Datan peittäminen
Mitä on datan peittäminen?
Datan peittäminen on tapa luoda väärennetty, mutta realistinen versio organisaation tiedoista. Tavoitteena on suojata arkaluonteisia tietoja ja tarjota samalla toimiva vaihtoehto silloin, kun todellisia tietoja ei tarvita – esimerkiksi käyttäjäkoulutuksessa, myyntidemonstraatioissa tai ohjelmistotestauksessa.
Datan maskeerausprosessit muuttavat datan arvoja käyttäen kuitenkin samaa muotoa. Tavoitteena on luoda versio, jota ei voida tulkita tai purkaa. Tietoa voidaan muuttaa useilla eri tavoilla, kuten merkkien sekoittamisella, sanojen tai merkkien korvaamisella ja salaamisella.
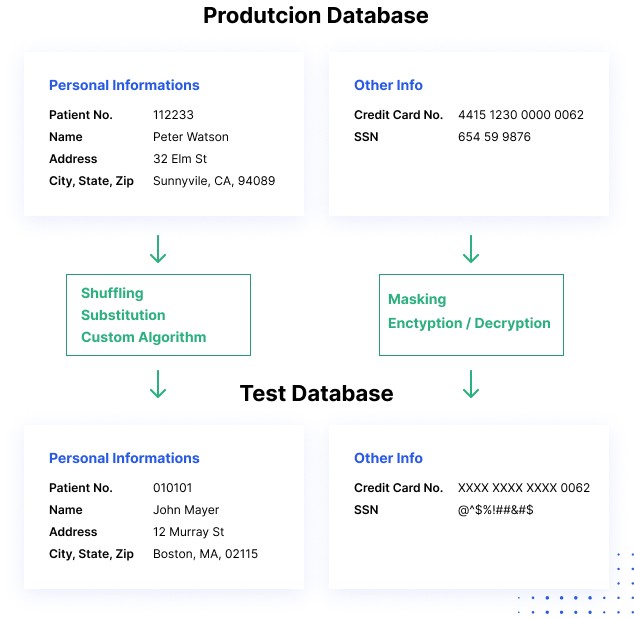
Miten datan peittäminen toimii
Miksi datan peittäminen on tärkeää?
Tässä on useita syitä siihen, miksi tietojen peittäminen on tärkeää monille organisaatioille:
- Tietojen peittäminen ratkaisee useita kriittisiä uhkia – tietojen häviäminen, tietojen poistaminen, sisäpiirin uhat tai tilien vaarantaminen sekä turvattomat liitännät kolmansien osapuolten järjestelmiin.
- Vähentää pilvipalvelun käyttöönotosta aiheutuvia tietoriskejä.
- Tekee tiedoista hyödyttömiä hyökkääjälle säilyttäen samalla monet niille ominaiset toiminnalliset ominaisuudet.
- Mahdollistaa tietojen jakamisen valtuutetuille käyttäjille, kuten testaajille ja kehittäjille, paljastamatta tuotantotietoja.
- Voidaan käyttää datan puhdistusmenetelmää – normaali tiedostojen poisto jättää edelleen jälkiä tiedoista tallennusvälineisiin, kun taas puhdistusmenetelmällä korvataan vanhat arvot peitetyillä.
Datan maskeeraustyypit
Tietojen maskeeraustyyppejä, joita käytetään yleisesti arkaluonteisten tietojen suojaamiseen, on useita.
Stattinen datan maskeeraus
Stattiset datan maskeerausprosessit voivat auttaa luomaan tietokannasta sanitoidun kopion. Prosessi muuttaa kaikkia arkaluonteisia tietoja, kunnes tietokannan kopio voidaan jakaa turvallisesti. Tyypillisesti prosessissa luodaan varmuuskopio tuotannossa olevasta tietokannasta, ladataan se erilliseen ympäristöön, poistetaan kaikki tarpeettomat tiedot ja maskataan tiedot sen jälkeen, kun ne ovat pysähdyksissä. Maskeerattu kopio voidaan sitten työntää kohdepaikkaan.
Deterministinen datan maskeeraus
Sisältää kahden samantyyppisen datajoukon yhdistämisen siten, että yksi arvo korvataan aina toisella arvolla. Esimerkiksi nimi ”John Smith” korvataan aina nimellä ”Jim Jameson” kaikkialla, missä se esiintyy tietokannassa. Tämä menetelmä on kätevä monissa skenaarioissa, mutta se on luonnostaan vähemmän turvallinen.
Tietojen peittäminen lennossa
Tietojen peittäminen, kun niitä siirretään tuotantojärjestelmistä testi- tai kehitysjärjestelmiin ennen kuin tiedot tallennetaan levylle. Organisaatiot, jotka ottavat ohjelmistoja käyttöön usein, eivät voi luoda varmuuskopiota lähdetietokannasta ja soveltaa peittämistä – ne tarvitsevat tavan, jolla tiedot voidaan jatkuvasti siirtää tuotannosta useisiin testiympäristöihin.
Käynnissä tapahtuva peittäminen lähettää pienempiä osajoukkoja peitetyistä tiedoista silloin, kun niitä tarvitaan. Kukin naamioidun datan osajoukko tallennetaan kehitys- tai testiympäristöön, jotta sitä voidaan käyttää muussa kuin tuotantojärjestelmässä.
On tärkeää soveltaa lennossa tapahtuvaa naamiointia mihin tahansa syötteeseen tuotantojärjestelmästä kehitysympäristöön heti kehitysprojektin alussa vaatimustenmukaisuus- ja tietoturvaongelmien välttämiseksi.
Dynaaminen datan naamiointi
Samankaltainen kuin lennossa tapahtuva naamiointi, mutta dataa ei koskaan tallenneta toissijaiseen tietovarastoon kehitys- tai testiympäristössä. Sen sijaan se suoratoistetaan suoraan tuotantojärjestelmästä ja kulutetaan toisessa dev/testausympäristön järjestelmässä.
Datan peittämistekniikat
Katsotaanpa muutamia yleisiä tapoja, joilla organisaatiot soveltavat peittämistä arkaluonteisiin tietoihin. Tietojen suojaamisessa IT-ammattilaiset voivat käyttää erilaisia tekniikoita.
Datan salaus
Kun tiedot salataan, niistä tulee käyttökelvottomia, ellei katsojalla ole salauksen purkuavainta. Pohjimmiltaan tiedot peitetään salausalgoritmilla. Tämä on datan peittämisen turvallisin muoto, mutta se on myös monimutkainen toteuttaa, koska se edellyttää tekniikkaa, jolla suoritetaan jatkuva datan salaus, sekä mekanismeja salausavainten hallintaan ja jakamiseen
Datan sekoittaminen
Merkit järjestetään uudelleen satunnaisessa järjestyksessä korvaten alkuperäisen sisällön. Esimerkiksi tuotantotietokannan tunnusnumero, kuten 76498, voidaan korvata testitietokannassa numerolla 84967. Tämä menetelmä on hyvin yksinkertainen toteuttaa, mutta sitä voidaan soveltaa vain joihinkin tietotyyppeihin, ja se on vähemmän turvallinen.
Nulling Out
Tieto näyttää puuttuvalta tai ”nollatulta”, kun sitä tarkastelee luvaton käyttäjä. Tämä tekee tiedoista vähemmän käyttökelpoisia kehitys- ja testaustarkoituksiin.
Arvon varianssi
Alkuperäiset data-arvot korvataan funktiolla, kuten sarjan pienimmän ja suurimman arvon erotuksella. Jos esimerkiksi asiakas on ostanut useita tuotteita, ostohinta voidaan korvata korkeimman ja alhaisimman maksetun hinnan välisellä vaihteluvälillä. Näin voidaan tuottaa käyttökelpoista tietoa moniin tarkoituksiin paljastamatta alkuperäistä tietokokonaisuutta.
Datan korvaaminen
Data-arvot korvataan väärennetyillä, mutta realistisilla vaihtoehtoisilla arvoilla. Esimerkiksi todelliset asiakkaiden nimet korvataan satunnaisella nimivalinnalla puhelinluettelosta.
Datan sekoittaminen
Samankaltainen kuin korvaaminen, paitsi että data-arvot vaihdetaan saman tietokokonaisuuden sisällä. Tiedot järjestetään uudelleen kussakin sarakkeessa käyttäen satunnaista järjestystä; esimerkiksi vaihtamalla todellisia asiakkaiden nimiä useiden asiakastietueiden välillä. Tulostusjoukko näyttää oikeilta tiedoilta, mutta se ei näytä todellisia tietoja kustakin yksilöstä tai tietueesta.
Pseudonymisointi
EU:n yleisen tietosuoja-asetuksen (General Data Protection Regulation, GDPR) mukaan on otettu käyttöön uusi termi, joka kattaa prosessit, kuten tietojen peittämisen, salauksen ja hashauksen, henkilötietojen suojaamiseksi: pseudonymisointi.
Pseudonymisointi on yleisen tietosuoja-asetuksen määritelmän mukaan mitä tahansa menetelmää, jolla taataan, että tietoja ei voida käyttää henkilökohtaiseen tunnistamiseen. Se edellyttää suorien tunnisteiden poistamista ja mieluiten sellaisten useiden tunnisteiden välttämistä, jotka yhdistettyinä voivat tunnistaa henkilön.
Lisäksi salausavaimet tai muut tiedot, joita voidaan käyttää tietojen alkuperäisten arvojen palauttamiseen, olisi säilytettävä erikseen ja turvallisesti.
Datan peittämisen parhaat käytännöt
Projektin laajuuden määrittäminen
Tehokasta datan peittämistä varten yritysten on tiedettävä, mitä tietoja on suojattava, kenellä on oikeus nähdä ne, mitkä sovellukset käyttävät tietoja ja missä ne sijaitsevat sekä tuotanto- että muissa kuin tuotantotunnuksissa. Vaikka tämä saattaa vaikuttaa paperilla helpolta, toimintojen monimutkaisuuden ja useiden toimialojen vuoksi tämä prosessi voi vaatia huomattavia ponnistuksia, ja se on suunniteltava projektin erilliseksi vaiheeksi.
Viittauksellisen eheyden varmistaminen
Viittauksellinen eheys tarkoittaa sitä, että jokainen liiketoimintasovelluksesta tuleva ”tietotyyppi” on peitettävä samalla algoritmilla.
Suurissa organisaatioissa yksi ainoa datan peittämistyökalu, jota käytettäisiin koko yrityksessä, ei ole toteutettavissa. Kullakin toimialalla saatetaan joutua toteuttamaan oma tietojen peittäminen budjetin/liiketoimintavaatimusten, erilaisten IT-hallintakäytäntöjen tai erilaisten tietoturva-/sääntelyvaatimusten vuoksi.
Varmista, että erilaiset tietojen peittämistyökalut ja -käytännöt eri puolilla organisaatiota synkronoidaan, kun käsitellään samantyyppisiä tietoja. Näin vältytään myöhemmiltä haasteilta, kun tietoja joudutaan käyttämään eri liiketoimintalinjoilla.
Tietojen peittoalgoritmien suojaaminen
On ratkaisevan tärkeää miettiä, miten suojataan tietojen tekemiseen käytettävät algoritmit sekä vaihtoehtoiset tietokokonaisuudet tai sanakirjat, joita käytetään tietojen sekoittamiseen. Koska vain valtuutetuilla käyttäjillä pitäisi olla pääsy todellisiin tietoihin, näitä algoritmeja olisi pidettävä erittäin arkaluonteisina. Jos joku saa selville, mitä toistettavia peittelyalgoritmeja käytetään, hän voi käänteiskehittää suuria arkaluonteisia tietolohkoja.
Tietojen peittämisen paras käytäntö, jota joissakin säädöksissä nimenomaisesti edellytetään, on varmistaa tehtävien erottaminen. Esimerkiksi tietoturvahenkilöstö määrittelee, mitä menetelmiä ja algoritmeja yleisesti käytetään, mutta erityiset algoritmiasetukset ja tietoluettelot pitäisi olla vain asianomaisen osaston tietojen omistajien saatavilla.
Datan peittäminen Impervalla
Imperva on tietoturvaratkaisu, joka tarjoaa datan peittämis- ja salausominaisuuksia, joiden avulla arkaluonteiset tiedot voidaan peittää niin, että ne olisivat hyödyttömiä hyökkääjälle, vaikka ne jotenkin poimittaisiinkin pois.
Datan peittämisen lisäksi Impervan tietoturvaratkaisu suojaa tietojasi riippumatta siitä, missä ne sijaitsevat – toimitiloissa, pilvipalvelussa ja hybridiympäristöissä. Se tarjoaa myös tietoturva- ja IT-tiimeille täyden näkyvyyden siitä, miten tietoja käytetään, käytetään ja siirretään organisaatiossa.
Kokonaisvaltainen lähestymistapamme perustuu useisiin suojauskerroksiin, kuten:
- Tietokantojen palomuuri estää SQL-injektiot ja muut uhat ja arvioi samalla tunnetut haavoittuvuudet.
- Käyttäjäoikeuksien hallinta – valvoo etuoikeutettujen käyttäjien tietoihin pääsyä ja toimintoja, jotta tunnistetaan liialliset, sopimattomat ja käyttämättömät oikeudet.
- Tietojen katoamisen esto (DLP) – tarkastaa tiedot liikkeessä, levossa palvelimilla, pilvitallennustiloissa tai päätelaitteissa.
- Käyttäjäkäyttäytymisen analytiikka – luo datan käyttökäyttäytymisen peruslinjat, käyttää koneoppimista havaitakseen ja varoittaakseen epänormaalista ja potentiaalisesti riskialttiista toiminnasta.
- Datan havaitseminen ja luokittelu – paljastaa tiloissa ja pilvipalvelussa olevan datan sijainnin, määrän ja asiayhteyden.
- Tietokantojen toiminnan valvonta – valvoo relaatiotietokantoja, tietovarastoja, big dataa ja suurtietokoneita tuottaakseen reaaliaikaisia hälytyksiä käytäntöjen rikkomisesta.
- Hälytysten priorisointi – Imperva käyttää tekoäly- ja koneoppimisteknologiaa tarkastellakseen tietoturvatapahtumien virtaa ja priorisoidakseen ne, joilla on eniten merkitystä.
Leave a Reply