparé, à éliminer toutes les données inutiles, puis à masquer les données pendant qu’elles sont en stase. La copie masquée peut ensuite être poussée vers l’emplacement cible.
Masquage déterministe des données
Implique de mettre en correspondance deux ensembles de données qui ont le même type de données, de telle sorte qu’une valeur est toujours remplacée par une autre valeur. Par exemple, le nom « John Smith » est toujours remplacé par « Jim Jameson », partout où il apparaît dans une base de données. Cette méthode est pratique pour de nombreux scénarios, mais elle est intrinsèquement moins sûre.
Masquage des données à la volée
Masquage des données pendant leur transfert des systèmes de production vers les systèmes de test ou de développement, avant que les données ne soient enregistrées sur le disque. Les organisations qui déploient fréquemment des logiciels ne peuvent pas créer une copie de sauvegarde de la base de données source et appliquer le masquage – elles ont besoin d’un moyen de diffuser en continu les données de la production vers plusieurs environnements de test.
À la volée, le masquage envoie des sous-ensembles plus petits de données masquées lorsqu’elles sont nécessaires. Chaque sous-ensemble de données masquées est stocké dans l’environnement de dev/test pour être utilisé par le système hors production.
Il est important d’appliquer le masquage à la volée à toute alimentation d’un système de production vers un environnement de développement, au tout début d’un projet de développement, pour prévenir les problèmes de conformité et de sécurité.
Masquage dynamique des données
Similaire au masquage à la volée, mais les données ne sont jamais stockées dans un magasin de données secondaire dans l’environnement de dev/test. Elles sont plutôt diffusées directement à partir du système de production et consommées par un autre système dans l’environnement dev/test.
Techniques de masquage des données
Examinons quelques façons courantes dont les organisations appliquent le masquage aux données sensibles. Lors de la protection des données, les professionnels de l’informatique peuvent utiliser une variété de techniques.
Cryptage des données
Lorsque les données sont cryptées, elles deviennent inutiles à moins que le spectateur ne dispose de la clé de décryptage. Essentiellement, les données sont masquées par l’algorithme de cryptage. Il s’agit de la forme la plus sûre de masquage des données, mais elle est également complexe à mettre en œuvre car elle nécessite une technologie pour effectuer un chiffrement continu des données, ainsi que des mécanismes pour gérer et partager les clés de chiffrement
Brouillage des données
Les caractères sont réorganisés dans un ordre aléatoire, remplaçant le contenu original. Par exemple, un numéro d’identification tel que 76498 dans une base de données de production, pourrait être remplacé par 84967 dans une base de données de test. Cette méthode est très simple à mettre en œuvre, mais ne peut être appliquée qu’à certains types de données, et est moins sécurisée.
Nulling Out
Les données apparaissent manquantes ou « nulles » lorsqu’elles sont visualisées par un utilisateur non autorisé. Cela rend les données moins utiles à des fins de développement et de test.
Value Variance
Les valeurs originales des données sont remplacées par une fonction, telle que la différence entre la valeur la plus basse et la plus haute d’une série. Par exemple, si un client a acheté plusieurs produits, le prix d’achat peut être remplacé par une fourchette entre le prix payé le plus élevé et le plus bas. Cela peut fournir des données utiles à de nombreuses fins, sans divulguer l’ensemble de données original.
Substitution de données
Les valeurs des données sont substituées par des valeurs alternatives fausses, mais réalistes. Par exemple, les noms réels des clients sont remplacés par une sélection aléatoire de noms provenant d’un annuaire téléphonique.
Mélange de données
Similaire à la substitution, sauf que les valeurs des données sont permutées dans le même ensemble de données. Les données sont réorganisées dans chaque colonne à l’aide d’une séquence aléatoire ; par exemple, la commutation entre les noms réels des clients sur plusieurs enregistrements de clients. L’ensemble de sortie ressemble à des données réelles, mais il ne montre pas les informations réelles pour chaque individu ou enregistrement de données.
Pseudonymisation
Selon le Règlement général sur la protection des données (RGPD) de l’UE, un nouveau terme a été introduit pour couvrir des processus comme le masquage des données, le cryptage et le hachage pour protéger les données personnelles : la pseudonymisation.
La pseudonymisation, telle que définie dans le RGPD, est toute méthode qui garantit que les données ne peuvent pas être utilisées pour l’identification personnelle. Elle nécessite de supprimer les identifiants directs et, de préférence, d’éviter les identifiants multiples qui, lorsqu’ils sont combinés, peuvent identifier une personne.
En outre, les clés de chiffrement, ou d’autres données qui peuvent être utilisées pour revenir aux valeurs initiales des données, doivent être stockées séparément et en toute sécurité.
Bonnes pratiques de masquage des données
Déterminer la portée du projet
Pour effectuer efficacement le masquage des données, les entreprises doivent savoir quelles informations doivent être protégées, qui est autorisé à les voir, quelles applications utilisent les données et où elles résident, à la fois dans les domaines de production et de non-production. Bien que cela puisse sembler facile sur le papier, en raison de la complexité des opérations et des multiples lignes d’affaires, ce processus peut exiger un effort substantiel et doit être planifié comme une étape distincte du projet.
Assurer l’intégrité référentielle
L’intégrité référentielle signifie que chaque « type » d’information provenant d’une application d’affaires doit être masqué en utilisant le même algorithme.
Dans les grandes organisations, un seul outil de masquage des données utilisé dans toute l’entreprise n’est pas réalisable. Chaque ligne d’activité peut être amenée à mettre en œuvre son propre masquage des données en raison des exigences budgétaires/business, des différentes pratiques d’administration informatique ou des différentes exigences de sécurité/réglementaires.
Assurez-vous que les différents outils et pratiques de masquage des données dans l’ensemble de l’organisation sont synchronisés, lorsqu’ils traitent le même type de données. Cela permettra d’éviter des difficultés ultérieures lorsque les données doivent être utilisées dans plusieurs secteurs d’activité.
Sécuriser les algorithmes de masquage des données
Il est essentiel de considérer comment protéger les algorithmes de fabrication des données, ainsi que les ensembles de données ou dictionnaires alternatifs utilisés pour brouiller les données. Comme seuls les utilisateurs autorisés doivent avoir accès aux données réelles, ces algorithmes doivent être considérés comme extrêmement sensibles. Si quelqu’un apprend quels algorithmes de masquage répétables sont utilisés, il peut faire de l’ingénierie inverse sur de grands blocs d’informations sensibles.
Une meilleure pratique de masquage des données, qui est explicitement requise par certaines réglementations, consiste à assurer la séparation des tâches. Par exemple, le personnel de la sécurité informatique détermine les méthodes et les algorithmes qui seront utilisés en général, mais les paramètres spécifiques des algorithmes et les listes de données ne devraient être accessibles que par les propriétaires des données dans le département concerné.
Masquage des données avec Imperva
Imperva est une solution de sécurité qui fournit des capacités de masquage et de chiffrement des données, vous permettant d’obfusquer les données sensibles afin qu’elles soient inutiles pour un attaquant, même si elles sont extraites d’une manière ou d’une autre.
En plus de fournir le masquage des données, la solution de sécurité des données d’Imperva protège vos données où qu’elles se trouvent – dans les locaux, dans le cloud et dans les environnements hybrides. Elle fournit également aux équipes de sécurité et d’informatique une visibilité complète sur la façon dont les données sont accédées, utilisées et déplacées dans l’organisation.
Notre approche globale repose sur plusieurs couches de protection, notamment :
- Le pare-feu de base de données bloque l’injection SQL et d’autres menaces, tout en évaluant les vulnérabilités connues.
- Gestion des droits des utilisateurs – surveille l’accès aux données et les activités des utilisateurs privilégiés pour identifier les privilèges excessifs, inappropriés et inutilisés.
- Prévention des pertes de données (DLP) – inspecte les données en mouvement, au repos sur les serveurs, dans le stockage en nuage ou sur les appareils d’extrémité.
- Analyse du comportement des utilisateurs – établit des lignes de base du comportement d’accès aux données, utilise l’apprentissage automatique pour détecter et alerter sur les activités anormales et potentiellement risquées.
- Découverte et classification des données – révèle l’emplacement, le volume et le contexte des données sur site et dans le cloud.
- Surveillance de l’activité des bases de données-surveille les bases de données relationnelles, les entrepôts de données, le big data et les mainframes pour générer des alertes en temps réel sur les violations des politiques.
- Hiérarchisation des alertes-Imperva utilise l’IA et la technologie d’apprentissage automatique pour examiner le flux des événements de sécurité et hiérarchiser ceux qui comptent le plus.
Leave a Reply